一种基于人工智能的行为识别方法及系统与流程
本发明属于智能识别的,具体地涉及一种基于人工智能的行为识别方法及系统。
背景技术:
1、在目前的人工智能领域,智能识别技术被广泛应用于各行各界,同时智能行为识别技术监控系统软件是一种以行为识别技术为关键技术的深度学习算法,根据人工智能化神经元网络,构造大家的主要模块架构,依据轨迹、目标人体轮廓测算各种各样健身运动行为,同时通过行为识别技术监控拍照的各类现场作业人员的异常行为,帮助监控工作人员提高解决各类出现异常紧急事件的效率;
2、在现有技术中,通常通过手工提取目标特征并通过研究人员观察进而区别不同行为的特征进行表达,其存在特征表示不全、噪声过大的问题,同时现有技术在识别到目标特征后,会存在较大的识别误差,导致其无法实现目标行为的准确识别。
技术实现思路
1、为了解决上述技术问题,本发明提供了一种基于人工智能的行为识别方法及系统,用于解决现有技术中的技术问题。
2、一方面,本发明提供以下技术方案,一种基于人工智能的行为识别方法,包括:
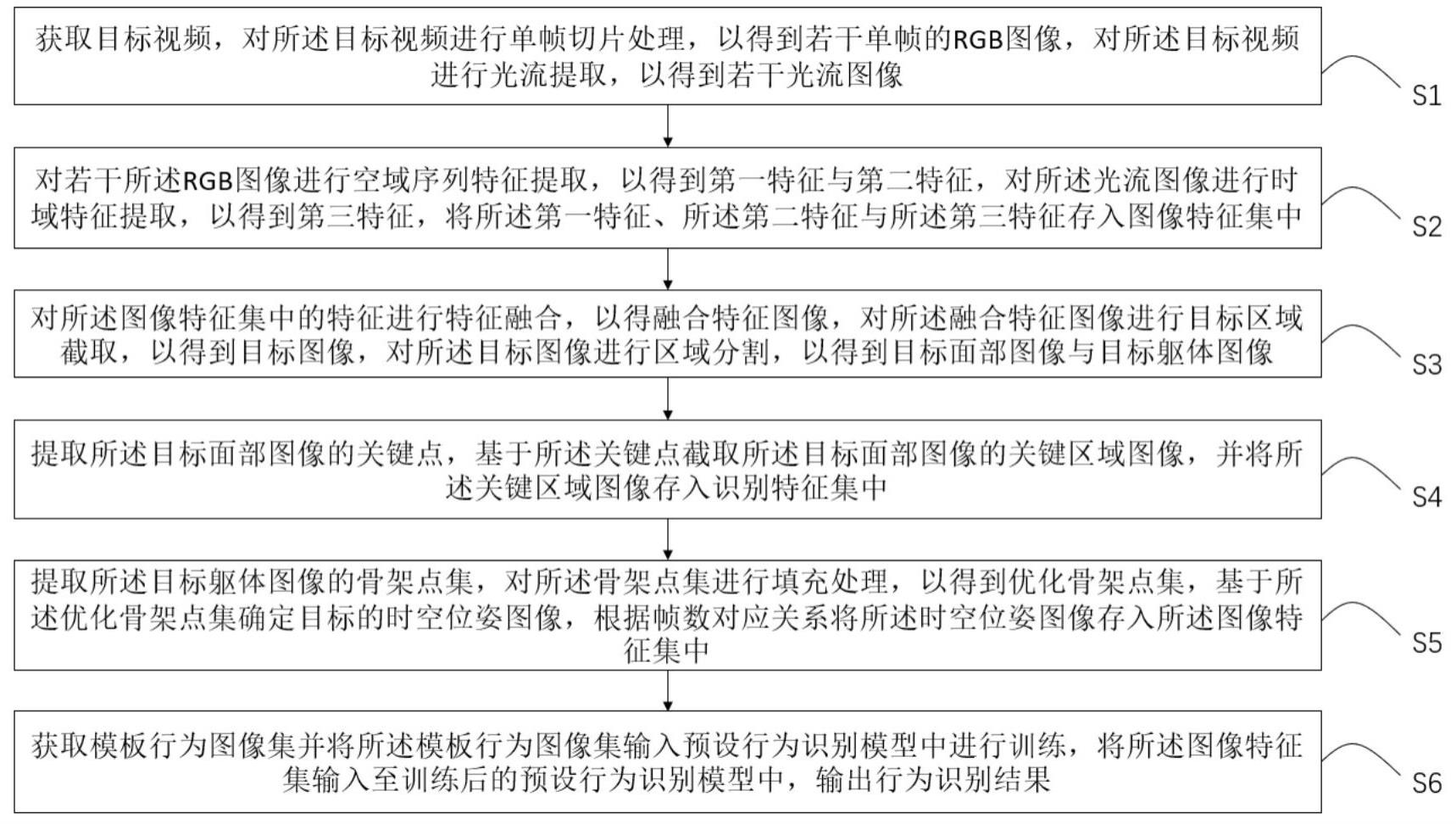
3、获取目标视频,对所述目标视频进行单帧切片处理,以得到若干单帧的rgb图像,对所述目标视频进行光流提取,以得到若干光流图像;
4、对若干所述rgb图像进行空域序列特征提取,以得到第一特征与第二特征,对所述光流图像进行时域特征提取,以得到第三特征,将所述第一特征、所述第二特征与所述第三特征存入图像特征集中;
5、对所述图像特征集中的特征进行特征融合,以得融合特征图像,对所述融合特征图像进行目标区域截取,以得到目标图像,对所述目标图像进行区域分割,以得到目标面部图像与目标躯体图像;
6、提取所述目标面部图像的关键点,基于所述关键点截取所述目标面部图像的关键区域图像,并将所述关键区域图像存入识别特征集中;
7、提取所述目标躯体图像的骨架点集,对所述骨架点集进行填充处理,以得到优化骨架点集,基于所述优化骨架点集确定目标的时空位姿图像,根据帧数对应关系将所述时空位姿图像存入所述图像特征集中;
8、获取模板行为图像集并将所述模板行为图像集输入预设行为识别模型中进行训练,将所述图像特征集输入至训练后的预设行为识别模型中,输出行为识别结果。
9、相比现有技术,本技术的有益效果为:本技术首先获取目标视频,对目标视频进行单帧切片处理,以得到若干单帧的rgb图像,对目标视频进行光流提取,以得到若干光流图像;然后对若干rgb图像进行空域序列特征提取,以得到第一特征与第二特征,对光流图像进行时域特征提取,以得到第三特征,将第一特征、第二特征与第三特征存入图像特征集中;之后对图像特征集中的特征进行特征融合,以得融合特征图像,对融合特征图像进行目标区域截取,以得到目标图像,对目标图像进行区域分割,以得到目标面部图像与目标躯体图像;再之后提取目标面部图像的关键点,基于关键点截取目标面部图像的关键区域图像,并将关键区域图像存入识别特征集中;然后提取目标躯体图像的骨架点集,对骨架点集进行填充处理,以得到优化骨架点集,基于优化骨架点集确定目标的时空位姿图像,根据帧数对应关系将时空位姿图像存入图像特征集中;最后获取模板行为图像集并将模板行为图像集输入预设行为识别模型中进行训练,将图像特征集输入至训练后的预设行为识别模型中,输出行为识别结果,本发明首先提取了图像的三种特征分别为时间、空间与序列特征,以此可解决在智能识别真实环境下存在强外界干扰、强环境光遮蔽及其他干扰因素时模型存在泛化能力不足、鲁棒性不强等问题,同时结合目标的面部特征与驱干特征对目标行为进行分析,可提高目标行为识别分类的准确性,且本发明通过对目标的骨骼点进行填充优化,避免因骨骼点过少而导致目标姿态无法准确识别的问题,以此实现了目标行为识别的准确性同时也大幅度提升了目标识别的速度。
10、较佳的,所述对所述目标视频进行单帧切片处理,以得到若干单帧的rgb图像,对所述目标视频进行光流提取,以得到若干光流图像的步骤包括:
11、对所述目标视频进行单帧拆分与切片处理,以将所述目标视频拆分为若干连续的单帧的rgb图像;
12、提取所述目标视频的单帧空间图像,计算时刻对应的单帧空间图像的第一图像信息与时刻对应的单帧空间图像的第二图像信息:
13、;
14、;
15、式中,为图像的像素中心点,第一系数矩阵,为第二系数矩阵,为第三系数矩阵,为第四系数矩阵,、分别为第一标量与第二标量,为像素点的位移量;
16、判断时刻对应的单帧空间图像与时刻对应的单帧空间图像的像素值是否相同;
17、若时刻对应的单帧空间图像与时刻对应的单帧空间图像的像素值相同,则,,;
18、基于所述第一图像信息与所述第二图像信息求解像素点的位移量,基于每个像素点的位移量确定单帧空间图像的光流场信息,以得到若干光流图像,其中,像素点的位移量为:
19、。
20、较佳的,所述对若干所述rgb图像进行空域序列特征提取,以得到第一特征与第二特征,对所述光流图像进行时域特征提取,以得到第三特征的步骤包括:
21、将所述rgb图像输入第一2dcnn中进行空域特征提取,以得到第一特征;
22、获取所述rgb图像的图像路径与类别标签,将所述图像路径与所述类别标签存入csv文件中,将所述csv文件与所述rgb图像输入lstm中进行序列特征提取,以得到第二特征;
23、对所述光流图像进行二值化灰度处理,以得到光流灰度图像,采用稠密光流法计算所述光流灰度图像的第一光流场与第二光流场,将所述光流图像、所述第一光流场与所述第二光流场输入第二2dcnn中进行时域特征提取,以得到第三特征。
24、较佳的,所述提取所述目标面部图像的关键点,基于所述关键点截取所述目标面部图像的关键区域图像,并将所述关键区域图像存入识别特征集中的步骤包括:
25、将所述目标面部图像输入关键点提取网络中进行关键点提取,以得若干关键点,基于所述关键点确定面部关键点矩阵,基于所述面部关键点矩阵确定目标矩阵,其中,所述面部关键点矩阵与所述目标矩阵分别为:
26、;;
27、式中,为面部关键点矩阵中第行第列的元素,为面部关键点矩阵中第行第列的元素,为目标矩阵中第行第列的元素,为目标矩阵中第行第列的元素,为关键点个数;
28、基于所述面部关键点矩阵与所述目标矩阵计算中间矩阵:
29、;
30、;
31、式中,为第一正交矩阵,为第二正交矩阵,为奇异值分解;
32、基于所述中间矩阵确定转换矩阵,基于所述转换矩阵对所述面部关键点矩阵进行变换处理,以得到转换坐标矩阵:
33、;
34、式中,、分别为面部关键点矩阵中的第一列向量与第二列向量,、为目标矩阵中的第一列向量与第二列向量;
35、基于所述转换坐标矩阵截取所述目标面部图像的关键区域图像,并将所述关键区域图像存入识别特征集中。
36、较佳的,所述提取所述目标躯体图像的骨架点集,对所述骨架点集进行填充处理,以得到优化骨架点集的步骤包括:
37、将所述目标躯体图像输入骨架点预测网络中,以得到由若干初始骨架点;
38、获取所述骨架点的预测可靠度以及亲和场,对所述预测可靠度与所述亲和场进行迭代处理,以得到迭代可靠度与迭代亲和场:
39、;
40、;
41、式中,、分别为第一预测函数与第二预测函数,为图像连接特征映射,为第次迭代后的迭代可靠度,为第次迭代后的迭代亲和场;
42、基于第一损失函数与第二损失函数分别对所述迭代可靠度与所述迭代亲和场进行预测补偿,其中,所述第一损失函数与所述第二损失函数分别为:
43、;
44、;
45、式中,为骨架点在图像中的位置,为掩码,为第个阶段的迭代可靠度,为迭代可靠度的平均值,为第个阶段的迭代亲和场,为迭代亲和场的平均值,为阶段数,为2范数的平方;
46、基于预测补偿后的所述迭代可靠度与所述迭代亲和场对所述骨架点进行筛选,以得到骨架点集,并根据预设填充算法对所述骨架点集进行填充处理,以得到优化骨架点集。
47、较佳的,所述基于预测补偿后的所述迭代可靠度与所述迭代亲和场对所述骨架点进行筛选,以得到骨架点集,并根据预设填充算法对所述骨架点集进行填充处理,以得到优化骨架点集的步骤包括:
48、计算每个所述骨架点的可靠度与亲和场,将小于预测补偿后的所述迭代可靠度和/或所述迭代亲和场的骨架点进行剔除,将保留的骨架点存入骨架点集中;
49、剔除所述骨架点集中坐标为的骨架点,并在所述骨架点集中任意选取一基准骨架点,选取所述基准骨架点对应帧数前后各帧的骨架点,并将其存入填充数据集中;
50、基于所述填充数据集中各骨架点的坐标计算待填充骨架点的坐标值;
51、;
52、;
53、式中,为填充数据集中各骨架点x坐标值的样本均值,为填充数据集中各骨架点y坐标值的样本均值,为填充数据集中各骨架点x坐标值的样本中值,为填充数据集中各骨架点y坐标值的样本中值;
54、将所述待填充骨架点的坐标值补充至对应的填充数据集中,以得到优化骨架点集。
55、较佳的,所述基于所述优化骨架点集确定目标的时空位姿图像,根据帧数对应关系将所述时空位姿图像存入所述图像特征集中的步骤包括:
56、获取预设时间段内所述优化骨架点集中每个骨架点的坐标信息;
57、将基于每个骨架点的坐标信息将每个骨架点进行连接,以得到基础骨架位姿图像;
58、在所述基础骨架位姿图像中选取根骨架点,计算骨架点与所述根骨架点之间的最短距离,将最短距离不大于预设距离的骨架点存入采样骨架点集,基于预设采样函数对所述采样骨架点集中的骨架点进行采样处理,其中预设采样函数为:
59、;
60、式中,为采样骨架点集中除根骨架点外的其余骨架点,为根骨架点;
61、将采样处理得到的骨架点的相邻区域映射为个子区域:
62、;
63、式中,为映射函数,为采样处理得到的骨架点的相邻区域,为采样处理得到的骨架点;
64、基于映射结果确定更新骨架点,基于所述更新骨架点更新所述基础骨架位姿图像,以得到时空位姿图像,根据帧数对应关系将所述时空位姿图像存入所述图像特征集中,其中,所述更新骨架点为:
65、;
66、式中,为采样骨架点集中除根骨架点外的其余骨架点的映射结果,为当前骨架点在预设时间段内的时间位置,为预设时间段的起点时间位置。
67、第二方面,本发明提供以下技术方案,一种基于人工智能的行为识别系统,所述系统包括:
68、获取模块,用于获取目标视频,对所述目标视频进行单帧切片处理,以得到若干单帧的rgb图像,对所述目标视频进行光流提取,以得到若干光流图像;
69、提取模块,用于对若干所述rgb图像进行空域序列特征提取,以得到第一特征与第二特征,对所述光流图像进行时域特征提取,以得到第三特征,将所述第一特征、所述第二特征与所述第三特征存入图像特征集中;
70、融合模块,用于对所述图像特征集中的特征进行特征融合,以得融合特征图像,对所述融合特征图像进行目标区域截取,以得到目标图像,对所述目标图像进行区域分割,以得到目标面部图像与目标躯体图像;
71、截取模块,用于提取所述目标面部图像的关键点,基于所述关键点截取所述目标面部图像的关键区域图像,并将所述关键区域图像存入识别特征集中;
72、填充模块,用于提取所述目标躯体图像的骨架点集,对所述骨架点集进行填充处理,以得到优化骨架点集,基于所述优化骨架点集确定目标的时空位姿图像,根据帧数对应关系将所述时空位姿图像存入所述图像特征集中;
73、识别模块,用于获取模板行为图像集并将所述模板行为图像集输入预设行为识别模型中进行训练,将所述图像特征集输入至训练后的预设行为识别模型中,输出行为识别结果。
74、第三方面,本发明提供以下技术方案,一种计算机,包括存储器、处理器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述的基于人工智能的行为识别方法。
75、第四方面,本发明提供以下技术方案,一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述的基于人工智能的行为识别方法。
- 还没有人留言评论。精彩留言会获得点赞!