一种基于数据挖掘的异常光谱识别分析方法与流程
本发明涉及光谱数据处理,尤其涉及一种基于数据挖掘的异常光谱识别分析方法。
背景技术:
1、在线近红外广泛应用在烟叶生产过程中的各个环节,每个环节都会产生庞大的光谱数据,烟叶生产是一个复杂的过程包含有正常生产和非正常生产(外界环境的干扰、生产的故障、仪器的维修等),而近红外在这些过程中在连续不间断的采集光谱数据,导致产生的大量的没有任何价值或意义的数据,这些数据不仅没有提供任何有用的信息,用于做出任何结论或决策,并且这些数据的存在会对数据分析造成负面影响,影响数据分析结果的可信度和准确性,甚至导致作出错误的决策。
2、目前,在线近红外大多数采用人工手动删除数据或者数据收集到一定的程度,自动清除之前的数据,只保存一定时间内的数据,这样导致数据保存的时间过短,没有延续性,而且删除了有效光谱数据,造成很多有价值的数据信息丢失,严重的经济损失。大量无用的数据,不仅占据内存大,而且对实际数据分析没有任何贡献的同时造成数据污染,影响数据反映的真实性,不仅对仪器设备存储造成干扰,而且影响仪器的寿命和使用。
3、因此,亟需一种基于数据挖掘的异常光谱识别分析方法。
技术实现思路
1、本发明的目的是提供一种基于数据挖掘的异常光谱识别分析方法,以解决上述现有技术中的问题,能够在在线生产过程中建立一套异常识别机制,在剔除这些无效数据的同时,可以提高数据的准确性、可信度和实用性,从而促进有效数据的使用和价值的发挥,保障分析结果的可靠性和决策。
2、本发明提供了一种基于数据挖掘的异常光谱识别分析方法,其中,包括:
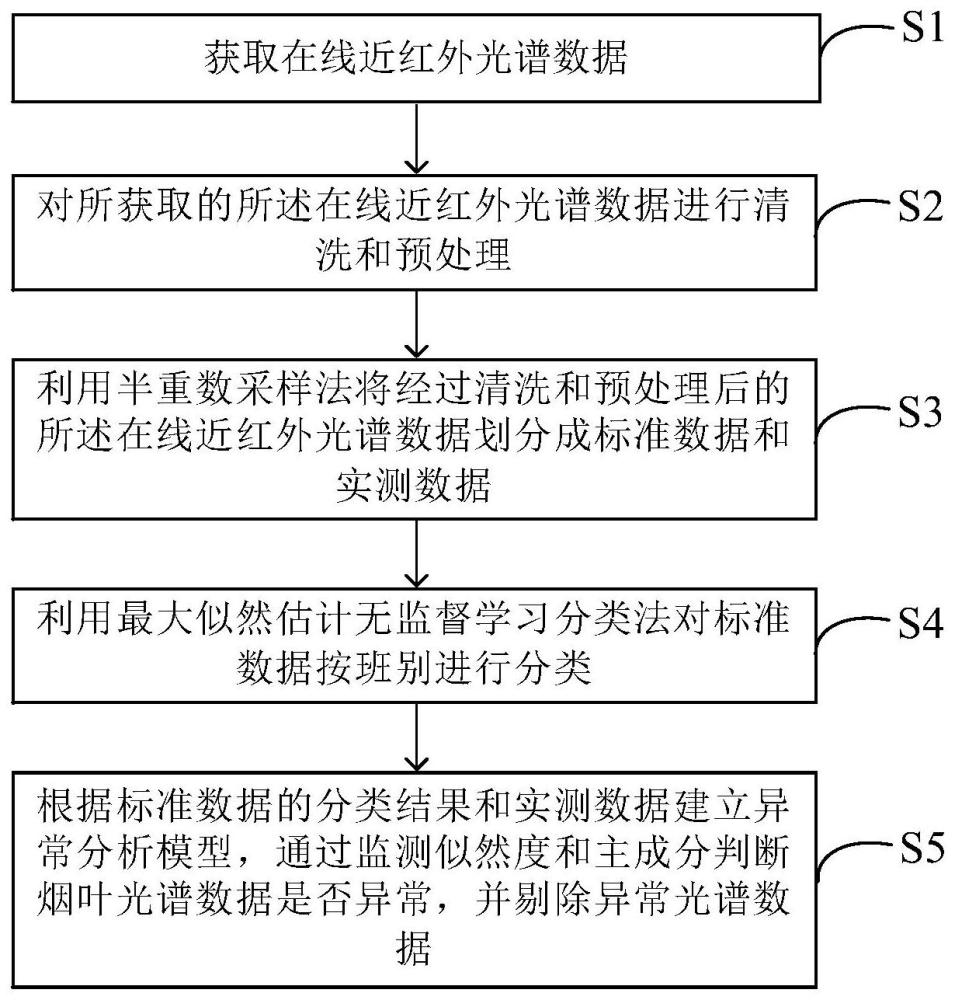
3、获取在线近红外光谱数据;
4、对所获取的所述在线近红外光谱数据进行清洗和预处理;
5、利用半重数采样法将经过清洗和预处理后的所述在线近红外光谱数据划分成标准数据和实测数据;
6、利用最大似然估计无监督学习分类法对标准数据按班别进行分类;
7、根据标准数据的分类结果和实测数据建立异常分析模型,通过监测似然度和主成分判断烟叶光谱数据是否异常,并剔除异常光谱数据。
8、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述在线近红外光谱数据包括一年四季不同外部环境生产下所收集的烟叶光谱、皮带光谱或半烟叶半皮带光谱。
9、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述对所获取的所述在线近红外光谱数据进行清洗和预处理,具体包括:
10、在所获取的所述在线近红外光谱数据中,剔除光谱吸光度大于0且小于0.5的数据,以剔除明显异常数据;
11、对剔除明显异常后的所有数据进行标准正态变量变换;
12、对标准正态变量变换后的光谱数据进行指数平滑化。
13、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述对剔除明显异常后的所有数据进行标准正态变量变换,具体包括:
14、通过以下公式进行标准正态变量变换:
15、
16、其中,xsnv表示标准正态变量变换后的光谱数据,x表示所有的光谱吸光度,表示平均光谱,n表示波长点数,m=1,2,3......,n,
17、所述对标准正态变量变换后的光谱数据进行指数平滑化,具体包括:
18、通过以下公式进行指数平滑化:
19、b1=x1
20、bk=(1-t)bk-1+txk (2)
21、其中,向量序列{xk}=x1,x2,x3,...表示标准正态变量变换后的光谱数据xsnv中的一列数据,向量序列{bk}表示向量序列{xk}的指数平滑化序列,t表示平滑参数。
22、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述利用半重数采样法将经过清洗和预处理后的所述在线近红外光谱数据划分成标准数据和实测数据,具体包括:
23、从经过清洗和预处理后的所述在线近红外光谱数据中多次随机选择总样本数的一半样本作为采样子集;
24、计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离;
25、计算各采样子集所对应的马氏距离的平均值;
26、取马氏距离的平均值最小的预设百分数所对应的在线近红外光谱数据作为标准数据;
27、将标准数据之外的经过清洗和预处理后的所述在线近红外光谱数据作为实测数据。
28、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离,具体包括:
29、通过以下公式计算每个采样子集中每个样本距离该采样子集中的采样中心点的马氏距离:
30、
31、其中,xn表示第n个样本的光谱行向量,xm表示第m个样本的光谱行向量,r-1表示类协方差矩阵的逆矩阵,xdnm表示样本xn与样本xm之间的距离,
32、并且,r-1通过以下公式进行计算:
33、
34、其中,x表示经过清洗和预处理后的所有近红外光谱数据,表示x的平均光谱,xc表示对x进行均值中心化后的光谱矩阵。
35、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述计算各采样子集所对应的马氏距离的平均值,具体包括:
36、通过以下公式计算样本xn与x之间的马氏距离:
37、
38、用主成分分析的得分t代替光谱数据x,这时公式(5)可以表示为:
39、
40、也可以写成:
41、
42、其中,tnk表示样本xn的第k个主成分得分;表示x的第k个主成分得分的平均值;βk表示矩阵的第k个特征值;g表示选用的主因子数;
43、
44、其中,表示x的平均值,σd表示x的平均值标准差;e表示调整阈值范围的权重系数。
45、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述预设百分数为5%,
46、所述取马氏距离的平均值最小的预设百分数所对应的在线近红外光谱数据作为标准数据,具体包括:
47、通过以下公式确定实测数据:
48、f(x标准数据)=∫5%f(xdn) (9)
49、其中,f(xdn)表示x中所有光谱数据的马氏距离平均值按从大到小排序后的光谱数据,f(x标准数据)表示取马氏距离排序前面5%的数据。
50、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述利用最大似然估计无监督学习分类法对标准数据按班别进行分类,具体包括:
51、通过以下公式确定标准数据的分布律:
52、q{x标准数据=x}=qx(1-q)1-x (10)
53、其中,x标准数据表示标准数据,q表示概率分布函数,x表示标准数据x标准数据中的任意一条光谱数据;
54、根据标准函数的分布律,确定似然函数为:
55、
56、其中,h(q|x)为概率,表示通过已知的分布函数与参数,随机生成出x的概率,s表示标准数据x标准数据中样品的个数,xi表示标准数据x标准数据中的第i个样品,
57、对公式(11)化简,得到:
58、
59、对公式(12)中参数求导,根据导数等于0,得到最大似然估计:
60、
61、其中,d表示标准数据x标准数据中的求导函数,
62、对公式(13)进行求解,得到分成的类别为:
63、f(α)=∫∫h(qx) (13)
64、其中,f(α)表示分类函数。
65、如上所述的基于数据挖掘的异常光谱识别分析方法,其中,优选的是,所述根据标准数据的分类结果和实测数据建立异常分析模型,通过监测似然度和主成分判断烟叶光谱数据是否异常,并剔除异常光谱数据,具体包括:
66、计算以标准数据为基准的似然度分类后每个类别的平均值;
67、将实测数据在似然度分类主成分空间进行投影,计算每一条实测数据离标准数据平均值的马氏距离;
68、利用标准数据的95%分位数判断马氏距离是否构成异常,同时监测实测数据在标准数据的不同主成分上的投影,如果大于标准数据在同一主成分上投影的3倍标准差则实测数据异常,剔除异常光谱数据,同时计算每类超过2倍标准偏差的异常率以及超过3倍的平滑异常率,以确定造成异常的班别。
69、本发明提供一种基于数据挖掘的异常光谱识别分析方法,通过数据挖掘技术从前期收集的在线近红外海量数据中寻找有用的信息,建立一套异常光谱识别分析策略,可以对在线生产过程中的烟叶光谱数据进行异常识别并剔除,保存大量有效数据的同时排除无效数据,不仅减少内存的消耗,延长仪器使用寿命,而且可以提高数据的准确性、可信度和实用性,从而促进有效数据的使用和价值的发挥,保障数据分析结果的可靠性和有效决策。
- 还没有人留言评论。精彩留言会获得点赞!