一种茶叶样本的处理方法与流程
本发明涉及电数字数据处理,特别是涉及一种茶叶样本的处理方法。
背景技术:
1、现有技术中对茶叶优先级的评估主要是依赖于人工经验和感官评价,不同的茶叶优先级对应不同的茶叶品质,优先级越高,对应的茶叶品质越好;这种由人工判断茶叶优先级的方法存在较强的主观性。茶叶生长过程中的气象因素对茶叶的优先级具有显著影响,如何基于茶叶生长过程中的气象因素自动判断茶叶的优先级,是亟待解决的问题。
技术实现思路
1、本发明的目的在于提供一种茶叶样本的处理方法,用于基于茶叶生长过程中的气象因素自动判断茶叶的优先级。
2、根据本发明,一种茶叶样本的处理方法,包括以下步骤:
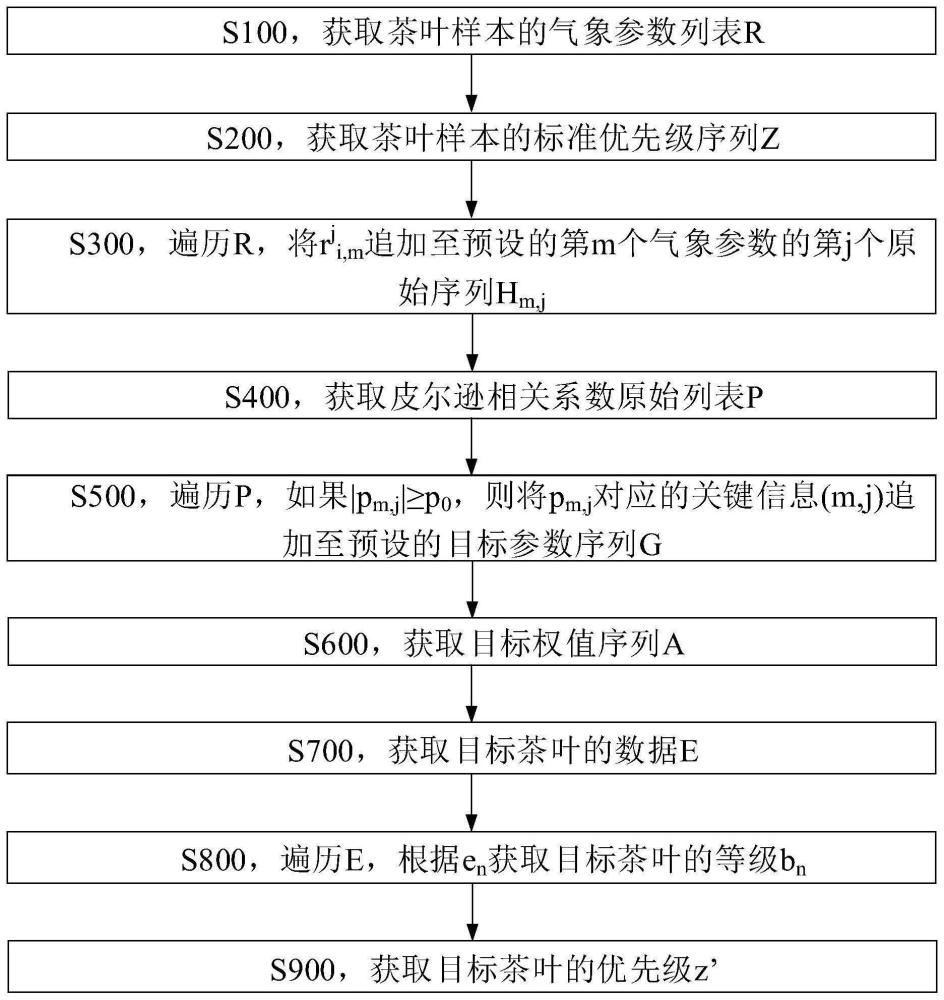
3、s100,获取茶叶样本的气象参数列表r,r=(r1,r2,…,ri,…,ru),ri为第i个茶叶样本的气象参数的记录,ri=(ri,1,ri,2,…,ri,m,…,ri,m),ri,m为第i个茶叶样本的第m个气象参数的序列,ri,m=(r1i,m,r2i,m,…,rji,m,…,rvi,m),rji,m为第i个茶叶样本的第m个气象参数对应的第j个预设时间点的值,j的取值范围为1到v,v为预设时间点的数量,m的取值范围为1到m,m为气象参数的数量,i的取值范围为1到u,u为茶叶样本的数量。
4、s200,获取茶叶样本的标准优先级序列z,z=(z1,z2,…,zi,…,zu),zi为第i个茶叶样本的标准优先级。
5、s300,遍历r,将rji,m追加至预设的第m个气象参数的第j个原始序列hm,j,得到hm,j=(rj1,m,rj2,m,…,rji,m,…,rju,m),hm,j的初始化为空值。
6、s400,获取皮尔逊相关系数原始列表p,p=(p1,1,p1,2,…,p1,j,…,p1,v,p2,1,p2,2,…,p2,j,…,p2,v,…,pm,1,pm,2,…,pm,j,…,pm,v,…,pm,1,pm,2,…,pm,j,…,pm,v),pm,j为hm,j与z的皮尔逊相关系数。
7、s500,遍历p,如果pm,j≥p0,则将pm,j对应的关键信息(m,j)追加至预设的目标参数序列g,得到g=(g1,g2,…,gn,…,gn),gn为被追加至g的第n个关键信息,gn=(cn,tn),cn为gn包括的气象参数的编号,tn为gn包括的预设时间点的编号,n的取值范围为1到n,n为被追加至g的关键信息的数量,g的初始化为空值;p0为预设的皮尔逊相关系数阈值。
8、s600,获取目标权值序列a,a=(a1,a2,…,an,…,an),an为第cn个气象参数对应的第tn个预设时间点的权值。
9、s700,获取目标茶叶的数据e,e=(e1,e2,…,en,…,en),en为目标茶叶的第cn个气象参数对应的第tn个预设时间点的值;
10、s800,遍历e,根据en获取目标茶叶的等级bn;
11、s900,获取目标茶叶的优先级z’,z’=∑nn=1(an×bn),0<an<1,∑nn=1an=1。
12、本发明至少具有以下有益效果:
13、本发明获取了茶叶样本的气象参数列表,该列表中存储有各茶叶样本的各气象参数的各预设时间点的值;本发明还获取了茶叶样本的标准优先级序列,该序列中每一元素对应一个茶叶样本的标准优先级;本发明获取了由不同茶叶样本对应于同一气象参数的同一预设时间点的值构成的原始序列,并获取了每一原始序列与标准优先级序列的皮尔逊相关系数,如果某原始序列与标准优先级序列的皮尔逊相关系数大于等于预设的皮尔逊相关系数阈值,则将该原始序列对应的气象参数编号和预设时间点编号追加至目标参数序列中,由此,本发明可以获取所有与茶叶优先级较为相关的气象参数编号和预设时间点编号信息;基于目标参数序列中每一气象参数编号和预设时间点编号对应的权重,本发明能够实现对目标茶叶的优先级的预测,实现了自动判断茶叶优先级的目的。
技术特征:
1.一种茶叶样本的处理方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的茶叶样本的处理方法,其特征在于,p0的获取过程包括:
3.根据权利要求1所述的茶叶样本的处理方法,其特征在于,在s100之前,还包括:
4.根据权利要求1所述的茶叶样本的处理方法,其特征在于,s800包括:
5.根据权利要求1所述的茶叶样本的处理方法,其特征在于,zi的获取方法包括:
6.根据权利要求1所述的茶叶样本的处理方法,其特征在于,m=8,v=8,第1个气象参数为平均温度,第2个气象参数为积温,第3个气象参数为有效积温,第4个气象参数为气温日较差均值,第5个气象参数为适温天数,第6个气象参数为雨日数量,第7个气象参数为累积日照时数,第8个气象参数为平均湿度,第1个预设时间点为采收前10天,第2个预设时间点为采收前20天,第3个预设时间点为采收前30天,第4个预设时间点为采收前40天,第5个预设时间点为采收前50天,第6个预设时间点为采收前60天,第7个预设时间点为采收前70天,第8个预设时间点为采收前80天。
7.根据权利要求1所述的茶叶样本的处理方法,其特征在于,使用层次分析法获取an。
8.根据权利要求2所述的茶叶样本的处理方法,其特征在于,p1为p’中绝对值最大的皮尔逊相关系数的绝对值。
技术总结
本发明涉及电数字数据处理技术领域,特别是涉及一种茶叶样本的处理方法。所述方法包括:获取茶叶样本的气象参数列表R,R=(r<subgt;1</subgt;,r<subgt;2</subgt;,…,r<subgt;i</subgt;,…,r<subgt;u</subgt;),r<subgt;i</subgt;为第i个茶叶样本的气象参数的记录;获取茶叶样本的标准优先级序列Z;遍历R,将r<supgt;j</supgt;<subgt;i,m</subgt;追加至预设的第m个气象参数的第j个原始序列H<subgt;m,j</subgt;;获取皮尔逊相关系数原始列表P;遍历P,如果p<subgt;m,j</subgt;≥p<subgt;0</subgt;,则将p<subgt;m,j</subgt;对应的关键信息(m,j)追加至预设的目标参数序列G;获取目标权值序列A;获取目标茶叶的数据E;遍历E,根据e<subgt;n</subgt;获取目标茶叶的等级b<subgt;n</subgt;;获取目标茶叶的优先级z’。本发明能够自动判断茶叶优先级。
技术研发人员:周祖煜,黄圣亮,张澎彬,陈煜人,杨肖,刘昕璇,林波
受保护的技术使用者:北京香田智能科技有限公司
技术研发日:
技术公布日:2024/2/1
- 还没有人留言评论。精彩留言会获得点赞!