基于流式DBSCAN聚类算法的配电网量测数据异常检测方法与流程
本发明属于新型电力系统的异常数据感知,涉及一种配电网量测数据异常检测方法,尤其是一种基于流式dbscan聚类算法的配电网量测数据异常检测方法。
背景技术:
1、随着电力系统规模逐渐增大,网络结构、电网线路也逐渐多元化,系统的工作状态会遭到多种因素干扰。在此前提下,电力系统的量测数据具有大数据化、复杂化特征,且数据的采集、测量、传输和存储等过程均可能因系统干扰而存在异常,尤其是配电网量测数据的质量相对输电网更差,因此,对配电网量测数据进行异常检测是十分必要的。
2、传统的异常数据检测方法大多是对存储的静态数据进行离线集中计算,然而,目前配电网中的量测数据是以数据流的方式汇集到调度中心,这对异常数据检测的实时性和快速性提出了新要求,传统的异常数据检测方法在实时性和快速性方面已无法满足要求,且其难以支撑对大规模量测数据进行快速异常检测。
技术实现思路
1、经检索,未发现与本发明相同或相似的现有技术的专利文献。
2、
技术实现要素:
3、本发明的目的在于克服现有技术的不足,提出一种基于流式dbscan聚类算法的配电网量测数据异常检测方法,将流式计算与聚类算法相结合,能够实现对大规模量测数据流的快速异常检测。
4、本发明解决其现实问题是采取以下技术方案实现的:
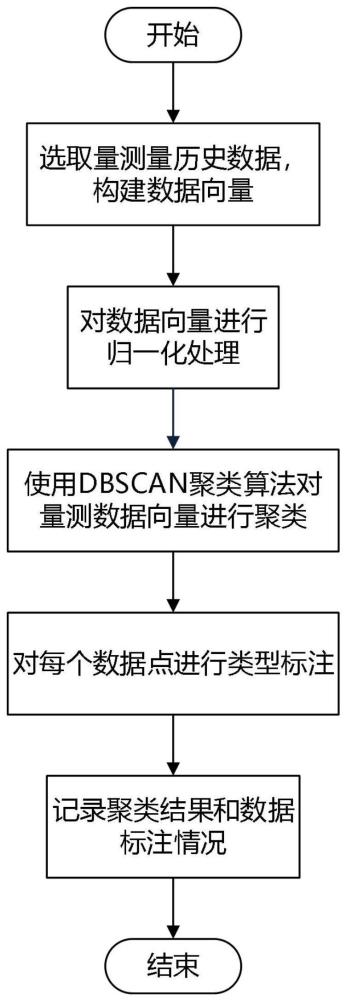
5、一种基于流式dbscan聚类算法的配电网量测数据异常检测方法,包括以下步骤:
6、步骤1、构建配电网量测数据异常检测模型;
7、步骤2、基于步骤1所构建的配电网量测数据异常检测模型,对配电网量测数据进行异常检测。
8、而且,所述步骤1的具体步骤包括:
9、(1)选取各量测量同一时间段内的历史数据作为数据集,与量测数据对应的时间序列特征和量测类型共同生成量测数据向量;
10、(2)对步骤(1)生成的量测数据向量进行归一化处理,以消除特征量之间的量纲影响;
11、(3)使用dbscan聚类算法对步骤(2)的量测数据向量进行聚类,并对每个数据点进行核心点、边缘点、异常点的类型标注,记录聚类结果和数据标注情况。
12、而且,所述步骤1第(1)步的具体步骤包括:
13、①提取各量测量的历史数据:
14、设共有n个量测量,从每个量测量中选取m个连续数据点(同一时间段),构成的数据集为z={zq|q∈[1,n×m]};
15、②构建量测数据向量:
16、对每一个数据点构造1×6维数据向量xi={zi,wi,di,hi,ti,ki},i∈[1,n×m],其中,zi为量测数据,wi、di、hi和ti分别为与量测数据一一对应的时间序列特征(周、日、时、分),ki表示数据类型(电流量用0表示、电压量用1表示、功率量用2表示);
17、而且,所述步骤1第(2)步的具体方法为:
18、采用min-max归一化方法,按照某种映射关系将数据映射到[0,1]区间,实现数据的归一化处理,映射函数为:
19、
20、其中,xmax为样本数据的最大值,xmin为样本数据的最小值。
21、而且,所述步骤1第(3)步的具体步骤包括:
22、①设量测数据样本集为d={x1,x2,...,xm},其中,每个样本为一个量测量且均为m维特征向量,邻域参数为(ε,minpts),其中,ε可取值为0.1*(xmax-xmin),minpts可取值为0.1*m,簇划分结果为c。
23、②初始化核心量测点集合初始化聚类簇数k=0,初始化未访问量测量集合γ=d,簇划分
24、③对于j=1,2,...,m,按如下步骤找出所有的核心点:
25、1)通过距离测度方式,找到量测量xj的ε-邻域子样本集nε(xj),即对于xj∈d,其ε-邻域包含量测数据样本集d中与xj的距离不大于ε的子样本集。本发明中,距离测度采用欧氏距离,计算公式如下;
26、
27、其中,xil表示量测量xi中第l个元素,xjl表示量测量xj中第l个元素;
28、2)如果子样本集量测量个数满足|nε(xj)|≥minpts,将量测量xj加入核心量测点集合:ω=ωu{xj}。
29、④若核心量测点集合则算法结束,转至步骤⑧,否则,转入下一步。
30、⑤在核心量测点集合ω中,随机选择一个核心点o,初始化当前簇核心点队列ωcur={o},初始化类别序号k=k+1,初始化当前簇样本集合ck={o},更新未访问量测量集合γ=γ-{o}。
31、⑥如果当前簇核心点队列则当前聚类簇ck生成完毕,更新簇划分c={c1,c1,...,ck},更新核心点集合ω=ω-ck,转入步骤④,否则,只更新核心点集合ω=ω-ck。
32、⑦在当前簇核心点队列ωcur中取出一个核心点o′,通过邻域距离阈值ε找出所有的ε-邻域子样本集nε(o′),令δ=nε(o′)iγ,更新当前簇样本集合ck=ck uδ,更新未访问量测量集合γ=γ-δ,更新簇核心点队列ωcur=ωcur u(δiω)-o′,转入步骤⑥。
33、⑧对每个数据点进行标注。标注后的数据点格式为:
34、pi=(yi,|xi1,xi2,...,xim|,vi) i∈(1,m) (3)
35、其中,yi为点所属的聚类;xij为数据点的各个特征;vi为数据点的类型,包括核心点、边缘点和异常点3类。
36、核心点:若某个点的密度达到算法设定的阈值则其为核心点(即ε-邻域内的点的数量不小于minpts)。
37、边界点:属于某一个类的非核心点,即它的邻域内的点少于minpts,但它在某个核心点的ε-邻域内。
38、异常点:不属于任何一个类簇的点,即任何一个核心点的ε-邻域内都不包括这个点。
39、⑨记录聚类结果和数据标注情况。
40、而且,所述步骤2的具体步骤包括:
41、(1)将新的数据点转化为数据向量后进行归一化处理;
42、(2)设置延迟因子α来综合考虑历史数据对新数据的影响程度,α=1表示历史数据和新数据具有同等影响,α=0则表示忽略历史数据;
43、(3)针对转化后的数据向量,基于流式dbscan聚类算法,实时判断向量的聚类特征,若数据向量在纵向(时间)和横向(空间)上表现出聚类特征,则标记为正常数据,否则标记为异常数据;
44、(4)根据历史数据的延迟因子α,将最近一段时间间隔内的数据作为新的数据集,更新聚类,重复上述步骤,直至不需要继续进行异常检测,从而完成配电网量测数据的异常检测。
45、而且,所述步骤2第(3)步的具体步骤包括:
46、①当一个新的量测数据向量x到来时,判断当数据向量x插入后,不同聚类之间的核心点是否实现了密度可达,若实现密度可达,则将数据向量x和这些相邻的聚类合并为一个新的聚类,转至步骤⑤,否则,转入下一步。
47、其中,密度可达是指:对于xi和xj,如果存在样本序列{p1,p2,...,pt},满足p1=xi,pt=xj,且pt+1由pt密度直达,则称xj由xi密度可达;
48、密度直达是指:如果xi位于xj的ε-邻域中,且xj是核心点,则称xi由xj密度直达。
49、②判断新数据向量x是否与某个聚类中的核心点密度可达,若是,则将x加入此聚类中,转至步骤⑤,否则,转入下一步。
50、③若新数据向量x是一个核心点,且满足x不属于任何一个已有的聚类和在x密度可达的点中不存在已有聚类的核心点,则创建一个新的聚类,转至步骤⑤,否则,转入下一步。
51、④当新数据向量x在邻域内没有核心点时,将x标记为异常数据,否则,标记为正常数据。
52、⑤对每批新到达的数据xt,依据上一时刻或历史数据聚类情况ct计算当前时刻聚类ct+1,当前时刻聚类中包含的数据点个数nt+1为历史数据个数nt和新到达数据个数mt之和,其当前时刻聚类计算过程如下:
53、
54、nt+1=nt+mt (5)
55、其中,ct+1为当前时刻聚类情况;ct为上一个时刻的聚类情况;nt+1为当前聚类中点的个数;nt为上一个时刻聚类中点的个数;xt为新加入聚类中的点;mt为新加入点的个数;α为延迟因子。
56、本发明的优点和有益效果:
57、1、本发明提供了一种基于流式dbscan聚类算法的配电网量测数据异常检测方法,首先选取各量测量同一时间段内的历史数据作为数据集,与量测数据对应的时间序列特征以及量测类型共同生成数据向量。在此基础上,基于量测数据在纵向(时间)和横向(空间)上表现出的聚类特性,使用dbscan(density-based spatial clustering ofapplications with noise,具有噪声的基于密度的聚类方法)对量测数据向量进行聚类,并对每个数据点进行类型标注(核心点、边缘点、异常点),能大大缩减异常检测模型的规模,提高检测速率。最后,根据实时采集的数据更新聚类并根据新的数据点表现出的聚类特征判断是否为异常数据。与目前已有的异常数据检测方法相比,本发明将流式计算与聚类算法相结合,能够实现对大规模量测数据流的快速异常检测。
58、2、本发明提出将流式计算与dbscan聚类算法相结合,提出了一种基于流式dbscan聚类算法的配电网量测数据异常检测方法,当流动的在线数据到来后在内存中直接进行数据的实时计算,能够快速检测异常数据,及时发现问题,实现异常数据的实时快速检测。
- 还没有人留言评论。精彩留言会获得点赞!