音视频标题生成方法、装置、设备及存储介质与流程
本申请实施例涉及人工智能,特别涉及一种音视频标题生成方法、装置、设备及存储介质。
背景技术:
1、在视频创作者将经过编辑后的视频上传至内容分享平台的过程中,为了提高视频曝光率和观看量,通常会为视频添加相应的视频标题。
2、相关技术中,为了降低创作者的工作负担,提高视频标题的编辑效率,通过采用基于模板和规则的方法,根据视频内容,从预先定义和维护的大量标题模板中,确定出与当前视频匹配的视频标题。
3、而创作者制作的视频往往具有较丰富且多样性的视频内容,基于规则生成的视频标题模板则风格较固定且缺乏灵活性,容易导致视频标题出现重复且刻板的问题,大大降低了视频标题的创新性和独特性。
技术实现思路
1、本申请实施例提供了一种音视频标题生成方法、装置、设备及存储介质,能够优化音视频标题的生成效率,提高音视频标题的标题质量。所述技术方案如下:
2、一方面,本申请实施例提供了一种音视频标题生成方法,所述方法包括:
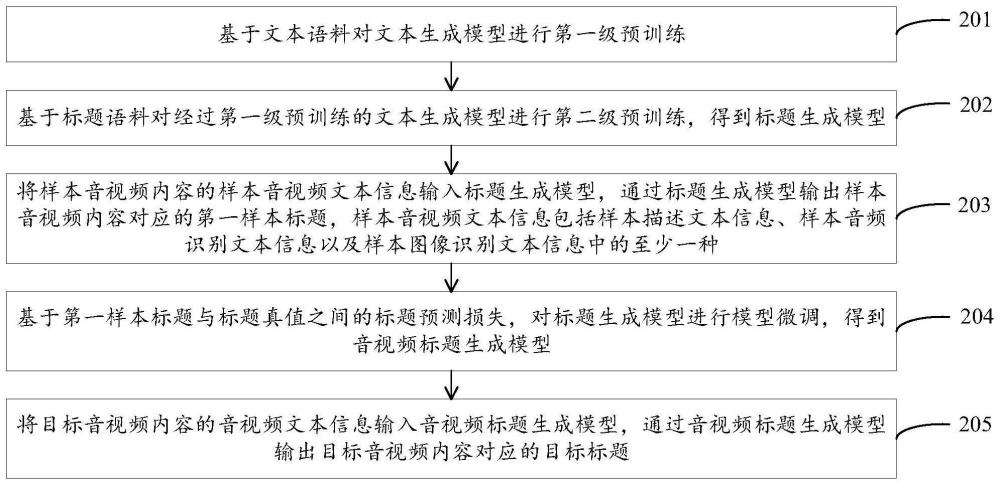
3、基于文本语料对文本生成模型进行第一级预训练;
4、基于标题语料对经过第一级预训练的所述文本生成模型进行第二级预训练,得到标题生成模型;
5、将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题,所述样本音视频文本信息包括样本描述文本信息、样本音频识别文本信息以及样本图像识别文本信息中的至少一种;
6、基于所述第一样本标题与标题真值之间的标题预测损失,对所述标题生成模型进行模型微调,得到音视频标题生成模型;
7、将目标音视频内容的音视频文本信息输入所述音视频标题生成模型,通过所述音视频标题生成模型输出所述目标音视频内容对应的目标标题。
8、另一方面,本申请实施例提供了一种音视频标题生成装置,所述装置包括:
9、第一训练模块,用于基于文本语料对文本生成模型进行第一级预训练;
10、第二训练模块,用于基于标题语料对经过第一级预训练的所述文本生成模型进行第二级预训练,得到标题生成模型;
11、第一输出模块,用于将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题,所述样本音视频文本信息包括样本描述文本信息、样本音频识别文本信息以及样本图像识别文本信息中的至少一种;
12、微调模块,用于基于所述第一样本标题与标题真值之间的标题预测损失,对所述标题生成模型进行模型微调,得到音视频标题生成模型;
13、第二输出模块,用于将目标音视频内容的音视频文本信息输入所述音视频标题生成模型,通过所述音视频标题生成模型输出所述目标音视频内容对应的目标标题。
14、另一方面,本申请实施例提供了一种计算机设备,所述计算机设备包括处理器和存储器;所述存储器存储有至少一条计算机指令,所述至少一条计算机指令用于被所述处理器执行以实现如上述方面所述的音视频标题生成方法。
15、另一方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一条计算机指令,所述至少一条计算机指令由处理器加载并执行以实现如上述方面所述的音视频标题生成方法。
16、另一方面,本申请实施例提供了一种计算机程序产品,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中。计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如上述方面所述的音视频标题生成方法。
17、本申请实施例中,首先利用文本语料对文本生成模型进行第一级预训练,以使得文本生成模型能够学习到自然语言的基本语法、句法和语义知识;然后利用标题语料对经过第一级预训练的文本生成模型进行第二级预训练,得到标题生成模型,以使得该标题生成模型能够学习到音视频标题的语言特征、风格和常用表达方式;进而在完成两级预训练之后,通过将样本音视频内容的样本音视频文本信息输入标题生成模型,通过标题生成模型输出第一样本标题,从而根据第一样本标题与标题真值之间的标题预测损失,对标题生成模型进行模型微调,得到音视频标题生成模型,使得音视频标题生成模型能够更好地理解音视频内容、提高泛化能力;最终通过将目标音视频内容的音视频文本信息输入音视频标题生成模型,即可以得到音视频标题生成模型输出的目标音视频内容对应的目标标题。
18、采用本申请实施例提供的方案,先通过两级预训练得到标题生成模型,再利用样本音视频内容的样本音视频文本信息,对标题生成模型进行模型微调,从而得到音视频标题生成模型,使得音视频标题生成模型能够更好地理解音视频的语义信息,提高了音视频标题生成模型在生成音视频标题时的准确性和多样性,优化了音视频标题的生成效率,提高了音视频标题的标题质量。
技术特征:
1.一种音视频标题生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题,包括:
3.根据权利要求2所述的方法,其特征在于,所述将所述样本音视频特征输入所述标题生成模型的线性层,通过所述线性层输出所述样本音视频内容对应的样本分类,包括:
4.根据权利要求2所述的方法,其特征在于,所述基于所述第一样本标题与标题真值之间的标题预测损失,对所述标题生成模型进行模型微调,得到音视频标题生成模型,包括:
5.根据权利要求4所述的方法,其特征在于,在所述标题生成模型中包括至少两个线性层的情况下,所述基于所述样本分类以及对应的分类真值,通过交叉熵损失计算,确定分类预测损失,包括:
6.根据权利要求4所述的方法,其特征在于,所述基于所述分类预测损失,以及所述第一样本标题与所述标题真值之间的所述标题预测损失,对所述标题生成模型进行模型微调,得到所述音视频标题生成模型,包括:
7.根据权利要求1所述的方法,其特征在于,所述将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题之前,所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,所述将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题,包括:
9.根据权利要求1所述的方法,其特征在于,所述将样本音视频内容的样本音视频文本信息输入所述标题生成模型,通过所述标题生成模型输出所述样本音视频内容对应的第一样本标题,包括:
10.根据权利要求9所述的方法,其特征在于,所述将目标音视频内容的音视频文本信息输入所述音视频标题生成模型,通过所述音视频标题生成模型输出所述目标音视频内容对应的目标标题,包括:
11.根据权利要求1所述的方法,其特征在于,所述基于标题语料对经过第一级预训练的所述文本生成模型进行第二级预训练,得到标题生成模型,包括:
12.一种音视频标题生成装置,其特征在于,所述装置包括:
13.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器;所述存储器存储有至少一条计算机指令,所述至少一条计算机指令用于被所述处理器执行以实现如权利要求1至11任一所述的音视频标题生成方法。
14.一种计算机可读存储介质,其特征在于,所述可读存储介质中存储有至少一条计算机指令,所述至少一条计算机指令由处理器加载并执行以实现如权利要求1至11任一所述的音视频标题生成方法。
15.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机指令,所述计算机指令存储在计算机可读存储介质中;计算机设备的处理器从所述计算机可读存储介质读取所述计算机指令,所述处理器执行所述计算机指令,使得所述计算机设备执行如权利要求1至11任一所述的音视频标题生成方法。
技术总结
本申请实施例公开了一种音视频标题生成方法、装置、设备及存储介质,属于人工智能技术领域。该方法包括:基于文本语料对文本生成模型进行第一级预训练;基于标题语料对经过第一级预训练的文本生成模型进行第二级预训练,得到标题生成模型;将样本音视频内容的样本音视频文本信息输入标题生成模型,通过标题生成模型输出样本音视频内容对应的第一样本标题;基于第一样本标题与标题真值之间的标题预测损失,对标题生成模型进行模型微调,得到音视频标题生成模型;将目标音视频内容的音视频文本信息输入音视频标题生成模型,通过音视频标题生成模型输出目标音视频内容对应的目标标题;能够优化音视频标题的生成效率,提高音视频标题的标题质量。
技术研发人员:陈春全
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!