一种基于变动因子Adam算法的玉米指数预测方法及系统
本发明涉及数据分析,更具体的,涉及一种基于变动因子adam算法的玉米指数预测方法及系统。
背景技术:
1、玉米是全球第三大主要粮食作物,仅次于小麦和大米。它具有高度的适应性,可以生长在各种气候条件下,从寒冷的高山地区到炎热的亚热带地区。玉米不仅被用作人类食物,还广泛用于饲料生产、酿酒、工业原料(如玉米油、玉米淀粉等)以及生物能源制备(如乙醇生产)。在中国,玉米被誉为"粮食之王",具有极高的经济和农业价值。中国是世界上最大的玉米生产国之一,玉米产量在全国农作物中位居前列。玉米在中国的地位非常重要,它不仅是主要的粮食作物之一,还是家禽、牲畜饲料的主要来源之一。中国的玉米产业涵盖了广泛的领域,包括粮食生产、工业加工和生物能源制备。中国的农民广泛种植各种品种的玉米,以满足国内食品需求和工业用途。玉米产业在中国的重要性不仅体现在食品和饲料方面,还在生物能源领域具有潜力。中国政府已经采取了多项措施来促进乙醇燃料生产和利用,将玉米作为原料之一。这不仅有助于减少化石燃料的使用,还创造了就业机会和经济增长。总之,玉米在中国的地位在农业、经济和能源方面都具有巨大的潜力和重要性,为中国农业和工业的可持续发展做出了重要贡献。玉米指数通常用于衡量玉米价格或市场表现的一种指标。玉米指数的变动可以用来追踪玉米市场的价格趋势、供需平衡情况以及市场的整体表现。它对于农业生产者、投资者和政府机构具有重要的参考价值,有助于决策制定和市场预测。因此,一种稳健、准确的玉米指数预测方法可以为农业生产者、投资者、政府机构和市场参与者提供重要的信息和好处,对进行决策支持、风险管理和资源分配等都具有促进作用。玉米指数数据作为金融领域数据,具有非平稳性,而且由于国际中战争、经济等政治因素和气候、市场等其他因素的影响,使得预测变得非常复杂。常见的玉米指数预测方法包括机器学习方法和神经网络预测方法,机器学习方法包括arima(差分自回归移动平均模型)和garch(广义自回归条件异方差模型),随机森林、决策数等,神经网络方法包括循环神经网络(rnn)和长短时记忆网络(lstm)。
2、现有技术有一种金融指数的周期波动估算方法,主要涉及金融工具、资产组合管理或者基金管理技术领域;包括步骤:s1、从金融数据终端获取待研究指数的日行情数据;s2、采用经验模式分解系列方法,按周期频率得到指数行情的周期因子imf;s3、按平均周期重构周期分量,重构出短期、中期和趋势重构分量;s4、将投资活动中收益和风险作为考量因素,收益用价格变动计算的收益率测度,风险用历史波动率测度;s5、综合经验模式分解及随机森林算法,进行行情和波动的预测;s6、构建周期波动投资策略。
3、然而现有技术存在仍存在对指数的预测不确定、不稳定的问题,因此如何发明一种基于变动因子adam算法的玉米指数预测方法及系统,是本技术领域亟需解决的技术问题。
技术实现思路
1、本发明为了解决现有技术对指数的预测不确定、不稳定的问题,提供了一种基于变动因子adam算法的玉米指数预测方法及系统,其具有训练方便,灵活高效的特点。
2、为实现上述本发明目的,采用的技术方案如下:
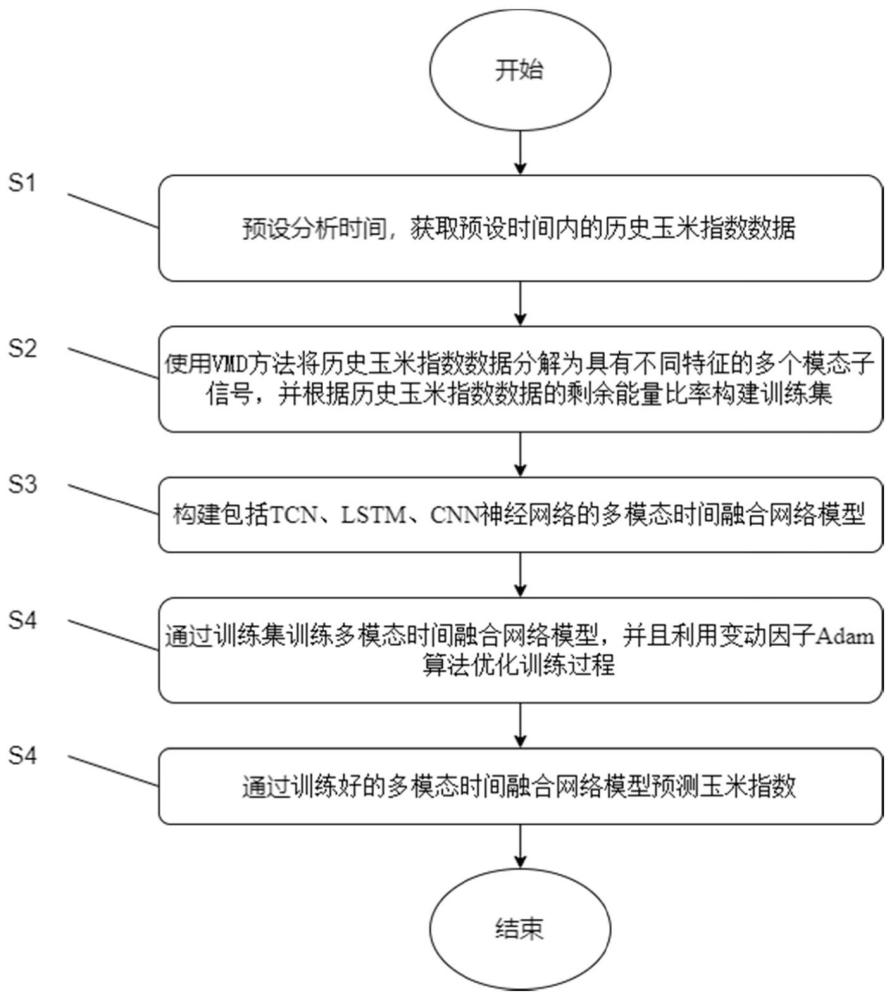
3、一种基于变动因子adam算法的玉米指数预测方法,包括以下具体步骤:
4、s1:预设分析时间,获取预设时间内的历史玉米指数数据;
5、s2:使用vmd方法将历史玉米指数数据分解为具有不同特征的多个模态子信号,并根据多个模态子信号的剩余能量比率构建训练集;
6、s3:构建包括tcn、lstm、cnn神经网络的多模态时间融合网络模型;
7、s4:通过训练集训练多模态时间融合网络模型,并且利用变动因子adam算法优化训练过程;
8、s5:通过训练好的多模态时间融合网络模型预测玉米指数。
9、优选的,所述的剩余能量比率具体为:
10、
11、其中,res(i)为剩余能量比率,m为待选模态数的数量,t为历史玉米指数数据序列,t={t1,t2,t3,…,tn},n为序列的长度,x为使用vmd方法分解得到的不同模态的模态子信号,x={x1,x2,x3,…,xm},e为信号能量,
12、
13、
14、其中,k={k1,k2,k3,…,km},k为模态。
15、进一步的,所述的步骤s2中,并根据多个模态子信号的剩余能量比率构建训练集,具体为:取前80%的数据作为训练集,后20%的数据前二分之一作为验证集,后二分之一作为并且对所有划分后的数据集进行归一化,得到训练集验证集和测试集
16、在训练集r中的数据中提取长度为w1的连续数据段,作为训练段同时将w1+1个数据作为标签
17、在验证集v中的数据中提取长度为w2的连续数据段,作为验证段同时将w2+1个数据作为标签
18、在测试集t中的数据中提取长度为w3的连续数据段,作为测试段同时将w3+1个数据作为标签
19、更进一步的,所述的多模态时间融合网络模型包括特征提取部分和预测部分;所述的特征提取部分包括tcn和lstm神经网络;所述的预测部分包括cnn神经网络:
20、tcn用于捕捉数据的局部模式和短期依赖关系;tcn神经网络的网络层包括三层的残差单元,残差单元包含两个卷积单元,其中卷积单元使用relu函数作为激活函数;
21、lstm用于捕捉数据的长期依赖关系;lstm神经网络的网络层包括一个lstm单元;将数据结果输入至lstm网络层中并输出经过处理后的时间序列表示;
22、cnn用于根据融合了数据长期依赖关系、局部模式、短期依赖关系的时间序列表示得到预测;cnn神经网络包含一层一维卷积和两层全连接层。
23、更进一步的,所述的步骤s4中,利用变动因子adam算法优化训练过程,具体为:在训练过程中通过根据梯度的方差自适应地调整参数和的范围和取值,并通过线性插值将梯度方差的倒数映射到合适的和的范围内,从而平衡了梯度的一阶动量和二阶动量对训练过程的影响:
24、
25、
26、
27、其中,mt为训练过程中历史梯度的一阶指数平滑值,用于得到带有动量的梯度值,作为一阶动量;vt为训练过程中历史梯度平方的一阶指数平滑值,用于得到每个权重参数的学习率权重参数,作为二阶动量;wt为权重变量的更新值;经过每个时间步t后,和会经过一次自适应变化,根据当前梯度方差进行变化:
28、
29、
30、其中,gvar表示当前时间步t的梯度方差。
31、更进一步的,所述的步骤s5中,还对训练好的多模态时间融合网络模型法进行了测试,若训练好的多模态时间融合网络模型通过了测试,通过训练好的多模态时间融合网络模型预测玉米指数,若训练好的多模态时间融合网络模型未通过测试,则返回步骤s4重新训练多模态时间融合网络模型。
32、更进一步的,对训练好的多模态时间融合网络模型法进行了测试,具体为:将测试集ritest输入训练好的多模态时间融合网络模型中进行了测试:将预测的结果进行反归一化后,得到每个模态子信号的预测结果pi={p1,p2,…,pku},将每个模态子信号的预测结果进行重构相加,得到原始序列的预测结果pre,将pre通过平均绝对百分比误差评估、加权平均误差评估、敏感度评估、特异度评估、精确度评估与原始序列后10%的数据进行对比,根据评估结果是否符合设定阈值判断是否通过测试。
33、更进一步的,平均绝对百分比误差评估计算了每个观测值的绝对百分比误差,然后对这些误差进行加权求和,用于反映模型对于关键值的预测性能;加权平均误差评估用于进行模型总体的平均性能度量;敏感度用于评估模型上升趋势预测能力;特异度评估用于评估模型下降趋势预测能力;精确度评估用于评估模型的综合方向性预测能力。
34、更进一步的,平均绝对百分比误差评估具体为:
35、
36、其中,mape为平均绝对百分比误差,at表示pre中第t个预测结果,ft表示原始序列后10%的数据中第t个结果;
37、加权平均误差评估具体为:
38、
39、其中,wape为加权平均误差;
40、敏感度评估具体为:
41、
42、其中,sen表示敏感度,tp为真阳值,代表正确预测出上涨的情况,fn为假阴值,代表错误预测下降的情况;
43、特异度评估具体为:
44、
45、其中,spe表示特异度,fp为假阳值,代表错误预测出上涨的情况,tn为真阴值,代表正确预测下降的情况;
46、精确度评估具体为:
47、
48、其中,acc为精确度。
49、一种基于变动因子adam算法的玉米指数预测系统,包括数据获取模块、数据构建模块、多模态时间融合网络模型构建模块、模型训练模块、指数预测模块;
50、所述的数据获取模块用于预设分析时间,获取预设时间内的历史玉米指数数据;
51、所述的数据构建模块用于使用vmd方法将历史玉米指数数据分解为具有不同特征的多个模态子信号,并根据多个模态子信号的剩余能量比率构建训练集;
52、所述的多模态时间融合网络模型构建模块用于构建包括tcn、lstm、cnn神经网络的多模态时间融合网络模型;
53、所述的模型训练模块用于通过训练集训练多模态时间融合网络模型,并且利用变动因子adam算法优化训练过程;
54、所述的指数预测模块用于通过训练好的多模态时间融合网络模型预测玉米指数。
55、本发明的有益效果如下:
56、本发明提出了一种基于变动因子adam算法的玉米指数预测方法包括:提出多模态时间融合网络模型,采用tcn和lstm两种不同类型的神经网络并行处理相同的时间序列数据,最后将处理的结果融合,得到更全面的时间序列表示,再将融合后的结果传递到cnn中,以进行最终的特征提取和预测;还提出变动因子adam算法,可以使得优化算法更加灵活、稳定和高效,从而提高算法的性能和收敛速度。由此本发明解决了现有技术对指数的预测不确定、不稳定的问题,且具有训练方便,灵活高效的特点。
- 还没有人留言评论。精彩留言会获得点赞!