反讽识别方法、装置、计算设备及存储介质与流程
本发明涉及计算机,具体涉及一种反讽识别方法、装置、计算设备及存储介质。
背景技术:
1、反讽作为一种特殊的修辞手法,其特点为文本的字面含义与真实含义不一致。在如今的社交媒体平台上,不乏见到使用反讽修辞的网络文本,人们通常使用反讽的手法来表达对某一现象、事件或实体的嘲讽或不满,准确识别这些反讽文本,能够帮助了解网络用户真实的情感倾向,对于情感分析和舆情监测具有重要意义。
2、目前反讽识别通常采用有监督学习的方法,使用有标注数据训练深度学习模型。但是现有的中文反讽识别的公开数据集都相对较小,其中的正例文本大多仅有几千条,这远不能满足模型训练需要,制约了反讽识别性能的提升,同时反讽识别模型的构建也存在一定的难度。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的反讽识别方法、装置、计算设备及存储介质。
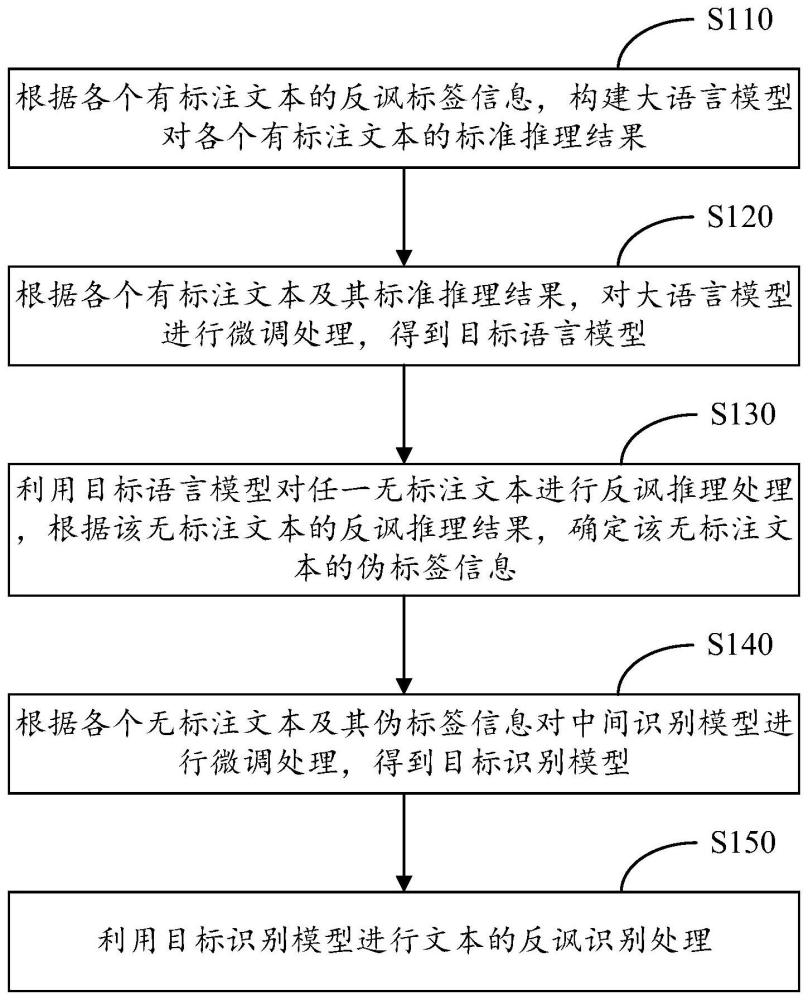
2、根据本发明的一个方面,提供了一种反讽识别方法,包括:
3、根据各个有标注文本的反讽标签信息,构建大语言模型对各个有标注文本的标准推理结果;
4、根据各个有标注文本及其标准推理结果,对大语言模型进行微调处理,得到目标语言模型;
5、利用目标语言模型对任一无标注文本进行反讽推理处理,根据该无标注文本的反讽推理结果,确定该无标注文本的伪标签信息;
6、根据各个无标注文本及其伪标签信息对中间识别模型进行微调处理,得到目标识别模型;其中,中间识别模型用于提取输入文本的文本表示向量;
7、利用目标识别模型进行文本的反讽识别处理。
8、可选地,根据各个有标注文本及其标准推理结果,对大语言模型进行微调处理,得到目标语言模型进一步包括:
9、为大语言模型的权重矩阵添加一个旁路低秩矩阵,得到初始语言模型;
10、根据各个有标注文本及其标准推理结果对初始语言模型进行训练,得到目标语言模型;其中,在训练过程中,固定大语言模型的权重矩阵,对旁路低秩矩阵进行更新。
11、可选地,方法执行之前,进一步包括:
12、从社交媒体平台中获取各个社交媒体文本;
13、分别计算各个社交媒体文本的热度分数,过滤热度分数低于预设阈值的社交媒体文本;
14、对过滤后剩余的各个社交媒体文本进行反讽标记处理,得到各个有标注文本及其反讽标签信息。
15、可选地,利用目标语言模型对任一无标注文本进行反讽推理处理,根据该无标注文本的反讽推理结果,确定该无标注文本的伪标签信息进一步包括:
16、使用目标语言模型对任一无标注文本进行多次反讽推理处理,得到多个反讽推理结果;
17、若多个反讽推理结果中相同的反讽推理结果的数量满足预设条件,根据相同的反讽推理结果确定该无标注文本的伪标签信息。
18、可选地,根据各个无标注文本及其伪标签信息对中间识别模型进行微调处理,得到目标识别模型进一步包括:
19、在任一无标注文本的前后分别添加第一标志和第二标志,得到输入序列;其中,第一标志是用于表征整个文本的语义信息的符号,第二标志是文本分割符号;
20、将输入序列输入到中间识别模型中进行处理,从中间识别模型的最后一层提取第一标志对应的向量作为文本表示向量;
21、将文本表示向量输入至前馈网络进行处理,并通过回归函数得到该无标注文本的反讽预测结果;
22、根据反讽预测结果和该无标注文本的伪标签信息计算损失函数,并使用后向传播算法训练网络;
23、重复上述步骤,直至损失函数最小化,得到目标识别模型。
24、可选地,中间识别模型包括:经过领域适应训练的预训练语言模型,方法还包括:
25、获取多个预训练语料,分别对多个预训练预料进行分词处理,得到多个分词结果;
26、按照预设概率随机对多个分词结果中的词进行遮蔽处理,得到多个已遮蔽的分词结果;
27、将每一个已遮蔽的分词结果输入至预训练语言模型,得到遮蔽处的词预测结果;
28、根据遮蔽处的词预测结果和遮蔽处的真实词,计算得到损失值;
29、根据损失值训练预训练语言模型,得到中间识别模型。
30、可选地,根据各个有标注文本及其标准推理结果,对大语言模型进行微调处理进一步包括:
31、将任一有标注文本以及预设提示模板组合成第一问题,根据第一问题以及该有标注文本的标准推理结果,对大语言模型进行微调处理;
32、利用目标语言模型对任一无标注文本进行反讽推理处理进一步包括:
33、将预设提示模板和任一无标注文本组合成第二问题,将第二问题输入至目标语言模型进行反讽推理处理。
34、根据本发明的另一方面,提供了一种反讽识别装置,包括:
35、构建模块,适于根据各个有标注文本的反讽标签信息,构建大语言模型对各个有标注文本的标准推理结果;
36、第一微调模块,适于根据各个有标注文本及其标准推理结果,对大语言模型进行微调处理,得到目标语言模型;
37、推理模块,适于利用目标语言模型对任一无标注文本进行反讽推理处理,根据该无标注文本的反讽推理结果,确定该无标注文本的伪标签信息;
38、第二微调模块,适于根据各个无标注文本及其伪标签信息对中间识别模型进行微调处理,得到目标识别模型;其中,中间识别模型用于提取输入文本的文本表示向量;
39、识别模块,适于利用目标识别模型进行文本的反讽识别处理。
40、可选地,第一微调模块进一步适于:
41、为大语言模型的权重矩阵添加一个旁路低秩矩阵,得到初始语言模型;
42、根据各个有标注文本及其标准推理结果对初始语言模型进行训练,得到目标语言模型;其中,在训练过程中,固定大语言模型的权重矩阵,对旁路低秩矩阵进行更新。
43、可选地,装置还包括:
44、标注模块,适于从社交媒体平台中获取各个社交媒体文本;分别计算各个社交媒体文本的热度分数,过滤热度分数低于预设阈值的社交媒体文本;对过滤后剩余的各个社交媒体文本进行反讽标记处理,得到各个有标注文本及其反讽标签信息。
45、可选地,推理模块进一步适于:
46、使用目标语言模型对任一无标注文本进行多次反讽推理处理,得到多个反讽推理结果;若多个反讽推理结果中相同的反讽推理结果的数量满足预设条件,根据相同的反讽推理结果确定该无标注文本的伪标签信息。
47、可选地,第二微调模块进一步适于:在任一无标注文本的前后分别添加第一标志和第二标志,得到输入序列;其中,第一标志是用于表征整个文本的语义信息的符号,第二标志是文本分割符号;将输入序列输入到中间识别模型中进行处理,从中间识别模型的最后一层提取第一标志对应的向量作为文本表示向量;将文本表示向量输入至前馈网络进行处理,并通过回归函数得到该无标注文本的反讽预测结果;根据反讽预测结果和该无标注文本的伪标签信息计算损失函数,并使用后向传播算法训练网络;重复上述步骤,直至损失函数最小化,得到目标识别模型。
48、可选地,中间识别模型包括:经过领域适应训练的预训练语言模型,装置还包括:
49、预训练模块,适于获取多个预训练语料,分别对多个预训练预料进行分词处理,得到多个分词结果;按照预设概率随机对多个分词结果中的词进行遮蔽处理,得到多个已遮蔽的分词结果;将每一个已遮蔽的分词结果输入至预训练语言模型,得到遮蔽处的词预测结果;据遮蔽处的词预测结果和遮蔽处的真实词,计算得到损失值;根据损失值训练预训练语言模型,得到中间识别模型。
50、可选地,第一微调模块进一步适于:将任一有标注文本以及预设提示模板组合成第一问题,根据第一问题以及该有标注文本的标准推理结果,对大语言模型进行微调处理;
51、推理模块进一步适于:将预设提示模板和任一无标注文本组合成第二问题,将第二问题输入至目标语言模型进行反讽推理处理。
52、根据本发明的又一方面,提供了一种计算设备,包括:处理器、存储器、通信接口和通信总线,所述处理器、所述存储器和所述通信接口通过所述通信总线完成相互间的通信;
53、所述存储器用于存放至少一可执行指令,所述可执行指令使所述处理器执行上述反讽识别方法对应的操作。
54、根据本发明的再一方面,提供了一种计算机存储介质,所述存储介质中存储有至少一可执行指令,所述可执行指令使处理器执行如上述反讽识别方法对应的操作。
55、根据本发明的反讽识别方法、装置、计算设备及存储介质,该方法包括:根据各个有标注文本的反讽标签信息,构建大语言模型对各个有标注文本的标准推理结果;根据各个有标注文本及其标准推理结果,对大语言模型进行微调处理,得到目标语言模型;利用目标语言模型对任一无标注文本进行反讽推理处理,根据该无标注文本的反讽推理结果,确定该无标注文本的伪标签信息;根据各个无标注文本及其伪标签信息对中间识别模型进行微调处理,得到目标识别模型;中间识别模型用于提取输入文本的文本表示向量;利用目标识别模型进行文本的反讽识别处理。通过上述方式,能够借助大语言模型强大的语义理解能力,使用半监督学习的方式,在标注数据有限的情况下,充分利用大量的无标注数据,实现有标注数据的扩充,能够提升模型的反讽识别性能,并且通过微调的方式构建识别模型,能够提升模型构建的效率。
56、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!