一种基于图像的三维物体可供性定位方法
本发明属于计算机视觉领域,具体的说是一种基于图像的三维物体可供性定位方法。
背景技术:
1、可供性(affordance)由生态心理学家吉普森于1979年提出,描述了如何直接感知环境中物体的内在价值和意义,并且解释了这些信息如何与环境提供的有机体的动作可能性相联系。视觉可供性是可供性研究的一个分支,它将可供性作为基于图像或者视频的计算机视觉问题来处理,并使用机器学习相关的技术来解决这些挑战。感知和推理物体的局部区域可能发生的交互,是被动感知系统向主动与环境交互、感知的具身智能系统转换的关键。弱监督场景下的标定物体可供性区域也吸引着研究者的注意力。
2、deng等人首先提出了直接将可供性类别与三维物体的结构建立映射,从而来标定三维物体的可供性,他首先从partnet数据集中筛选出了三维物体的cad模型,并在这些三维模型上标注了不同可供性类别的热力图,之后再从这些三维模型上采样出稀疏的三维点云用于模型训练。在训练中直接采用点云特征提取网络pointnet++与dgcnn等提取点云的特征然后建立映射。nagarajan等人提出在一个虚拟的合成环境中让一个智能体主动与环境发生交互,利用强化学习的奖励函数机制来优化整个学习过程,让智能体理解三维世界中物体的可供性。这些方法从物体的结构出发,将结构和可供性之间建立映射,并没有感知到交互与可供性之间的关系,导致在出现不同交互或者未知类别时,无法有效地预测出准确的结果。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于图像的三维物体可供性定位方法,旨在解决三维物体可供性定位中的歧义性和未知物体泛化性的问题,通过建立图像中交互物体和点云物体的隐式联系,将图像与点云中的物体在语义空间对齐,并通过图像中的交互内容来定位三维物体的可供性,从而能有效的完成三维物体可供性标定任务。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种基于图像的三维物体可供性定位方法的特点在于,包括以下步骤:
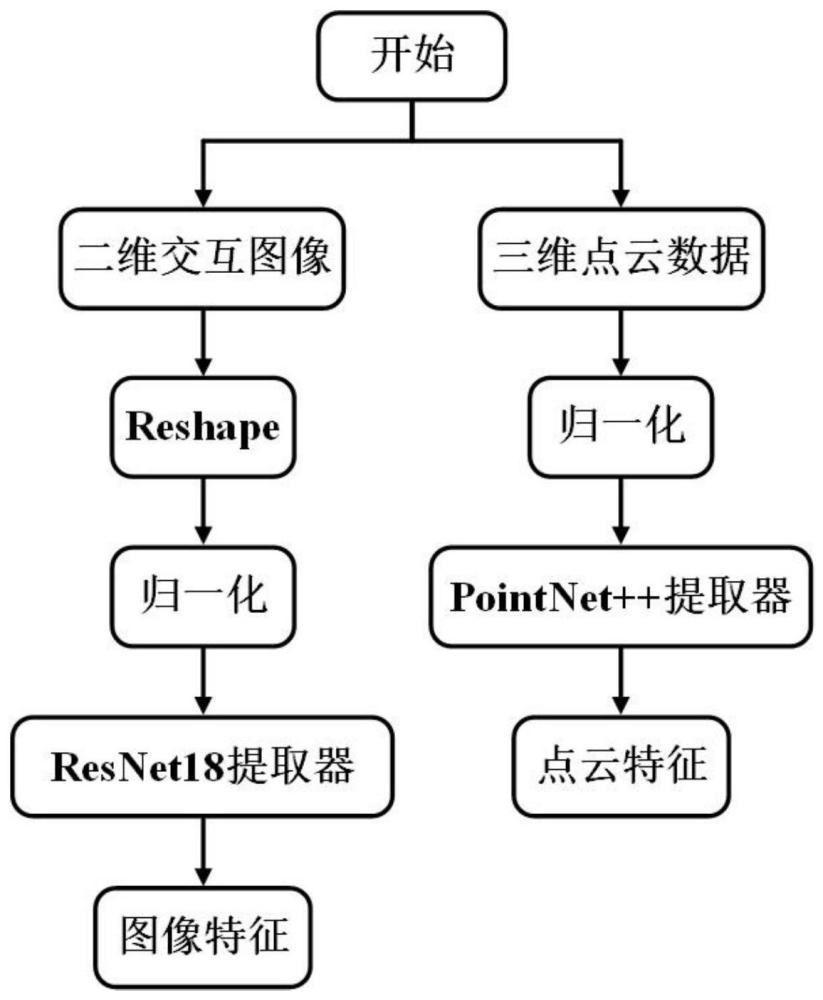
4、步骤1、提取图像的特征和三维点云的特征:
5、步骤1.1、提取图像的特征;
6、获取一个批次的图像{i1,i2,…,ib,…,ib},代表第b张图像,其中,b代表一个批次的图像的数量,c代表一张图像的通道数量,w,h分别代表图像的宽和长;
7、将第b张图像ib进行归一化处理后输入resnet18网络中,并得到特征向量其中,w1,h1分别为采样后的特征向量的宽和高,c1代表特征向量的通道数;
8、步骤1.2、提取点云的特征;
9、获取同一个批次的物体点云数据{p1,p2,…,pb,…,pb},代表第b个点云数据,n为每个点云数据中点的数量,3代表点云数据的空间维度;
10、利用pointnet++网络提取pb中点云物体的逐点特征
11、步骤2、计算第b张图像ib中物体的特征与点云物体的逐点特征fpb的对应性:
12、步骤2.1、标定第b张图像ib中物体的特征:
13、用一个锚框bob∈(x1,y1,x2,y2)标定出第b张图像ib中属于物体的特征,其中,x1,y1代表一个锚框bob的左上角顶点的坐标,x2,y2代表锚框bob右下角顶点的坐标;
14、使用roi-align算法对锚框bob内的特征进行池化处理后再进行展平,从而得到第b张图像ib中物体的特征其中,n’代物体特征fob的像素点总和数;
15、步骤2.2、计算物体特征fob与逐点特征fpb对应性;
16、步骤2.2.1、对逐点特征fpb进行转置后,得到转置后的逐点特征np代表点云数据中点的个数;
17、步骤2.2.2、对fob和fp’b进行一次跨模态的交叉注意力计算:
18、将fob作为查询query,fp’b作为键key和值value来更新fob,随后将fp’b作为查询query,fob作为键key和值value来更新fp’b,从而将更新后的逐点特征fp”b和物体特征f'ob拼接为联合特征通过联合注意力机制算法计算fp”b和f'ob之间的多模态物体特征
19、步骤3、可供性特征提取:
20、步骤3.1、标定第b张图像ib中交互主体特征和场景特征:
21、使用一个锚框bhb∈(x'1,y'1,x'2,y'2)定位出第b张图像ib中交互主体特征,在bob和bhb之外特征即为场景特征;其中,x'1,y'1代表一个锚框bhb的左上角顶点的坐标,x'2,y'2代表锚框bhb右下角顶点的坐标;
22、通过roi-align算法将交互主体特征和场景特征进行池化后,得到相同尺寸的交互主体特征fhb和场景特征fsb;
23、步骤3.2、可供性特征计算:
24、将作为共享的查询query,fhb和fsb分别作为键key和值value,从而对fhb和fsb进行跨模态的双分支交叉注意力计算,得到两个分支更新后的特征和
25、对fb1和fb2拼接后再进行卷积的计算,得到多模态可供性特征
26、步骤4.解码多模态物体特征及多模态可供性特征
27、按照拼接时的顺序,将拆分为图像的物体特征和点云物体特征
28、按照拼接时的顺序,将拆分成为图像可供性特征和点云可供性特征
29、步骤5.输出映射:
30、将和进行点乘后,再通过一个mlp层的映射,得到第b个点云数据pb对应的三维可供性向量θb;
31、将输入一个mlp层和池化层中进行处理,并输出第b张图像ib对应的可供性类别的逻辑向量yb;
32、步骤6、构建损失监督函数并训练:
33、步骤6.1、利用式(1)构建最终的损失函数
34、
35、式(1)中,表示三维可供性热力图损失,表示交叉熵类别损失;表示kl散度损失;
36、步骤6.2、利用梯度下降法对损失函数进行优化,使得损失函数收敛为止,从而得到三维物体可供性定位模型,用于实现对任意输入的图像和点云数据对进行三维可供性的定位。
37、本发明所述的一种基于图像的三维物体可供性定位方法的特点也在于,所述步骤6.1中是利用式(2)得到三维可供性热力图损失
38、
39、式(2)中,n代表训练样本的数量,代表三维可供性的标签;
40、利用式(3)得到交叉熵类别损失
41、
42、式(3)中,表示第b张图像ib的可供性类别标注;
43、利用式(4)得到kl散度损失
44、
45、式(4)中,∈表示正则化常数。
46、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述三维物体可供性定位方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
47、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述三维物体可供性定位方法的步骤。
48、与现有技术相比,本发明的有益效果在于:
49、1、本发明是通过图像中的交互内容来定位三维物体的可供性,这种学习范式让模型从交互中来推理物体的可供性,这样能够解决物体可供性本身具有的多重性问题以及对于未知物体结构的泛化性问题。
50、2、本发明通过将图像中的物体和点云物体在语义空间对齐,确保了映射到三维物体上的可供性契合图像中的交互内容,并且引入kl散度来约束对齐的过程,解决了没有监督跨模态语义对齐的显式信号的问题。
51、3、本发明提出将影响物体可供性的交互主体和场景特征进行联合建模以挖掘明确的物体可供性,消除了物体的多重可供性带来的影响,解决了物体可供性标定中的歧义性问题。
- 还没有人留言评论。精彩留言会获得点赞!