一种基于稀疏标注的图像分割方法
本发明属于图像分割算法领域,特别一种基于稀疏标注的图像分割方法。
背景技术:
1、图像分割旨在从图像中分离出各种不同类别的物体,在娱乐、安防、视频处理和医学图像等多个场景具有广泛的应用。例如,从医学影像中进行精确的组织分割可以为临床诊断提供大量有价值的信息,如目标的大小、位置、边界状态和目标间的空间位置关系等,对后续的疾病诊断、治疗工作安排具有重要的指导意义。传统的图像分割技术如基于阈值的方法、基于边缘检测的方法、基于活动轮廓的方法等利用图像中的低层次特征,很难获得高精度的分割结果。
2、近年来,基于深度学习的图像自动分割方法由于其优越的性能逐渐得到模式识别领域的关注,并已被广泛应用。然而,当前的深度学习方法的成功在很大程度上依赖于大规模高质量的具有像素级标注(密集标注)的训练图像。这种像素级别的标注的时间和人力成本十分高昂,极大地限制了深度学习图像分割算法的开发和应用。
3、近年来,为了减少对图像中密集标注的依赖,基于弱监督学习训练图像分割的深度学习模型成为一种技术趋势。常见的弱监督标注有涂鸦标注,边界框,点标注以及图像级标签等。涂鸦标签要求标注者对各个目标类别分别画一两条曲线进行标注;边界框标注将目标对象的大概位置框出来,不提供详细的内部信息;点标注只在目标对象上画点,提供初略的位置信息;图像级标签只给图像级标签以判断一幅图像中目标对象存在与否,缺少目标位置、大小信息。比较而言,涂鸦标注在具有较高的标注效率的同时,能更好的提供目标对象的位置和边界信息,因此比其他类型的弱标注可以更好地训练一个分割模型。
4、从稀疏的涂鸦标注中进行学习存在一定困难,由于监督信号稀少,很难直接训练出一个性能良好的图像分割模型。为了处理这一问题,常见的弱监督学习方法分为伪标签学习、一致性约束等。伪标签学习策略通过一个分割模型预测的伪标签对未标注数据进行利用,然而伪标签的质量通常较差,将极大影响模型性能。一致性约束策略通常对输入图像进行空间变换、数据增强等方式,使变换前后的图像的预测结果尽可能一致,从而对模型进行约束。然而,由于有效监督信息的缺乏,当前的弱监督学习方法与基于密集标注的学习方法之间还存在较大的性能差距。因此需要更有效的针对图像中多类别分割的弱监督学习方法。
技术实现思路
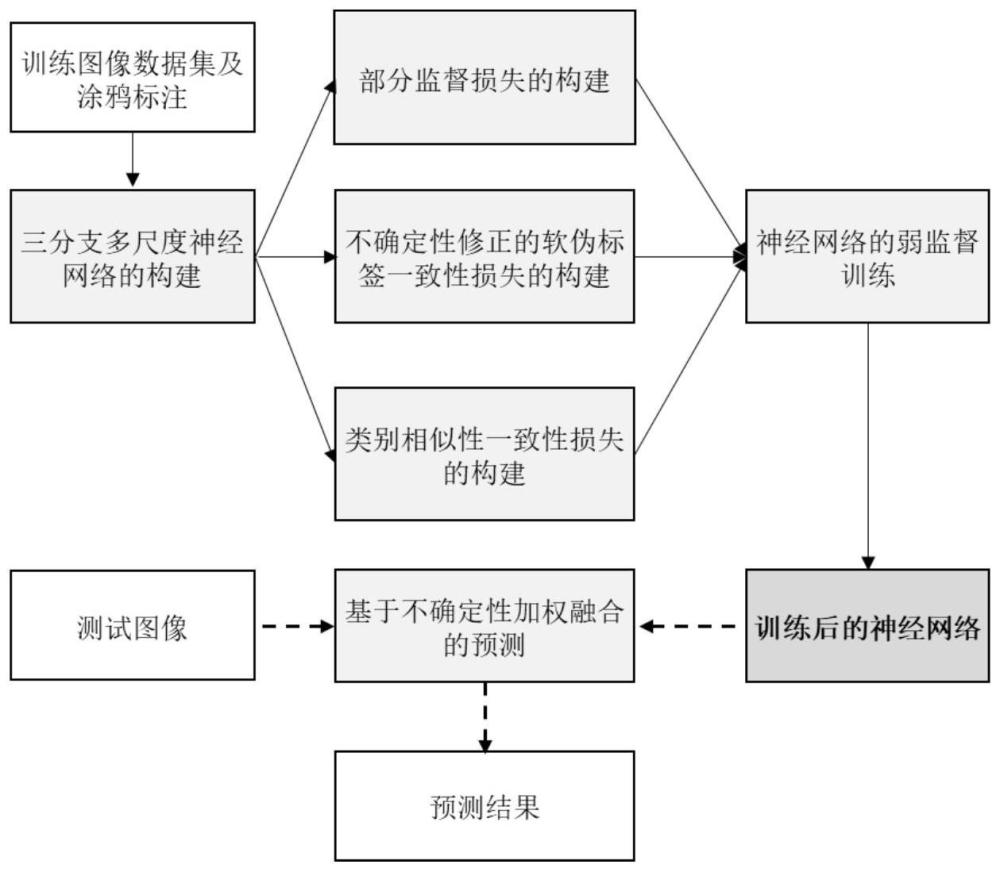
1、本发明的目的在于克服现有基于深度学习的图像分割方法对像素级密集标注的依赖性,提出一种基于弱监督的多类别分割方法。针对仅有涂鸦标注的训练图像,本发明提出了一种三分支多尺度神经网络,关注不同尺度感受野的特征并互相学习,增强模型的特征提取能力。在此基础上,基于一致性策略,提出两个一致性损失以利用像素层级信息和类间关系信息,对模型进行正则化约束以增强其分割性能。
2、本发明的目的可以通过以下技术方案来实现:一种基于稀疏标注的图像分割方法,该方法包括:
3、步骤1:构建三分支多尺度神经网络;
4、三分支多尺度神经网络由一个共享编码器θe和三个并行的解码器θd1,θd2,θd3组成;编码器θe由多个级联的卷积-下采样单元组成,每个卷积-下采样单元包括两个卷积块和一个下采样层,每个卷积块包括一个卷积层,一个实例归一化层和一个参数化线性整流函数(prelu)激活层;
5、每个解码器由多个级联的卷积-上采样单元组成,每个卷积-上采样单元包含两个卷积块和上采样层,其中卷积块的结构和编码器的卷积块一致,并且两个卷积块之间使用一个随机丢弃层(dropout);每个解码器中的卷积块使用不同的膨胀卷积率,分别设置为r1,r2,r3以从不同的感受野中提取语义信息;具体的,具有小膨胀卷积率的解码器提取详细的局部特征信息,但会因感受野的局限丢失全局上下文信息;具有大膨胀卷积率的解码器可以更好的利用全局信息,但可能会丢失一些细节信息;在三个解码器中使用不同的膨胀卷积率可以进行不同尺度的特征提取,产生具有一定差异的预测结果;这三个解码器的预测结果分别对应表示为p1,p2,p3;
6、步骤2:构建三分支多尺度神经网络的部分监督损失;
7、对于一组含涂鸦标注的图像数据集,用x和s分别表示一幅训练图像和对应的涂鸦标注,c表示分割的类别数量,ω=ωs∪ωu表示x中所有的像素集合,其中ωs表示s中含标注的像素集合,ωu表示没有标注的像素集合;
8、为利用涂鸦标注信息,使用部分交叉熵损失函数来监督网络的训练;该损失函数只在有标注的像素集合ωs中计算部分监督损失:
9、
10、其中,i表示像素编号,c表示类别编号,n=1,2,3表示解码器编号;是第n个解码器的预测结果中像素i属于类别c的概率;表示在涂鸦标注s中像素i属于类别c的概率;
11、步骤3:构建基于不确定性修正的软伪标签一致性损失;
12、将上述三个编码器的输出取平均,得到软伪标签:
13、
14、考虑到中可能包含噪声,为避免伪标签中噪声的干扰,定义一个像素级别的伪标签权重,该权重值与伪标签中的熵成反相关:
15、
16、其中,表示软伪标签中像素i属于类别c的概率;基于不确定性修正的软伪标签一致性损失定义如下:
17、
18、其中,kl(·)表示kullback-leibler散度;
19、步骤4:构建基于类别相似性一致性损失;
20、为了使不同的解码器输出有更好的相互约束,本发明提出基于类别相似性的一致性损失函数;对于一幅大小为h×w的二维图像,将解码器的输出写作为一个大小为c×hw的矩阵,其中c是类别数量;将及其转置矩阵做矩阵乘法,并进行归一化,得到一个大小为c×c的类别亲和矩阵
21、
22、其中t表示矩阵转置操作,||·||表示欧几里得范数,三个解码器得到的qn的平均值记为类别相似性一致性损失定义为:
23、
24、对于一幅大小为d×h×w的三维图像,解码器n的输出为由于像素个数为dhw,直接计算类别相似性矩阵的运算量和内存开销巨大,为了克服这一问题,针对三维图像,将qn替换为基于不同方向投影的类别相似性矩阵;具体地,将pn沿着z轴方向进行投影,得到一个大小为c×1×h×w的张量将写作为一个大小为c×hw的矩阵;基于z轴方向投影的类别亲和矩阵为:
25、
26、三个解码器得到的的平均值记为同样的,将pn分别沿着y轴和x轴投影,获得相应的类别亲和矩阵和针对三维图像,将重新定义为基于多视图投影的类别相似性一致性损失:
27、
28、其中v∈{z,y,x}是视图索引;
29、步骤5:训练三分支多尺度网络;
30、将含稀疏标注的训练图像集{x,s}输入上述三分支多尺度网络,利用如下的损失函数进行迭代训练,直至收敛:
31、
32、其中分别如公式1,公式5,公式6或公式8所示;αt和βt是随时间变化的权重系数,分别定义为:和其中α和β分别是这两个权重系数的最大值,t和tmax分别表示当前迭代次数和训练过程中的最大迭代次数;
33、步骤5:在测试图像上基于不确定性加权融合的预测;
34、在模型训练完成后,对于一幅测试图像,将其输入上述三分支多尺度神经网络,将三个预测分支上的结果进行加权融合,从而得到最终的预测结果;三个解码器的预测结果分别表示为p1,p2,p3;对于第n个预测结果pn,其第i个像素的预测结果表示为pn,i;其不确定性越大,对应的权重越低;该权重的定义为:
35、
36、在上述权重定义的基础上,第i个像素的融合预测结果为:
37、
38、将作为测试图像上的最终预测结果。
39、与现有技术相比,本发明具有以下优点:
40、(1)当前基于深度学习的图像分割方法大多依赖于大规模高质量的像素级标注图像,耗时耗力且成本高昂。本发明提出的弱监督方法只需在训练集上提供涂鸦标注,可以极大减少图像的标注成本并取得较高的分割精度。
41、(2)当前的大多数弱监督方法忽略了多尺度信息和类间信息的利用。对此,一方面,本方法通过三分支多尺度神经网络提取多尺度范围的信息,并且将来自不同尺度的预测结果融合形成高质量的伪标签。另一方面,本方法通过保持类别相似性一致性让网络学习类间关系信息,在标注不足的条件下提供约束。
42、(3)相较于传统的伪标签学习策略,本方法采用软伪标签对网络进行监督,避免因硬伪标签过于自信带来的分割区域假阳性问题。进一步的,通过基于不确定性的伪标签权重,让网络更加关注伪标签中置信度高的区域,从而提升网络的分割性能。
- 还没有人留言评论。精彩留言会获得点赞!