一种多级融合图像和文本的多模态方面级情感分析方法
本发明涉及图像和文本融合,具体地说,涉及一种多级融合图像和文本的多模态方面级情感分析方法。
背景技术:
1、社交网络的飞速发展所带来的不仅是人际交往上的方便快捷,足不出户就能和远在千里的人分享生活,同时也更接近现实的情感表达。不同于社交网络刚刚建立时内容只是纯文本信息,如今为了方便用户能更贴切的传递自身想法,表达方式从一开始局限于单一的文本表述过渡到现在颜文字、表情包、图片,视频等多模态化内容的排列组合。正如人们面对面交流时的情绪传递更多的依赖于肢体语言和语气等因素,以微信朋友圈、微博,推特(twitter)为首的众多社交平台上的内容上的百花齐放也让现阶段的用户情感倾向的分类无法做到高效和准确。以往单模态的文本情感分析已经不能有效利用大数据时代下的多元化内容。
2、多模态的情感分析是跨向充分使用多种模态信息进行基于情感的表示学习的重要一环,企业也能以此了解用户的关注重点和社会热点走向,从而更好地调整公司政策,以提高用户的满意度。然而目前大部分的多模态情感分析都是将多模态数据一起看待来判断用户的情感极性,却无法得知用户对于具体方面的情感判断。因此聚焦于方面词,可以在把握整体性的基础上,将方面级的情感信息也考虑其中。不过,在抽取方面词的基础上进而提取图像对应的情感信息却十分不易。
3、因此有些研究者考虑在注释数据集进行文本-图像关系检测的基础上,提出联合提取方面词并对其相应的情感进行分类,然而这种方法主要关注跨模态的全局交互,不能很好地解决图像和文本的细粒度对应关系。现有技术尽管将文本-图像通过文本和视觉编码器提取特征信息,分别映射到相同维度的映射空间再交互的方法可以在一定程度上融合文本和视觉的信息。然而由于图像和文本是语义鸿沟较大的两种模态,交互过程中不相关的视觉对象往往会对文本和视觉模态的融合造成负面影响,所以这些融合方法就局限在于在融合前没有对齐视觉对象和文本内容的语义;由于他们的模态间不对齐,交互问题没有得到充分解决。因此,在模态间对齐方面,尽管可以通过在大量标记数据的基础上进行预训练,但会消耗大量人力和计算资源,而且很少有研究探索弥合模态之间的语义差距,并有效利用视觉信息进行粗粒度到细粒度对齐的跨模态融合。
技术实现思路
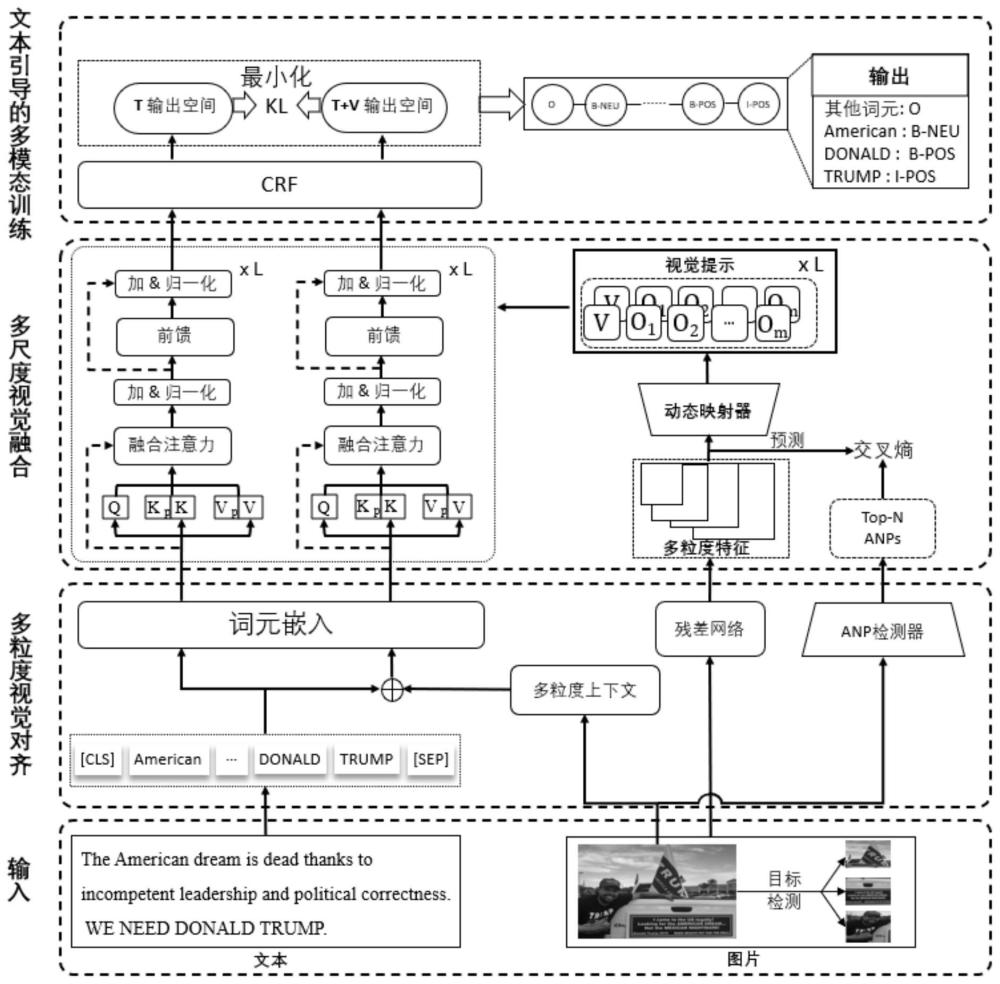
1、本发明的内容是提供一种多级融合图像和文本的多模态方面级情感分析方法,其能够解决模态间对齐与需要标注数据集所需人力和计算资源所代表的性能与成本之间的偏差问题。
2、根据本发明的一种多级融合图像和文本的多模态方面级情感分析方法,其特征在于:包括以下步骤:
3、步骤1、多粒度视觉对齐
4、包括粗粒度对齐、细粒度对齐以及字符粒度对齐;
5、步骤2、多尺度视觉融合
6、先通过利用多粒度视觉对齐的视觉数据来捕捉多尺度视觉特征并获得相应的层次视觉表示,然后进行视觉方面和意见的监督,最后基于prompt的动态视觉融合;
7、步骤3、文本引导的多模态训练
8、通过最小化文本输出空间与文本+图像上下文输出空间的kl损失,得到多模态方面级情感分析结果。
9、作为优选,粗粒度对齐中,通过图像描述模型处理图像,建立视觉和语言之间的整体关系,旨在生成有意义和有效的图像描述,在粗粒度级别上表示视觉内容的语义信息,连接模态之间的特征空间;具体为,应用图像字幕工具clipcap,为场景生成高质量的字幕,表示为c:
10、c=caption(g)
11、其中,c表示从caption生成的图像的总体描述,caption用作整个图像的粗粒度文本对齐映射,g表示输入的图像。
12、作为优选,细粒度对齐中,首先使用lightface人脸检测器来识别所有人脸,并将其转换为文本人脸属性;随后,利用面部表情描述模板来生成面部描述:
13、d=facedescription(g)
14、在获得文本形式的面部属性后,基于人脸检测器的预测置信度的顺序按降序排序,并过滤出预测置信度低的属性。
15、作为优选,字符粒度对齐中,应用谷歌的tesseract ocr引擎,通过从图像中精确识别和提取文本,实现了字符粒度对齐:
16、oc=ocr(g)
17、其中oc表示ocr模型提取的英语单词的串联序列;将oc与c和d连接起来,形成视觉上下文的文本-视觉对齐方式,表示为vc=(c,[sep],d,[sep],oc,[sep]);在这个阶段,视觉信息被映射到文本空间,并且在将其与文本输入t连接之后,形成t+v输入;在t输入和视觉上下文vc之间插入[sep]标记,t+v和t通过基于transformer的模型以获得最后的隐藏表示hlt+v与hlt,其被馈送到crf层中;对于标签序列y=(y1,y2,…,yn),给定隐藏表示hl的标签序列y的概率定义如下:
18、
19、p(y|hl)=softmax(s(hl,y))
20、其中,是从标签yj到yj+1的随机初始化的转换矩阵,表示从hl线性变换的标签yj的发射矩阵,hl是第l层的隐藏表示,p(y|hl)是条件概率。
21、作为优选,步骤2中,具体为:使用四块结构的resnet作为视觉编码器,yolov5x6作为对象检测器;最多保留置信度得分最高的三个区域ob=(o1,o2,…,oz);
22、多尺度图像输入被馈送到视觉编码器中,在视觉编码器中对深层信息进行上采样并逐元素添加浅层信息;此过程提取多尺度特征图f=(f1,f2,…,fr);随后,执行平均池化操作以增强图像内视觉方面的识别能力:
23、
24、
25、其中[f1,f2,…,fr]g和表示通过融合多尺度特征图获得的视觉特征,包括全局图像特征和对象特征;ave表示将fi投影到相同尺寸的平均池化层;表示第l个多尺度视觉融合特征。
26、作为优选,步骤2中,采用anp检测器作为视觉方面和意见的监督,使用具有前n个预测概率的形容词-名词对,前n个预测的分布p计算为:
27、
28、其中r=4,其中w∈rd×n和b∈rn表示可训练参数,d表示bert中文本表示的维度;
29、为了使预测的分布p更接近于最真实的top-n形容词-名词对分布a,使用标准的交叉熵损失lv来从图像输入中找到细粒度信息:
30、lv=-alog(p)
31、此损失能减少预测分布和基本事实分布之间的差异。
32、作为优选,步骤2中,利用动态注意力机制将多层次视觉信息作为prompt投射到文本模态中的bert的第l层;通过动态投影仪计算多个归一化向量,这些向量决定bert内每个块的视觉特征变换程度;首先,计算logits作为映射信号量:
33、
34、其中,mlp表示特征降维层;采用多头自注意力将转换后的多尺度视觉特征与bert各层上下文表征的键/值向量相结合;表示第k个多尺度视觉融合特征,其中,表示转换后的多尺度视觉特征输入到bert的第l层;
35、
36、表示权重矩阵,表示多尺度视觉融合特征经过多头自注意力并降维所得到转换后的特征拆分成两个部分;
37、然后,这些转换后的视觉特征与bert中前一层的原始关键字和值向量连接,后者在注意力过程中充当新的键和值;视觉提示与基于文本的融合注意力的计算如下:
38、
39、其中,以及分别代表新注意力矩阵中的查询、键和值。
40、作为优选,步骤3中,将输出馈送到bert模型中得到的概率分布的kl-散度最小化,相当于计算这两个分布的交叉熵损失:
41、
42、其中和是概率分布;
43、损失函数是真实标签序列的负对数似然函数,如下所示:
44、
45、最终的目标函数定义如下:
46、lmtvaf=λ·lt+μ·lv+γ·lt+v
47、其中λ、μ和γ∈[0,1]是用于控制每个模块的贡献的超参数。
48、本发明提出了以文本为核心,将图像作为辅助信息,通过分层特征提取的方式将图像的多粒度信息注入到文本的预训练模型中。由于图像中所存在的物体信息的大小方差往往十分悬殊,采用特征金字塔所具备的不同尺寸的感受野,并采用动态注意力机制将分层视觉特征融合到bert中的每一层中。
49、本发明设计的多层次对齐模块,可以在融合前将视觉模态的语义空间与文本空间相对齐。由于两模态的语义偏差过大,本发明提出图像从全局、局部以及字符的粒度转译成文本。利用图像描述模型、人脸属性模板以及ocr引擎得到三种粒度的视觉上下文可以弥合模态间的语义鸿沟,为了减少无关的视觉上下文的误导作用,通过最小化文本输出空间与文本+图像上下文输出空间的kl损失,来降低视觉噪音对文本表示预测结果的影响。
50、本发明设计的通用多模态对齐与融合不仅有效利用了图像模态的内容,还在预训练模型的训练过程中对齐并融合了各自模态的重要信息,进一步提升了属性级情感分析的能力。
- 还没有人留言评论。精彩留言会获得点赞!