用于问答检索模型的训练方法、装置及存储介质与流程
本技术涉及自然语言处理,具体地涉及一种用于问答检索模型的训练方法、装置及存储介质。
背景技术:
1、问答场景是一种基于自然语言的人机交互方式,其可根据用户的问题提供相关的答案。目前,在训练问答检索模型时,先构造正负样本,使用infonce loss(对比学习损失函数)训练模型。之后,可进行信息最小化,利用对比学习做损失训练。接着,可进行正负样本重构,并计算最小信息熵。最后,可进行句子表征学习,并通过下游任务评测模型。
2、然而,针对长文本而言,其答案长度存在差异,若直接采用长文本对模型进行训练,损失函数波动大。尤其发生在重构之后,在温度参数和批量大小控制不变的情况下,长文本负样本的损失函数波动更大。且,在利用对比学习做损失训练之后,计算对比损失函数,对比损失函数权重的取值大小对结果影响也较大。因此,现有技术中采用长文本训练问答检索模型的技术方案,导致训练完成的问答检索模型性能较低,使得后续问答检索的准确率较低。
技术实现思路
1、本技术实施例的目的是提供一种用于问答检索模型的训练方法、装置及存储介质,用以解决现有技术中问答检索模型性能较低的问题。
2、为了实现上述目的,本技术第一方面提供一种用于问答检索模型的训练方法,问答检索模型包括编码器和对抗网络,包括:
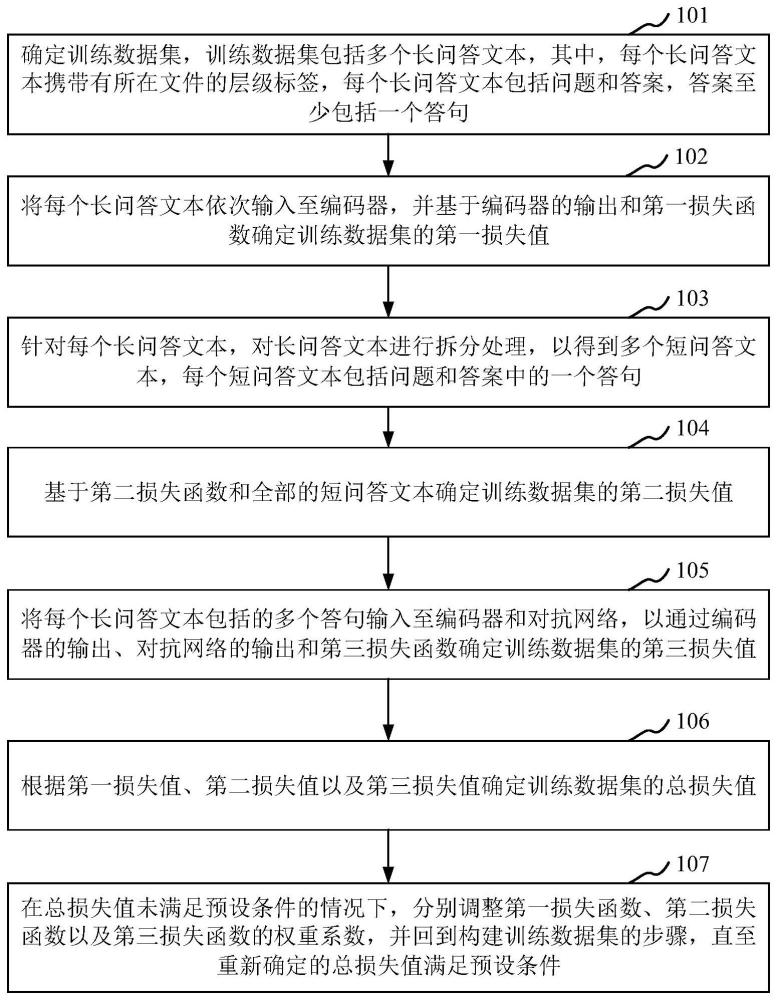
3、确定训练数据集,训练数据集包括多个长问答文本,其中,每个长问答文本携带有所在文件的层级标签,每个长问答文本包括问题和答案,答案至少包括一个答句;
4、将每个长问答文本依次输入至编码器,并基于编码器的输出和第一损失函数确定训练数据集的第一损失值;
5、针对每个长问答文本,对长问答文本进行拆分处理,以得到多个短问答文本,每个短问答文本包括问题和答案中的一个答句;
6、基于第二损失函数和全部的短问答文本确定训练数据集的第二损失值;
7、将每个长问答文本包括的多个答句输入至编码器和对抗网络,以通过编码器的输出、对抗网络的输出和第三损失函数确定训练数据集的第三损失值;
8、根据第一损失值、第二损失值以及第三损失值确定训练数据集的总损失值;
9、在总损失值未满足预设条件的情况下,分别调整第一损失函数、第二损失函数以及第三损失函数的权重系数,并回到确定训练数据集的步骤,直至重新确定的总损失值满足预设条件。
10、在本技术实施例中,基于第二损失函数和全部的短问答文本确定训练数据集的第二损失值包括:对每个短问答文本中的答句进行清洗处理;
11、确定每个清洗后的短问答文本中的问题与其答句之间的余弦相似度;从每个长问答文本包括的多个清洗后的短问答文本中任意选定一个短问答文本作为目标文本;针对每个目标文本,确定目标文本包括的问题中的每个关键词在每个层级标签下的词频值和逆文本频率指数;基于第二损失函数,根据全部目标文本对应的多个词频值和多个逆文本频率指数,以及全部的余弦相似度确定训练数据集的第二损失值。
12、在本技术实施例中,基于第二损失函数,根据全部目标文本对应的多个词频值和多个逆文本频率指数,以及全部的余弦相似度确定训练数据集的第二损失值包括:根据全部目标文本所对应的多个词频值和多个逆文本频率指数确定训练数据集的总词频值和总逆文本频率指数;针对每个长问答文本,确定出多个余弦相似度中数值最大的余弦相似度;基于第二损失函数,并根据总词频值、总逆文本频率指数以及每个长问答文本的余弦相似度最大值确定第二损失值。
13、在本技术实施例中,每个长问答文本携带有所在一级文件的一级标签和所在二级文件的二级标签,第二损失函数的表达式由公式(1)定义:
14、
15、其中,loss1是指第二损失函数的第二损失值,qa是指长问答文本的总数量,k是指每个目标文本包括的问题中的关键词的总数量,λ21是指与一级标签所对应的第一加权权重,是指每个关键词在一级标签下的词频值,是指每个关键词在一级标签下的逆文本频率指数,λ22是指与二级标签所对应的第二加权权重,是指每个关键词在二级标签下的词频值,是指每个关键词在二级标签下的逆文本频率指数,λ2是指第二损失函数的权重系数,i是指第i个清洗后的短问答文本,i的取值范围为1~z,z是指清洗后的短问答文本的总数量,q是指每个清洗后的短问答文本中的问题所对应的向量,y(i)是指每个清洗后的短问答文本中的答句所对应的向量,sim(q,y(i))是指每个清洗后的短问答文本中的问题与其答句之间的余弦相似度。
16、在本技术实施例中,对抗网络包括生成器和鉴别器,将每个长问答文本包括的多个答句输入至编码器和对抗网络,以通过编码器的输出、对抗网络的输出和第三损失函数确定训练数据集的第三损失值包括:针对每个长问答文本对应的多个答句,按照预设掩码比例对每个答句进行掩码处理,以得到多个掩码处理后的答句;将每个掩码处理后的答句输入至生成器,以使生成器输出与每个掩码处理后的答句所对应的新答句;针对每个长问答文本对应的多个答句,将每个答句输入至编码器,以使编码器输出与每个答句对应的第一文本向量;将每个新答句的第二文本向量和对应答句的第一文本向量输入至鉴别器,以使鉴别器输出针对每个新答句的判别结果;针对每个长问答文本对应的全部新答句,根据全部新答句的判别结果确定生成器针对每个长问答文本的正确率;基于第三损失函数和全部的正确率确定训练数据集的第三损失值。
17、在本技术实施例中,第三损失函数的表达式由公式(2)定义:
18、
19、其中,loss2是指第三损失函数的第三损失值,λ3是指第三损失函数的权重系数,qa是指长问答文本的总数量,a是指每个长问答文本对应的答句的总数量,n是指每个长问答文本对应的每个答句中被掩码的词汇数量,p是指生成器输出全部新答句的正确率,mx是指每个答句中第x个被掩码的词汇,ay是指每个长问答文本的第y句答句。
20、在本技术实施例中,将每个长问答文本依次输入至编码器,并基于编码器的输出和第一损失函数确定训练数据集的第一损失值包括:针对每个长问答文本,按照预设次数将长问答文本依次输入至编码器,以使编码器依次输出与长问答文本对应的文本向量;将同一长问答文本的文本向量组成的向量对确定为正例,并将不同长问答文本的文本向量组成的向量对确定为负例;基于第一损失函数,并根据全部长问答文本所对应的正例数量和负例数量确定训练数据集的第一损失值。
21、在本技术实施例中,第一损失函数的表达式由公式(3)所示:
22、
23、其中,loss3是指第一损失函数的第一损失值,λ1是指第一损失函数的权重系数,qa是指长问答文本的总数量,是指第m个长问答文本所产生的正例数量,(km,kn)是指第m个长问答文本和第n个长问答文本所产生的负例数量,τ是指温度系数,q是指相似度计算参数。
24、本技术第二方面提供一种用于问答检索模型的训练装置,包括:
25、存储器,被配置成存储指令;以及
26、处理器,被配置成从存储器调用指令以及在执行指令时能够实现上述的用于问答检索模型的训练的方法。
27、本技术第三方面提供一种机器可读存储介质,该机器可读存储介质上存储有指令,该指令用于使得机器执行上述的用于问答检索模型的训练方法。
28、上述技术方案,考虑到长问答文本的整体对问答检索模型训练的影响,将每个长问答文本依次输入至编码器,并基于编码器的输出和第一损失函数确定训练数据集的第一损失值。考虑到长问答文本的答案中每个答句的发散性和代表性,将长问答文本拆分为多个短问答文本,并基于第二损失函数和全部的短问答文本确定训练数据集的第二损失值。考虑到长问答文本由于掩码过于集中而导致损失函数波动较大,将每个长问答文本包括的多个答句输入至编码器和对抗网络,以通过编码器的输出、对抗网络的输出和第三损失函数确定训练数据集的第三损失值,根据第一损失值、第二损失值以及第三损失值确定训练数据集的总损失值,并基于总损失值调整各个损失函数的权重系数,以全面地对模型进行训练,训练完成的问答检索模型性能更佳,提高后续问答检索的准确度。
29、本技术实施例的其他特征和优点将在随后的具体实施方式部分予以详细说明。
- 还没有人留言评论。精彩留言会获得点赞!