构建基于电网相关文件的知识图谱的方法、装置及介质与流程
本发明属于语言处理,特别涉及构建基于电网相关文件的知识图谱的方法、装置及介质。
背景技术:
1、知识图谱(kg)是一种结构化的、语义化的知识表示模型,用于描述现实世界中的实体、概念、关系和属性,并以图的形式表示它们之间的关联。知识图谱在许多应用领域都具有巨大的潜力,它以可视化的方式提供了信息组织、信息检索、知识管理与共享等功能。电力行业发展时间长、体量大,是国民经济重要的基础行业,基于电网相关文件构建知识图谱,可以促使相关业务人员充分理解和应用相关文本,大幅提高工作效率,对于文档级知识图谱构建具有代表意义。然而,由于电网相关文件信息复杂、涉及广泛,无法利用现有的模型构建满足实际需求的知识图谱。现有的模型存在如下问题:(1)实体识别受限:对于实体识别问题,特别是文档级的多实体问题难以有效识别;(2)关系提取有困难:构建知识图谱需要大量的关系抽取工作,现有技术对文档级的关系抽取难度较大;(3)知识表示有局限性:现有知识图谱广泛使用三元组(实体、关系、属性)表示知识,但这种方式难以应对文档级的多事实与主题分类的任务。因此,有必要改进现有的知识图谱模型来适应电网领域的需求。
技术实现思路
1、针对现有模型不能处理电网相关文件的实际使用要求的问题,本发明提种构建基于电网相关文件的知识图谱的方法、装置及介质,能够有效识别文档级的多实体,能够提取跨句子的实体间关系,还能明确不同实体与关系间的主题分类。
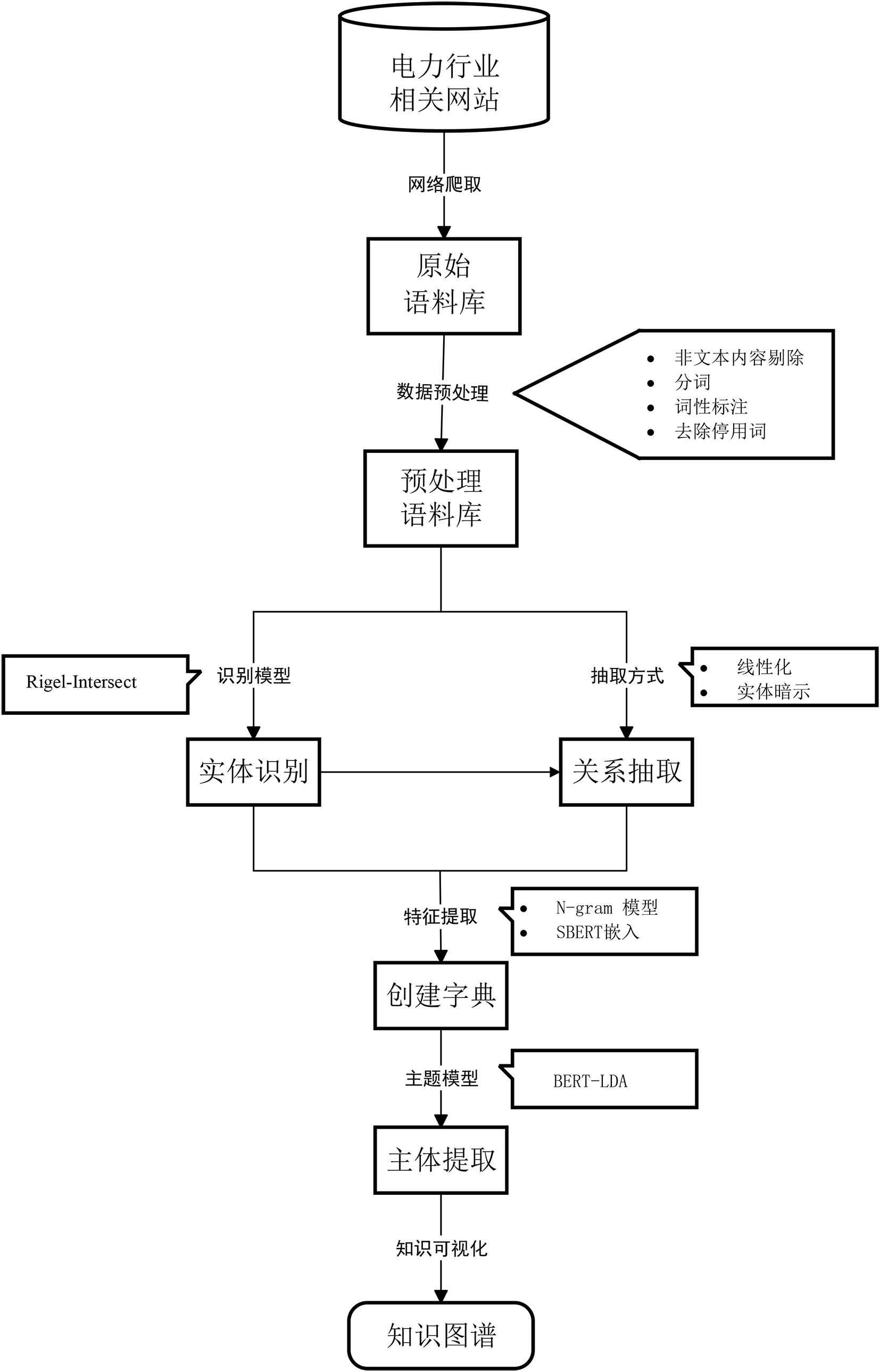
2、本发明采用技术方案如下:构建基于电网相关文件的知识图谱的方法,包括以下步骤:
3、步骤1,搜集电网相关文件获得原始语料库,预处理原始语料库的文本,获得预处理语料库,同时预定义实体集合和关系集合,用于收集语料库中的名称;基于预定义的实体集合处理预处理语料库,获得带有标记实体答案的语料库;
4、步骤2,基于带有标记实体答案的语料库,使用rigel-intersect模型进行多实体识别;
5、步骤3,基于多实体识别结果,通过基于实体暗示的seq2seq模型进行关系提取;
6、步骤4,构建基于lda-bere的提取模型,根据多实体识别结果和关系提取结果进行语义主题提取;
7、步骤5,将结果进行可视化。
8、进一步地,步骤1的很具体过程为:
9、步骤1.1,搜集关于电力行业的相关的文件,形成原始语料库;
10、步骤1.2,对原始语料库进行非文本内容剔除,使用jieba分词对原始语料库中的文本进行中文分词,依据分词结果对单词进行词性标注,并去除文本中常见的中文停用词,得到预处理语料库。非文本内容包括额外空格、标点符号;
11、步骤1.3,预定义实体集合和关系集合,基于预定义实体集合对预处理语料库进行数据标注,得到带有标记实体答案的语料库。
12、进一步地,步骤2具体过程为:
13、步骤2.1,构建rigel-baseline模型进行单实体识别;
14、所述rigel baseline模型包括一个编码器和一个解码器,使用编码器对问题进行编码,使用解码器返回可微知识图谱上关系的概率分布;
15、步骤2.2,通过可微分相交运算扩展rigel-baseline模型构建rigel-intersect模型,进行多实体识别;
16、步骤2.2.1,通过构建两个向量的交集,识别两个实体之间的共享元素;
17、步骤2.2.2,使用编码器将问题文本编码形成问题嵌入,作为模型编码器的roberta输入;对于每个问题实体,将问题文本与实体提及或规范名称用分隔符标记分隔连接起来;使用分隔符标记索引的嵌入作为问题的实体特定表示;
18、步骤2.2.3,获得一句话中多实体识别结果:
19、(a)使用解码器对每个实体特定问题嵌入并行预测推理,根据可微知识图谱中的实体和关系获得中间答案;
20、(b)根据注意力得分对每个向量中的实体进行加权;
21、(c)将两个中间答案相交以获得最终答案,作为问题的回答;根据最终答案和标记实体答案之间的差异计算损失,使得编码器和解码器根据损失结果调整参数;
22、该步骤提供一种文档级实体识别方式,实现一个新的交集操作来显式地处理多实体问题,识别两个实体之间的共享元素,实现端对端的问答,用以证明引入交集可以提高网络问题和复杂的网络问题的性能。
23、进一步地,步骤2.1具体过程为:
24、步骤2.1.1,定义实体关系集合表达式;
25、步骤2.1.2,根据实体关系集合,构建所有预处理语料库中存在的三元组的集合;
26、步骤2.1.3,基于矩阵运算构建单实体识别模型:
27、s2.1.3.1,给定实体向量表达式:
28、s2.1.3.2,给定问题嵌入和关系向量,计算实体向量;问题实体和预测关系在可微知识图谱中被跟踪,以返回预测答案;
29、s2.1.3.3,计算跳跃注意力得分,将关系向量和实体向量进行关联,并更新实体向量;
30、s2.1.3.4,通过构建损失函数,更新单实体识别模型参数。
31、进一步地,步骤3具体过程为:
32、步骤3.1,基于步骤2的结果,将源文本线性化为字符串;
33、步骤3.2,添加实体暗示:当实体出现在输入句子中时,将实体及其识别名称加入到源文本之前,以特殊标记划分实体提示的末尾;
34、步骤3.3,基于字符串和实体暗示,构建序列到序列模型。
35、进一步地,步骤3.1具体过程为:
36、步骤3.1.1,限制目标词汇:限制目标词汇表为建模实体和关系所需的一组特殊标记,以防止模型生成未出现在源文本中的实体提及;
37、步骤3.1.2,复制机制:所有其他标记使用复制机制从输入中复制,该机制的工作原理是使用源序列中的标记扩展目标词汇表,允许模型将这些标记复制到输出序列中,并随机初始化特殊标记的嵌入,与模型的其他参数一起学习;
38、步骤3.1.3,结束解码:通过将错误答案的预测概率设置为微小值来应用对解码器的约束;在测试期间对解码器应用约束进行实验,用以降低生成语法无效的目标字符串(不遵循线性化模式的字符串)的可能性;
39、步骤3.1.4,关系排序:根据目标字符串在源文本中的出现顺序对它们之间的关系进行排序,为模型提供一致的解码顺序。
40、进一步地,步骤4的具体过程为:
41、步骤4.1,特征提取:通过n-gram算法提取步骤3的结果获得单词,并基于sbert模型创建句子嵌入;
42、步骤4.2,创建字典:将步骤4.1提取的单词映射id,并生成文档列表,将文档列表转化为单词矩阵,用作lda模型的输入;
43、步骤4.3,主题建模:对单词矩阵进行矢量化,并将步骤4.1获得的sbert模型对于句子的操作转换成对于文档的操作,将每个文档的sbert嵌入与该文档对应的单词矩阵行进行拼接,以创建一个新的文档表示。
44、进一步地,步骤5具体过程为:将步骤4结果保存在excel表中,使用知识图谱构建软件进行可视化。
45、一种构建基于电网相关文件的知识图谱的装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现上述构建基于电网相关文件的知识图谱的方法。
46、一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述的构建基于电网相关文件的知识图谱的方法。
47、本发明具有的有益效果:本技术为构建基于电网相关文件的知识图谱的方法、装置及介质,利用交集操作来显式地处理多实体问题,解决现有模型实体识别受限的问题;结合实体暗示,实现实体输入的关系提取,能够改善现有模型文档级关系抽取难度大的问题,通过结合lda-bert的混合模型,用于语义主题的提取划分。本发明能够在文档级的实体识别和关系提取基础上再进行语义主题的提取划分,从而提高知识图谱的信息承载量和信息检索效能,使得知识图谱能够适应文档级文件处理,保证知识图谱能够适应电网文件处理的需求。
- 还没有人留言评论。精彩留言会获得点赞!