一种挖掘稀有高山植被品种存在形式及生长区域的方法
本发明属于区域空间数据挖掘,特别是涉及一种挖掘稀有高山植被品种存在形式及生长区域的方法。
背景技术:
1、随着基于位置的服务和空间数据采集技术的快速发展,数据挖掘已经从传统的事务型数据库扩展到了空间数据库。如何从海量高维度的空间数据中挖掘潜在有趣的知识,并以此来指导决策变得至关重要。空间同位模式挖掘是空间数据挖掘领域的一个非常重要的研究方向。空间同位模式指的是一组空间特征组成的集合,它能够发现不同空间特征之间的隐含关系,而这些特征通常具有较强的地理相关性。例如学校周围的许多社区、医院周围的药店、商场周围的停车场等。由于空间数据分布的异质性,一些空间同位模式可能只分布在一些特定区域。区域同位模式挖掘是空间同位模式挖掘的一个分支,用于发现在全局空间范围内不频繁共现,但在局部区域内频繁共现的同位模式。例如,在公共卫生领域,某个地区的恶性肿瘤总体患病率似乎并不高,但在工业污染重的区域,恶性肿瘤的患病率尤其高。在城市安全领域,城市的高犯罪率主要集中在市中心的酒吧附近,其他区域则没有这种现象。这种隐含的区域性的关联关系称为区域频繁空间同位模式,区域频繁空间同位模式表示在研究区域的某些子区域中频繁位于一起的空间特征的子集。区域同位模式挖掘可以发现那些隐含在局部区域的空间特征之间的关联关系,更客观地反映这些空间特征在局部区域呈现出的规律,这对包括城市区域规划、环境保护和社会治理等具有指导性。
2、通过参考现有研究和大量的调研,发现导致区域性的产生或者区域同位模式形成的原因大致可归类为以下三种:1)地理因素天然形成,如山脉、河流等;2)人为划分形成,如自然保护区、生态基地等;3)由于特征之间的关联关系而聚集形成,如依附关系(藤曼依附大树获取阳光)等。而现有的区域划分方法并没有完全考虑到以上三种因素,现有的方法主要有以下三种,基于聚类的方法,基于规则划分的方法,以及基于网络约束的方法(如路网和地图等先验信息)。其中,基于聚类和基于规则划分的方法主要考虑实例之间的邻近关系,其核心思想认为地理邻近的实例之间具有更强的相关性,对于挖掘由地理因素形成的区域同位模式有较好的效果。基于网络约束的方法需要指定先验信息,如土地覆盖信息,辖区信息等,这对挖掘区域同位模式十分有帮助,但是缺乏针对由于特征之间的关联和约束而形成的区域同位模式的相关研究。
3、由特征之间的关联而形成的区域同位模式对发现高山植被中稀有品种的存在形式及其生长区域有着重要的研究意义,因此本发明提出了一种区域核模式挖掘方法用于发现稀有高山植被存在形式及生长区域。区域核模式可以用于发现子局部区域中由于核特征的存在导致的空间同位关系,如患有癌症的群体在现实中通常属于稀有群体,那么以癌症作为稀有资源可以推导出导致癌症的污染源。同时,由于空间数据具有空间分布和特征实例数量分布的双重异质性,一些空间特征本身就呈现出局部分布属于稀有特征。在实际应用中,与其在全局范围内搜索那些关注度不高的区域同位模式,发现那些包含稀有特征的核模式更具有研究意义和应用价值。例如,大熊猫作为濒危物种和国家一级保护动物,为野生大熊猫提供合适的栖息环境对保护大熊猫具有重要意义。如果以大熊猫为核特征,基于其空间分布识别出其栖息地,在栖息地中挖掘与大熊猫具有强关联关系的核模式,可以准确地发掘大熊猫的栖息习性和栖息环境等信息,这对寻找野生大熊猫新的栖息地具有指导作用。
4、此外,在现有的相关研究中多采用欧氏距离来度量两个空间实例之间是否邻近,但是这种定值定量的度量方法存在一些缺陷。对于不同的空间数据集,其实例分布密度有所差异,并且对于同一个数据集中不同的空间特征,其实例分布密度也会有明显差异。因此,选择一个合适的距离阈值需要用户对数据集有一个充分的了解,并掌握相关领域的先验知识,这显然是难以实现的。同时在实际应用中,无论是在生态保护还是城市规划中,相同类型特征的实例之间往往存在竞争关系(如生态学领域中的一山不容二虎现象,城市规划领域中两个同类型的超市往往间隔几个街区而不是相邻)。因此,本发明提出了核邻近归属度量,用于替换传统的基于距离阈值的度量方法。采用核邻近归属度量不仅可以取代传统的距离阈值度量方式,还能一定程度上解决空间实例间复杂的耦合关系。
技术实现思路
1、本发明实施例的目的在于提供一种挖掘稀有高山植被品种存在形式及生长区域的方法,以解决技术中缺少对稀有高山植被品种存在形式及生长区域的挖掘方法,以及传统的距离阈值度量方法存在有缺陷的问题。
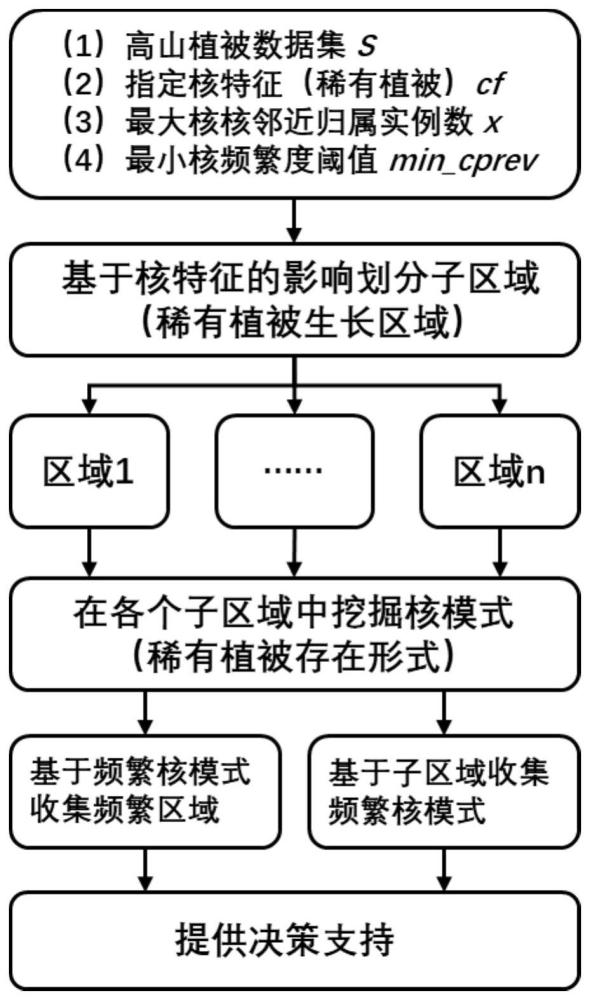
2、为解决上述技术问题,本发明所采用的技术方案是,一种挖掘稀有高山植被品种存在形式及生长区域的方法,包括以下步骤:
3、步骤s1、建立包含稀有高山植被品种的空间数据集,获得空间特征集f;
4、步骤s2、在空间数据集中筛选核特征,基于所述核特征的分布影响进行子区域划分;所述核特征为稀有高山植被品种;
5、步骤s3、在划分得到的各个子区域中挖掘频繁核模式;所述核模式c为空间特征集f中一个k阶子集,其中c必须包含核特征cf(cf∈f);所述核模式指包含稀有高山植被品种的空间同位模式;
6、步骤s4、收集所有子区域中的频繁核模式,建立高山植被品种存在形式及生长区域的查询字典;
7、步骤s5、基于所建立查询字典,查询稀有高山植被品种存在形式及生长区域挖掘结果。
8、进一步地,所述步骤s1具体为:
9、建立一个空间数据集,数据集中的每种植被类型组合成空间特征集f={f1,f2,...,fn},n表示特征类别的个数;其中每种特征类别都包含一组特征实例,分布在空间中不同的位置;所有的特征实例构成空间实例集s=s1∪s2∪...∪sn,第i个空间实例表示为oi,oi∈s,通过一个三元组<所属特征类别,实例号,空间位置>描述,其中,实例号表示所述空间实例在所属特征类别的所有实例中的序号,空间位置指所述空间实例所在的空间位置;所述空间实例oi表示一棵实际生长的高山植被。
10、进一步地,所述步骤s2中核特征的选择方法为:
11、利用代码或者在线工具生成空间数据集中所有特征在水平分布和垂直分布上的箱线图,所述箱线图中,四分位数区间越窄或中位数偏差越大的特征为核特征。
12、进一步地,所述步骤s2中的子区域划分方法为:
13、首先计算分区距离阈值pd,然后基于每个核实例和分区距离阈值pd,将与其邻近的所有实例加入自身形成的集合;判断集合中是否包含其它特征实例,如果不包含其他特征实例则说明当前区域内只有核实例,该集合将会被舍弃;最后将包含有相同实例的集合进行合并,得到最终的子区域划分结果;
14、所述分区距离阈值pd设置为1.5×rd到2×rd之间,其中,rd为核实例之间的相对距离:
15、
16、其中,dist_min(coi)计算核实例coi的最小竞争距离,i为第i个核实例,m表示所有核实例的总数;
17、所述核实例为稀有高山植被品种的一个实例。
18、进一步地,所述步骤s3包括:
19、步骤s31、构建存储结构core_hash;
20、步骤s32、基于core_hash结构挖掘频繁核模式;
21、所述存储结构core_hash构建方法如下:
22、对于每个非核实例,遍历所有核实例,并确定当前非核实例是否满足与核实例的邻近关系;如果满足,则将对应信息加入到core_hash中,如果core_hash的键中已经包含当前核实例,则直接将与当前核实例相邻的非核实例添加到对应的特征表中;最终得到core_hash结构;
23、所述核实例为稀有高山植被品种的一个实例,所述非核实例为非稀有高山植被品种的一个实例。
24、进一步地,所述非核实例是否满足与核实例的邻近关系的判断方法为:
25、给定一个最大核邻近归属数x,对于一个非核实例,所述非核实例最大可以归属于与其最近的x个核实例。
26、进一步地,所述步骤s32具体为:
27、首先根据core_hash得到2阶频繁的核模式,用2阶频繁的核模式组合生成3阶候选核模式;基于core_hash计算所有候选核模式的核参与度,在候选核模式中找出频繁的核模式,并重复“k阶频繁核模式生成k+1阶候选核模式,再判断k+1阶候选核模式是否频繁”,直到生成的候选核模式为空,最终得到所有频繁的核模式;
28、所述核模式是否频繁的判断方法为:
29、通过计算得到核模式的核参与度cpi(r,c),给定最小核参与度阈值min_cprev,如果cpi(r,c)≥min_cprev,则称核模式c在区域r中是一个频繁的核模式,区域r称为核模式c的频繁区域。
30、进一步地,所述步骤s4具体包括:
31、步骤s41、对于收集好的所有频繁核模式,建立一个查询字典结构{核模式:{所有频繁子区域}};
32、步骤s42、对于步骤2中划分好的所有子区域,建立另一个查询字典结构{子区域:{所有频繁核模式}}。
33、本发明的有益效果是:
34、首先,本发明通过挖掘区域核模式揭示稀有高山植被品种的存在形式并发现其频繁存在的区域,填补了现有方法的不足;其次,本发明提供了两种邻近关系度量方式下的挖掘方法,可以适应于各种应用背景下的空间数据集;然后,本发明针对区域划分阶段和模式挖掘阶段均做了技术上的优化,大幅度提升了挖掘效率;最后,通过具体的实施例可以看出,本发明方法的挖掘效果优于现有方法,不仅能发现到更多稀有高山植被品种的存在形式,还能找到其更全面的生长区域,兼顾效率的同时还有出色的效果。
- 还没有人留言评论。精彩留言会获得点赞!