基于虚拟数字人交互处理方法、系统、终端、设备及介质与流程
本发明涉及人工智能,具体涉及一种基于虚拟数字人交互处理方法、系统、终端、设备及介质。
背景技术:
1、虚拟数字人(digital human/meta human),是运用数字技术创造出来的、与人类形象接近的数字化人物形象,随着人工智能技术、5g通信技术和人际交互方式的飞速发展,虚拟数字人得到了越来越好的呈现,在多个场合进行了应用并取得了成功。
2、大模型,是指包含数千亿(或更多)参数训练而成的人工智能模型,例如,以chatgpt(chat generative pre-trained transformer,聊天机器人程序)为代表,正迅速地应用于各行各业,加速了人工智能(ai)技术的普及,使ai成为我们工作和生活中不可或缺的一部分。毋庸置疑,这些大模型技术已经深刻地影响并改变了各行业的发展,正在重构企业核心产品,并改变用户与企业产品和服务之间的交互方式。
3、然而,在相关技术中,当前的虚拟数字人虽然可以大量替代标准化的人工服务,但是都是基于某一类客户的基础建立的客户模型、具有标准的客服问答库、具有标准的业务处理流程等,不管针对哪一类用户来讲,所有的互动答复都是千篇一律的,具有片面性,缺乏一种基于大模型与虚拟数字人有效结合的交互处理,以提高对话准确性与交互体验。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供基于虚拟数字人交互处理方法、系统、终端、设备及介质,用于解决现有技术基于大模型与虚拟数字人缺乏有效结合,导致交互体验与对话匹配度不够的问题。
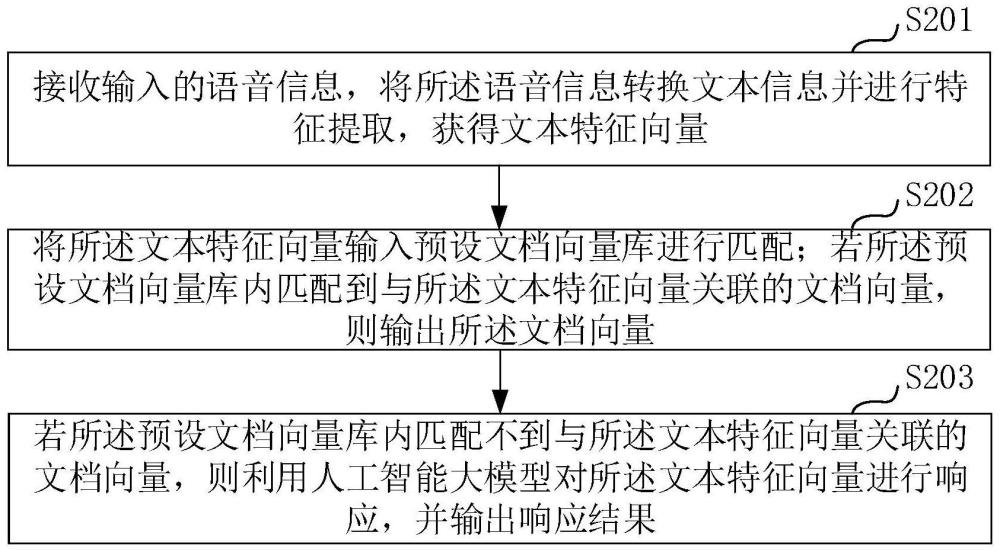
2、在第一方面,为实现上述目的及其他相关目的,本发明提供一种基于虚拟数字人交互处理方法,所述基于虚拟数字人交互处理方法包括:接收输入的语音信息,将所述语音信息转换文本信息并进行特征提取,获得文本特征向量;将所述文本特征向量输入预设文档向量库进行匹配;若所述预设文档向量库内匹配到与所述文本特征向量关联的文档向量,则输出所述文档向量;若所述预设文档向量库内匹配不到与所述文本特征向量关联的文档向量,则利用人工智能大模型对所述文本特征向量进行响应,并输出响应结果。
3、于第一方面的一些实施例中,根据以下特征数据至少之一:预设外形特征数据、预设动作特征数据、预设表情特征数据、预设声纹特征数据,对应构建虚拟数字人的以下模型至少之一:外形模型、动作模型、表情模型、语音模型,融合至少一个模型获得所述虚拟数字人。
4、于第一方面的一些实施例中,构建所述虚拟数字人的运行调度引擎,利用所述运行调度引擎识别待输出文本的情绪类别,确定所述情绪类别对应表情动作,以使所述虚拟数字人执行相应表情与动作。
5、于第一方面的一些实施例中,所述接收输入的语音信息之前,还包括:若监听到预设语音信息或检测到人脸图像,则对所述虚拟数字人进行唤醒,以使所述虚拟数字人进入人机交互状态。
6、于第一方面的一些实施例中,所述检测到人脸图像之后,还包括:将所述人脸图像与预设人像库进行比对,获得用户身份信息;若所述用户身份信息为熟人,则控制所述虚拟数字人的眼睛跟随所述用户进行移动,并使用语音模型对预设打招呼文本进行声音合成,生成打招呼音频,同时,识别所述预设打招呼文本的情绪类别,调用所述动作模型与所述表情模型确定所述情绪类别所对应的表情动作,以使所述虚拟数字人执行相应表情与动作并播放所述打招呼音频。
7、于第一方面的一些实施例中,所述在将所述文本特征向量输入预设文档向量库进行匹配之前,还包括:将所述文本特征向量输入到预设敏感词库对进行匹配;若所述文本特征向量含有敏感词,则识别所述文本特征向量中敏感词类别,根据所述敏感词类别确定预设敏感文本,以使虚拟数字人按照所述预设敏感文本进行响应;若所述文本特征向量不含有敏感词,则触发所述文本特征向量在预设文档向量库进行匹配。
8、于第一方面的一些实施例中,将所述语音信息转换文本信息并进行特征提取,获得文本特征向量,还包括:将所述语音信息转换文本信息,对所述文本信息进行意图识别,确定用户意图;提取所述文本信息中的实体,获得实体信息;将所述实体信息与所述用户意图输入人工智能大模型确定第一提示词,将所述第一提示词保存到所述文本信息形成新的文本信息,其中,所述第一提示词为文本表达含义信息;对所述新的文本信息进行特征提取,获得文本特征向量。
9、于第一方面的一些实施例中,将所述语音信息转换文本信息并进行特征提取,获得文本特征向量,还包括:将所述语音信息转换文本信息,对所述文本信息进行意图识别,确定用户意图;提取所述文本信息中的实体,获得实体信息;将所述实体信息与所述用户意图输入人工智能大模型确定第一提示词,接收用户响应于所述用户提示词生成的第二提示词,利用所述第二提示词更新所述文本信息形成新的文本信息,其中,第一、二提示词分别为文本表达含义信息;对所述新的文本信息进行特征提取,获得文本特征向量。
10、于第一方面的一些实施例中,所述利用人工智能大模型对所述文本特征向量进行响应,并输出响应结果,还包括:确定所述文本特征向量所对应的用户意图与语义信息;根据所述用户意图与所述语义信息加载所述人工智能大模型关联的预设插件与预设提示词模板,确定所述预设插件的插件描述以及插件参数;将所述插件描述以及插件参数加载到所述预设提示词模板内形成提示信息;其中,所述提示词模板承载所述插件以及定义输入、输出的标准格式;对所述提示信息进行指令理解,确定待执行的业务类型以及应用程序接口,根据所述业务类型以及所述应用程序接口调用相应插件对所述文本特征向量进行响应,并将所述响应结果进行输出。
11、于第一方面的一些实施例中,所述根据所述用户意图与所述语义信息加载所述人工智能大模型关联的预设插件与预设提示词模板之前,还包括:注册插件,对所述注册插件添加插件名称、功能描述以及插件参数,持久化所述注册插件,其中,所述人工智能大模型能够基于所述功能描述推理到所述插件名称,还能根据所述插件名称以及所述插件参数完成所述人工智能大模型与所述插件的链接。
12、于第一方面的一些实施例中,包括:利用预设训练样本对预设深度学习模型进行训练,调整所述预设深度学习模型的参数进行优化直至达到预设验证条件,获得至少一个人工智能大模型。
13、于第一方面的一些实施例中,所述若所述预设文档向量库内匹配到与所述文本特征向量关联的文档向量,则输出所述文档向量,包括:根据所述文本特征向量分别对各所述文档向量进行相似度计算,得到所述文本特征向量分别与各所述文档向量之间的向量相似度;根据所述向量相似度从所述预设文档向量库中确定与所述文本特征向量关联的文档向量。
14、于第一方面的一些实施例中,构建所述预设文档向量库,包括:预先获取初始文档数据,对所述初始文档数据进行拆分,得到多个文本片段,并生成各所述文本片段对应的文本向量;根据所述文本片段和所述文本向量之间的对应关系建立预设文档向量库。
15、于第一方面的一些实施例中,对所述初始文档数据进行拆分,得到多个文本片段,包括:
16、根据预设的文档切分粒度将所述初始文档数据切分为多个文本数据块;根据预设的切分字符分别从各所述文本数据块中确定文本分割位置;根据所述文本分割位置将所述初始文档数据拆分为多个文本片段。
17、在第二方面,为实现上述目的及其他相关目的,本发明提供一种基于虚拟数字人交互处理系统,所述基于虚拟数字人交互处理系统包括:文本转换模块,用于接收输入的语音信息,将所述语音信息转换文本信息并进行特征提取,获得文本特征向量;第一交互模块,用于将所述文本特征向量输入预设文档向量库进行匹配;若所述预设文档向量库内匹配到与所述文本特征向量关联的文档向量,则输出所述文档向量;第二交互模块,用于若所述预设文档向量库内匹配不到与所述文本特征向量关联的文档向量,则利用人工智能大模型对所述文本特征向量进行响应,并输出响应结果。
18、在第三方面,为实现上述目的及其他相关目的,本发明提供一种移动终端,所述移动终端包括:存储器,处理器和通信组件;所述存储器,用于存储计算机程序;所述处理器,用于执行所述计算机程序,以实现上述的基于虚拟数字人交互处理方法。
19、在第四方面,为实现上述目的及其他相关目的,本发明提供一种车载终端,一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行时,以实现上述的基于虚拟数字人交互处理方法。
20、在第五方面,为实现上述目的及其他相关目的,本发明还提供一种基于虚拟数字人交互处理设备,包括:一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行时,使得所述设备执行前述的一个或多个所述的基于虚拟数字人交互处理方法。
21、在第六方面,为实现上述目的及其他相关目的,本发明还提供一个或多个机器可读介质,其上存储有指令,当由一个或多个处理器执行时,使得设备执行前述的一个或多个所述的基于虚拟数字人交互处理方法。
22、如上所述,本发明提供的基于虚拟数字人交互处理方法、系统、终端、设备及介质,具有以下有益效果:
23、通过接收输入的语音信息,将所述语音信息转换文本信息并进行特征提取,获得文本特征向量;将所述文本特征向量输入预设文档向量库进行匹配;若所述预设文档向量库内匹配到与所述文本特征向量关联的文档向量,则输出所述文档向量;若所述预设文档向量库内匹配不到与所述文本特征向量关联的文档向量,则利用人工智能大模型对所述文本特征向量进行响应,并输出响应结果。在本发明中,通过在预设文档向量库直接匹配文本特征向量进行输出,或,通过大模型对所述文本特征向量进行输出,一方面,人工智能大模型具备强大的自然语言处理能力,提升虚拟数字人的交互体验,使之能更自然地与用户进行对话,同时,通过向量匹配确保了虚拟数字人准确输出,也提高了虚拟数字人的交互能力;另一方面,结合人工智能大模型,使得虚拟数字人可以实现实时交互,更好地满足用户需求,适用于更多场景;还有一方面,结合人工智能大模型具有很强的可扩展性,可以随着数据的增加和算法的优化不断提升虚拟数字人的性能。
24、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!