基于对比学习改进的图像篡改检测方法
本发明涉及图像处理,尤其涉及基于对比学习改进的图像篡改检测方法。
背景技术:
1、数字图像以其直观传达信息的优势,在诸多领域中成为重要的信息传递载体。然而随着图像处理技术的多样化和图像编辑软件的流行,图像恶意篡改现象越来越普遍,这无疑给数字图像的安全性以及网络环境的净化带来了许多挑战。因此,对于图像篡改检测的研究具有重要的现实意义。
2、当前,主流的基于深度学习的方法进行图像篡改检测时主要依赖于篡改过程中留下的线索,包括视觉痕迹和残余压缩痕迹,再利用卷积神经网络(cnn)的自适应特性自动提取图像特征,对篡改图像进行分类或定位。这种方法训练的模型只针对特定的篡改特征有效,存在一定的局限性。当篡改图像显示出训练之外的其他篡改特征时,模型往往不能做出有效的检测。
3、并且现今由于篡改技术的多样性和不断发展,篡改特征逐渐多样化,因此只依赖于某种特定的篡改特征信息存在一定局限性,只能较好地应用于特定篡改特征在篡改图像中比较突出的场景中。当某些篡改技术有效模拟自然图像的特征,或者是对某个特征进行后处理掩盖,模型就难以准确检测到篡改图像的伪造特征。
技术实现思路
1、为解决上述问题,本发明提供基于对比学习改进的图像篡改检测方法,通过提取数据集本身的篡改特征进行学习,并利用全监督对比学习的机制使得模型面对各种篡改手段时都能表现出良好的性能,提高了模型的泛化能力。
2、为实现上述目的,本发明提供了基于对比学习改进的图像篡改检测方法,包括以下步骤:
3、s1、获取公开数据集,公开数据集包括casia和cover数据集,其中casia数据集由使用复制移动和拼接技术篡改的图像组成;cover数据集由多张使用复制移动技术篡改的图像组成;
4、s2、预处理:
5、s21、数据增强;
6、s22、参数设置;
7、s3、构建图像篡改检测模型;
8、s4、训练图像篡改检测模型;
9、s5、对图像篡改检测模型进行评测。
10、优选的,在步骤s1中由pascal voc中获取;
11、casia数据集和cover数据集中的图像上均附有用于促进图像伪造定位的真实掩模。
12、优选的,步骤s21所述的数据增强包括图像旋转和镜像;
13、在步骤s22中,将公开数据集中原始图像的大小调整为256x256像素,batchsize设置为32,patchsize设置为8;选用sgd优化器,其动量设置为0.9,权重衰减设置为0.0005,初始学习率设置为0.001;采用学习率衰减策略,设定为学习率每10轮下降到前一轮的十分之一;在训练网络模型中进行200次epoch的训练。
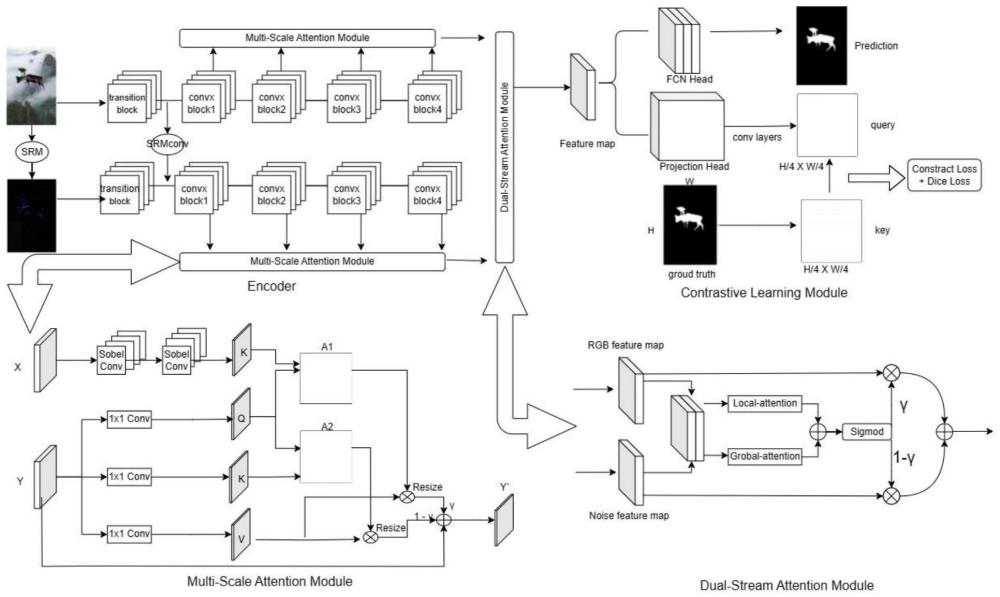
14、优选的,步骤s3所述的图像篡改检测模型包括改进的dpn模块、多尺度注意力模块、双流注意模块和对比学习模块;
15、改进的dpn模块用于提取早期边缘特征;
16、多尺度注意力机制模块用于提取篡改特征;
17、改进的dpn模块和多尺度注意力机制模块组成encoder模块,用于提取图像的rgb颜色域特征信息以及noise噪声域特征信息;
18、双流注意模块用于图像的篡改检测定位;
19、对比学习模块用于学习出更具区分性的特征表示。
20、优选的,改进的dpn模块以dpn神经网络为基础架构,其包括依次设置的五个阶段的block模块,每个阶段的block模块输出代表不同时期的特征信息,通过重复利用上述五个阶段的block模块特征信息,实现早期边缘特征的提取;
21、在改进的dpn模块中执行以下步骤:
22、将原始图像经过多个1x1,3x3大小的卷积核,通过卷积操作实现特征信息的复用,同时对新的特征信息进行学习,并将每个block模块的输出作为多尺度注意力模块的输入。
23、优选的,多尺度注意力机制模块是基于dot product实现的;
24、在多尺度注意力机制模块中执行以下步骤:
25、第一步、对于第i阶段的特征信息表示为f_i,依次经过sobel卷积核和下采样,将第i阶段的特征信息尺寸调整为与第i+1阶段的特征信息f_(i+1)相同的尺寸;
26、第二步、通过不同的卷积块将f_i转换为注意力机制中的key值向量,以表示浅层特征特定信息;
27、第三步、将f_(i+1)通过不同卷积操作分别变换为注意力机制中的key、value和query;
28、第四步、使用矩阵乘法和求和计算输出流,并将此多尺度注意力机制模块的输出流用作下一个多尺度注意力机制模块的输入流,其计算公式如下:
29、
30、式中,tedg-i表示融合双分支后的特征信息;γ表示不断学习的权重参数;qi表示查询向量;ki-1表示键值向量;d表示键值向量的维度;vi表示值向量;
31、第五步、利用encoder模块提取图像的rgb颜色域特征信息以及noise噪声域特征信息。
32、优选的,在双流注意模块中执行以下步骤:
33、第一步、设定rgb颜色域特征信息和noise噪声域特征信息分别为trgb和tnoise;
34、第二步、采用以下公式将trgb和tnoise进行拼接:
35、tcat=fcat(trgb+tnoise)
36、式中,tcat表示拼接后的特征表示;fcat表示concate函数;
37、第三步、通过局部注意力和全局注意力的方式再通过相应的sigmoid获取一组融合权重:
38、wei=sigmoid(fglobal(tcat)+flocal(tcat))
39、式中,fglobal表示局部注意力,flocal表示全局注意力;
40、第四步、赋予trgb和tnoise不同的权重并进行相加,从而实现特征信息的软选择:
41、xo=2*trgb*wei+2*tnoise*(1-wei)
42、式中,xo表示融合后的特征信息;
43、第五步、将xo依次通过fcn全卷积神经网络的fc head、多个膨胀卷积后,使得输出尺寸转化成与输入x尺寸相同的尺寸,用于图像篡改检测定位任务。
44、优选的,在对比学习模块中执行以下步骤:
45、第一步、将由双流注意模块输出的输出特征尺寸输入对比学习模块中;利用对比学习模块中的fcn head将输出特征尺寸映射为待检图片的尺寸大小;利用对比学习模块中的projection head和ground-truth mask分别映射到编码器特征提取四个阶段的特征尺寸大小;
46、第二步、在训练过程中先用projection head进行训练,而后利用fcn head通过采用多次的上采样保留边缘信息逐步恢复图像的细节,再进行预测评估;
47、第三步、在损失函数部分,添加如下对比损失函数:
48、
49、
50、lloss=γldice+linfonce
51、式中,ldice表示dice损失函数;r表示分割结果;g表示真实标注;eps表示平滑系数;linfonce表示infonce损失函数;q表示在infonce损失函数中的查询向量;k+表示键值向量;ki表示所有样本的键值向量;lloss表示基于dice损失函数和infonce损失函数构造的自己的损失函数;τ表示温度参数;aj表示尺寸大小为四个convx卷积块输出的尺寸大小。
52、优选的,在步骤s4中,使用python环境以及pytorch深度学习框架;并使用sgd作为优化器,其动量设置为0.9,权重衰减设置为0.0005,初始学习率设置为0.001;同时采用学习率衰减策略,设定为每训练10轮学习率衰减为上个轮次的十分之一;且将batch-size的大小设置为32,patch-size大小设置为8;使用经在对比学习模块确定的损失函数;将训练网络模型迭代200个epoch。
53、优选的,在步骤s5中,将经步骤s4训练好的图像篡改检测模型分别在casia数据集和cover数据集上进行评估验证,选取的验证指标为auc和f1。
54、本发明具有以下有益效果:
55、1)本发明所设计的多尺度关注模块和双流关注模块,相比于现有的研究,更能充分利用图像的边缘信息以及神经网络不同层次的特征信息,实现低层次的边缘信息与高层次的语义信息相融合,通过赋予不同权重忽略无关的特征信息,使得模型更加关注与检测相关的特征信息,从而更好地提取图像篡改特征信息;
56、2)本发明所设计的对比学习模块可识别各种不同的篡改线索,而不是仅仅专注于某个特定的特征信息,同时该模块直接利用数据本身作为监督学习信息,且在模型训练过程中引入约束部分,相比于以往的模型更具鲁棒性,泛化性也更强。
57、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!