一种基于AST和LLM的混合式前端框架迁移方法
本发明属于代码迁移领域,尤其是涉及一种基于ast和llm的混合式前端框架迁移方法。
背景技术:
1、在金融机构的客户端系统产品中,大多数使用基于微软wpf开发的ui框架,wpf与windows操作系统是紧耦合的,不能支持基于linux的国产操作系统。wpf框架对其他操作系统的兼容问题,目前仍没有解决方案。
2、将桌面端金融软件迁移到国产操作系统,实际上相当于进行一项复杂而全面的软件转换工程。这项工程的复杂性源自于其几乎等同于对整个软件系统进行重构的挑战,这势必导致人力资源和时间的高度投入。
3、越来越多的公司尝试对代码进行自动化迁移,如国内公开号为cn116204208a的专利文献提出了一种前端框架升级代码迁移方法及装置,公开号为cn115951890a的专利文献提出了一种不同前端框架间的代码转换方法及系统及装置。实现这一迁移过程的自动化,不仅能够降低人力资源的投入,还有望显著减少整个迁移过程所需的时间。
4、llm(large language model,大型语言模型)例如gpt-3.5或类似的模型,这些模型在自然语言处理领域取得了显著的进展,能够生成文本、回答问题、进行对话等。大型语言模型在生成代码方面具有很大潜力,可以用于自动代码生成、编程辅助等任务。因此,将llm引入对桌面端软件的迁移具有可行性。
5、但大语言模型生成代码的过程存在一些缺陷:
6、1)由于成熟的软件项目代码量巨大,而llm的接口token(可处理的最小文本单元)有内容限制,在很多情况下,我们不能直接将完整的项目文件内容上传至llm。
7、2)由于前端框架版本在不断更新,各控件库和api内容也会发生变化,而llm建立在历史数据的预训练基础上,其所生成的信息带有一定时效性,无法根据最新数据生成高度准确的内容,导致生成的代码片段或建议在应对最新前端开发需求时可能存在一定的不准确性或不适用性。
8、3)与生成通用文本不同,仅仅基于上传的片段代码进行处理并不足以精确生成迁移代码。这是因为代码的结构和逻辑要求更高的上下文理解,以确保生成的迁移代码在语义和功能上保持一致。
9、4)在特定领域的信息处理中,大型语言模型(llm)的训练数据可能未覆盖公司内部的开发流程、开发框架、开发内容等信息。为了获得准确的反馈,有必要补充这些特定领域的内容和相关上下文。
技术实现思路
1、本发明提供了一种基于ast和llm的混合式前端框架迁移方法,可以提高迁移准确性,还能够给出语法错误报告和处理建议。
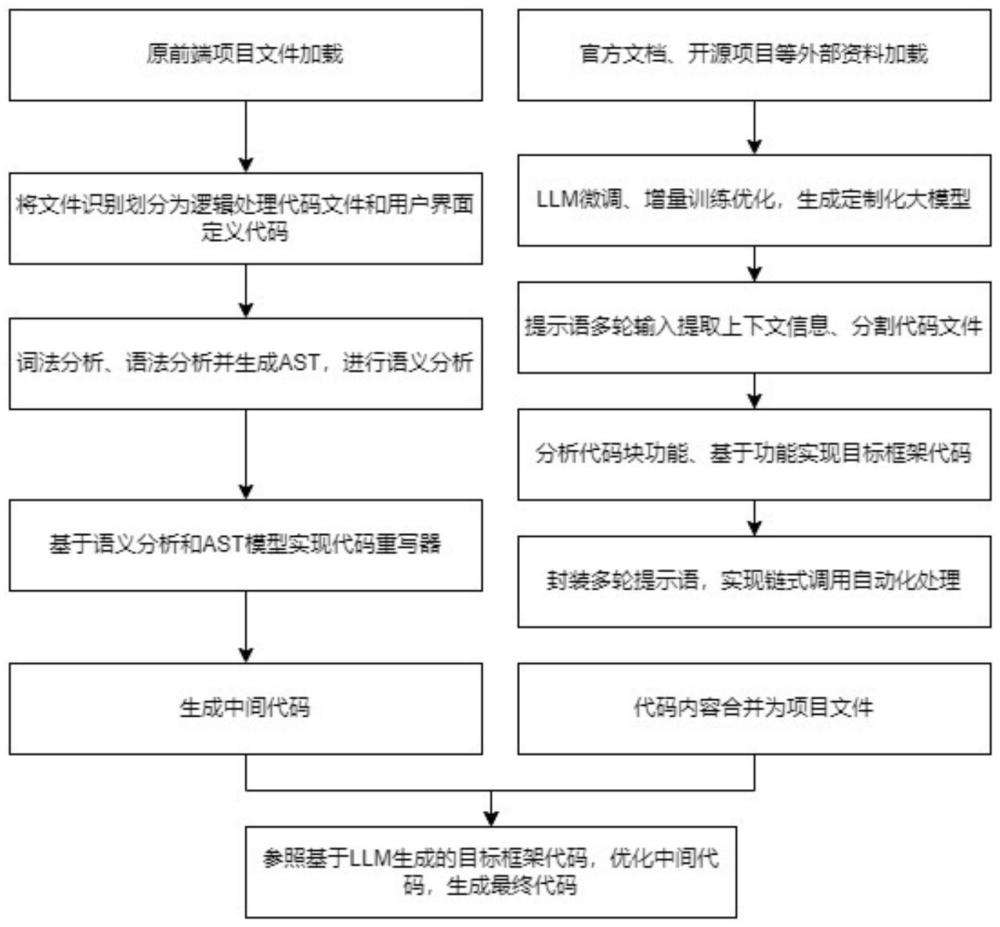
2、一种基于ast和llm的混合式前端框架迁移方法,包括以下步骤:
3、(1)原前端框架项目加载,识别项目文件并将功能性项目代码分为逻辑处理代码和用户界面定义代码;
4、(2)词法分析、语法分析与语义提取,具体步骤如下:
5、(2-1)词法分析,将逻辑处理代码和用户界面定义代码分解为一系列的词法单元;
6、(2-2)语法分析,在词法分析的基础上进行语法分析,将词法单元组织成抽象语法树ast,表示代码的层次结构和代码元素之间的嵌套关系;
7、(2-3)语义分析,在ast的基础上进行语义分析,包括类型检查、作用域分析、符号解析、继承和实现分析等;
8、(3)代码重写器处理,具体步骤如下:
9、(3-1)基于原前端框架和迁移目标框架的控件库,编写基于控件库的各方法属性实现代码;
10、(3-2)根据迁移前后各控件的属性和方法调用的对应关系,按照复杂程度归纳实现迁移规则;迁移规则分为:单点位迁移、单语句迁移、复杂结构迁移;
11、(3-3)基于语义分析的ast模型和迁移规则实现代码重写器,生成中间代码;
12、(4)增量训练优化生成定制化大模型llm,利用定制化大模型llm得出原项目文件的代码功能描述,进一步生成目标框架代码;
13、(5)基于中间代码,通过定制化大模型llm生成语法错误报告和处理建议;利用目标框架代码优化中间代码,生成最终迁移代码。
14、本发明的代码迁移方法,根据代码功能分别处理,进行语义分析,构建语义模型,将代码重写器生成的中间代码和llm模型生成的目标框架代码融合生成最终迁移代码,解决手工迁移方式过程繁琐、耗费人力的问题,实现迁移的自动化,提高迁移效率,降低工作量和成本。
15、步骤(1)的具体过程为:
16、使用代码编译分析工具如roslyn对整个项目加载预编译,识别项目文件内容,将文件归类为逻辑处理文件、用户界面定义文件、资源文件、配置文件、其它文件,提取逻辑处理代码文件和用户界面定义代码文件,生成逻辑处理代码文件和用户界面定义代码文件的映射关系。
17、步骤(2-1)中,逻辑处理代码分解为关键字、标识符、操作符、常量等,用户界面定义代码分解为标签名、属性名、属性值。
18、步骤(2-3)中,在类型检查阶段,将确定代码中变量、表达式和值的数据类型;在作用域分析阶段,将识别变量、函数和类的作用域范围,检查变量在作用域内的声明和使用;在符号解析阶段,将建立符号表,用于存储变量、函数和类的信息,识别符号并查找声明和引用;在继承和实现分析阶段,将分析类之间的继承关系和接口。
19、步骤(3-2)中,对于单点位迁移,通过遍历语法节点树来实现更新迁移;对于单语句迁移,通过正则表达式匹配目标语句,提取调用信息实现迁移;对于复杂结构迁移,则针对每条规则,通过修改语法树的方式来实现迁移。
20、步骤(3-3)中,代码重写器的生成基于ast操作树节点进行代码的修改、移动和重组;并基于迁移规则分为常规规则重写器、特殊规则重写器和后续优化重写器。
21、在这一流程中,分为迁移前后框架控件库内容提取、迁移规则生成、代码重构、关联处理等。
22、在框架控件库内容提取阶段,通过爬虫框架爬取源框架软件库和迁移目标软件库的官方文档信息,开源项目和社区问答信息,对爬取到的信息加工处理。同时,为了确保迁移的规则在声明空间、控件层面、类层面、方法层面、语句体层面一一对应,将原框架的各前端控件的方法和属性和目标迁移框架的方法属性对应实现。
23、在迁移规则生成阶段,通过爬取到的内容和迁移前后原框架和目标框架控件库代码的对比,基于粗粒度如项目文件层次、控件层次、声明空间层次、类层次、方法体层次等进行逐一匹配映射,基于语句体层次和标识符层次进行细粒度映射,生成基于语句层次的迁移规则。
24、具体而言,我们归纳出了三类迁移规则:(1)单点位迁移。这类规则,包括对ast中单个语法节点的迁移,例如对变量属性名的修改,函数名修改等。这种类型我们采用代码重写器,遍历语法树来进行重写。(2)单语句迁移:这类迁移涉及到对单条语句的迁移,我们采用代码重写器逐语句遍历代码,并用正则表达式进行匹配与迁移。(3)复杂结构迁移。这类迁移往往变动大且复杂,我们针对每个迁移都进行特殊处理。通过对ast的直接修改来实现。
25、代码重构阶段,通过原前端框架项目加载生成的语义模型,基于ast节点对待迁移语句进行定位,定位过程通过正则匹配、代码分析工具逐节点匹配等方式将定位语句生成为目标框架语句。
26、关联处理阶段,根据符号表递归查找定位上下文中相关变量、函数和类的声明和调用,如基于该类的声明方法,查找该类继承关系,定位第一次声明该方法位置,修改相关内容。
27、步骤(4)的具体过程为:
28、(4-1)将外部资料、相关文档和迁移规则总结信息作为数据源加载为大模型读取的形式,将数据切分为指定大小后以嵌入的形式存入到向量数据库中,传递给大模型,生成定制化大模型llm;
29、(4-2)对项目所有待迁移代码进行统计,判断token是否超过,并基于语义分析信息对原项目文件分割;
30、(4-3)根据逻辑处理代码和用户界面定义代码的对应关系,以及上下文调用关系,合并上传定制化大模型llm,得出原项目文件的代码功能描述;
31、(4-4)基于功能描述,调用定制化大模型llm生成目标框架代码。
32、步骤(4-1)中,将数据源按指定大小分割为文档块,以嵌入的形式存储到向量数据库中;在输入提示语时,从向量数据库中检索分割后的文档,通过比较余弦相似度,查找向量数据库中与该提示语问题相似的文档块,将该文档块传递给llm模型,使用含有问题和文档块的提示语生成回答。
33、步骤(5)中,中间代码基于原框架代码的内容,目标框架代码基于原框架代码的功能,利用目标框架代码优化中间代码,在保持原代码的结构基础上优化代码重写器未能处理的不符合语法的部分,并生成错误日志和优化建议,供后续开发人员处理。
34、与现有技术相比,本发明具有以下有益效果:
35、本发明的方法基于项目架构、语法模型和实际运行的调用关系,分别从抽象语法树节点粒度、语句粒度、代码块粒度、命名空间粒度、项目文件粒度解析迁移过程的各符号和调用信息,实现自动化迁移得到中间代码,并参照基于大模型识别出源代码文件语句,解析它们的功能和关系,以此为参照优化中间代码,得到最终迁移代码,提高迁移准确性,并给出测试用例、标记特殊修改位置、给出修改建议。
- 还没有人留言评论。精彩留言会获得点赞!