数据检索方法、装置、电子设备及计算机可读存储介质
本发明涉及数据处理,特别涉及一种数据检索方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、快速检索数据项的常用技术是使用支持集合成员检查的数据结构。这种数据结构可以减少搜索空间,避免不必要的数据项比较或传输。布隆过滤器就是这种数据结构中的一种,它是一种概率数据结构,使用多个普通哈希函数将项目映射到位数组;布隆过滤器可以实现较高的空间效率和较快的查询时间,不过它有两个明显的缺点,即为无法支持删除数据项以及假阳性率不为零;为了克服这些缺点,诞生了布谷鸟过滤器,这是另外一种概率数据结构,它使用布谷鸟哈希函数来解决碰撞问题,并存储的是数据指纹而不只是比特;布谷鸟过滤器可以支持删除数据项,而且其假阳性是有界的,可以通过调整指纹和桶的大小来调整。此外,布谷鸟过滤器的假阴性率为零,即当一个数据项属于集合时,绝不会报告该数据项不属于集合。
2、目前,对于数据查询的过程中,数据源可能含有很多几乎相同的数据,而这些数据可能又并不完全相同,对这些近似相同的数据难以处理;因为数据项可能是不同的格式,以图片为例子,一张图片只修改了一个像素后其视觉性与修改之前几乎相同,这些近似相同的图片在处理时应该被视为相同的内容,但是传统的过滤器技术会把近似相同的图片处理为不同的图片,无法进行近似搜索以及大幅降低对近似相同数据项的查询效率。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。
2、为此,本发明提出一种数据检索方法,使得相似的数据在哈希编码中会有更相似和接近的表示,从而保持数据的相似性,便于数据的相似性搜索和相关性分析,提高相似数据项的查询效率。
3、本发明还提出一种应用上述数据检索方法的装置。
4、本发明还提出一种应用上述数据检索方法的电子设备。
5、本发明还提出一种应用上述数据检索方法的计算机可读存储介质。
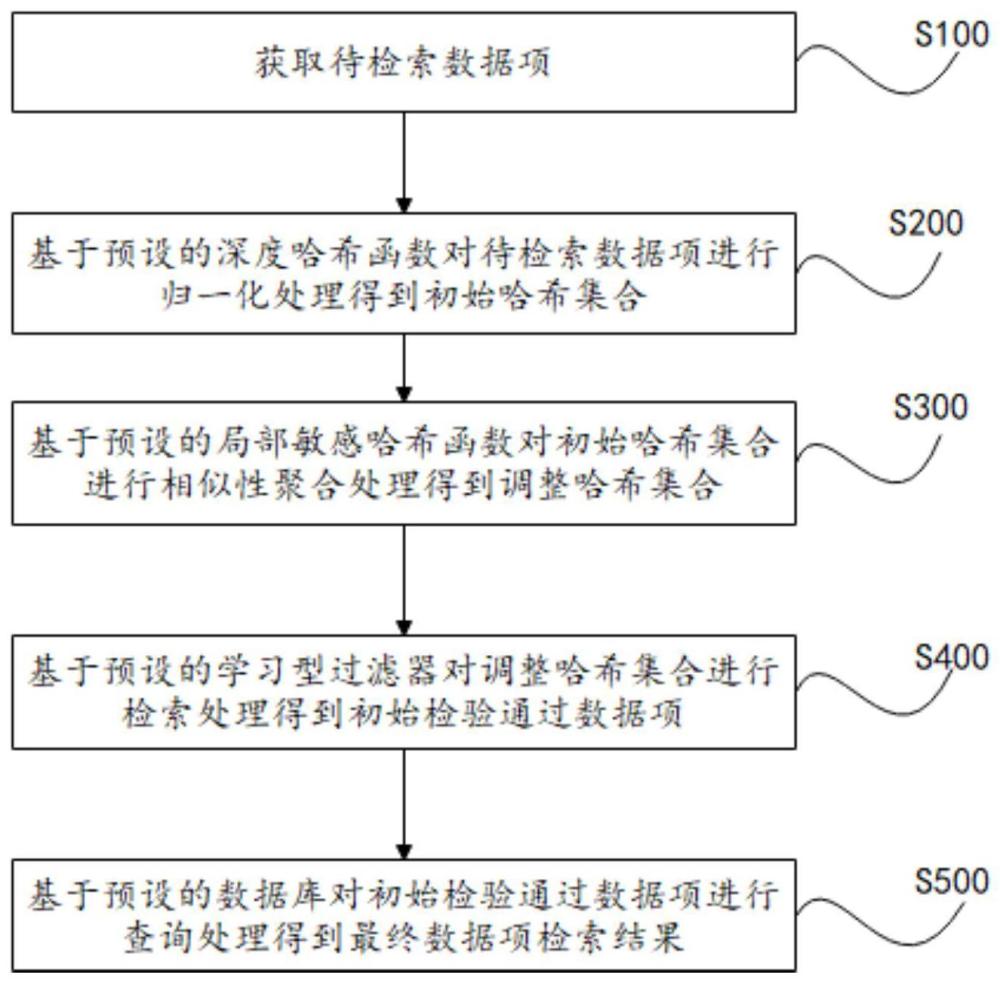
6、根据本发明第一方面实施例的数据检索方法,所述方法包括:
7、获取待检索数据项;
8、基于预设的深度哈希函数对所述待检索数据项进行归一化处理得到初始哈希集合;
9、基于预设的局部敏感哈希函数对所述初始哈希集合进行相似性聚合处理得到调整哈希集合;
10、基于预设的学习型过滤器对所述调整哈希集合进行检索处理得到初始检验通过数据项;
11、基于预设的数据库对所述初始检验通过数据项进行查询处理得到最终数据项检索结果。
12、根据本发明的一些实施例,所述深度哈希函数包括深度监督离散哈希,所述基于预设的深度哈希函数对所述待检索数据项进行归一化处理得到初始哈希集合,包括:
13、基于预训练的所述深度监督离散哈希对所述待检索数据项中的数据项逐个进行特征提取得到多个数据特征,以及分别对多个所述数据特征进行编码处理得到多个定长哈希码;
14、将多个所述定长哈希码确定为所述初始哈希集合。
15、根据本发明的一些实施例,所述基于预设的局部敏感哈希函数对所述初始哈希集合进行相似性聚合处理得到调整哈希集合,包括:
16、对所述初始哈希集合的所有所述定长哈希码进行最小哈希操作,得到总体特征矩阵;
17、对所述总体特征矩阵进行区间分割处理确定区间个数和区间行数,以及根据所述区间个数、所述区间行数和预设的精度计算公式确定杰卡德相似度阈值;
18、对所有所述定长哈希码之间的杰卡德相似度进行确定,并且在所述杰卡德相似度大于所述杰卡德相似度阈值的情况下,将对应的两个所述定长哈希码修正为相同哈希值以得到所述调整哈希集合。
19、根据本发明的一些实施例,所述对所有所述定长哈希码之间的杰卡德相似度进行确定,包括:
20、对所述初始哈希集合中的每个定长哈希码进行若干次比特排列,并且记录每次比特排列的第一个数值为1的比特的索引值,得到每个所述定长哈希码的若干个最小哈希值;
21、将所述定长哈希码对应的若干所述最小哈希值确定为对应的所述定长哈希码的特征向量;
22、将任意两个所述定长哈希码对应的所述特征向量进行比较近似得到所述定长哈希码之间的所述杰卡德相似度。
23、根据本发明的一些实施例,所述学习型过滤器包括学习模型和布谷鸟过滤器,所述基于预设的学习型过滤器对所述调整哈希集合进行检索处理得到初始检验通过数据项,包括:
24、基于预训练的学习模型对所述调整哈希集合中的定长哈希码进行键值识别处理得到键值判断概率;
25、在所述键值判断概率大于预设判断阈值的情况下,将对应的所述定长哈希码对应的数据项确定为所述初始检验通过数据项;
26、在所述键值判断概率小于或者等于所述预设判断阈值的情况下,基于所述布谷鸟过滤器对所述定长哈希码进行识别处理以确定所述定长哈希码对应的数据项是否存在于预设的原始数据集。
27、根据本发明的一些实施例,所述学习模型通过以下方式得到:
28、获取一组正元素和一组负元素,其中,所述正元素表征属于预设集合的元素,所述负元素表征不属于预设集合的元素;
29、将所述正元素和所述负元素输入至预设的学习模型得到训练分数,其中,所述训练分数用于表征为所述正元素的概率;
30、根据所述训练分数和预设的目标函数对所述学习模型进行参数调整处理。
31、根据本发明的一些实施例,所述基于预设的数据库对所述初始检验通过数据项进行查询处理得到最终数据项检索结果,包括:
32、对所述初始检验通过数据项进行感知哈希运算处理得到感知哈希值;
33、根据所述感知哈希值对所述数据库进行查询处理得到所述最终数据项检索结果。
34、根据本发明第二方面实施例的数据检索装置,所述装置包括:
35、第一处理模块,用于获取待检索数据项;
36、第二处理模块,用于基于预设的深度哈希函数对所述待检索数据项进行归一化处理得到初始哈希集合;
37、第三处理模块,用于基于预设的局部敏感哈希函数对所述初始哈希集合进行相似性聚合处理得到调整哈希集合;
38、第四处理模块,用于基于预设的学习型过滤器对所述调整哈希集合进行检索处理得到初始检验通过数据项;
39、第五处理模块,用于基于预设的数据库对所述初始检验通过数据项进行查询处理得到最终数据项检索结果。
40、根据本发明第三方面实施例的电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的数据检索方法。
41、根据本发明第四方面实施例的一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令被控制处理器执行时实现如上所述的数据检索方法。
42、根据本发明实施例的数据检索方法,至少具有如下有益效果:在进行数据检索的过程中,首先获取待检索数据项;接着基于预设的深度哈希函数对待检索数据项进行归一化处理得到初始哈希集合;接着基于预设的局部敏感哈希函数对初始哈希集合进行相似性聚合处理得到调整哈希集合;接着基于预设的学习型过滤器对调整哈希集合进行检索处理就可以得到初始检验通过数据项;最后基于预设的数据库对初始检验通过数据项进行查询处理得到最终数据项检索结果。通过上述技术方案,使得相似的数据在哈希编码中会有更相似和接近的表示,从而保持数据的相似性,便于数据的相似性搜索和相关性分析,提高相似数据项的查询效率。
43、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!