一种全局与局部特征交互并行的多模态医学图像融合方法
本发明属于医学图像融合,具体涉及一种全局与局部特征交互并行的多模态医学图像融合方法。
背景技术:
1、随着医学成像技术的进步,医学图像在临床诊断中发挥了不可替代的作用。由于成像原理的差异,不同模态的医学图像能表达人体内组织或器官的不同结构信息。例如,电子计算机断层扫描(ct)图像包含身体内部骨骼结构信息,但是缺乏软组织细节信息;而核磁共振成像(mri)图像能够反映高分辨率的软组织以及血液流动信息,但对骨骼结构展示不明显。由于单个模态的医学图像只能提供有限的信息,医生在诊断过程中需要查看不同模态的图像,增加了诊断难度,降低了效率。因此,需要将来自不同模态图像中重要的和互补的信息整合起来,生成一幅信息丰富的融合图像,可以克服单模态医学图像的局限性。多模态融合图像能够同时保留不同模态源图像的丰富特征,成为临床诊断和有效治疗的可靠依据。
2、目前,多模态医学图像融合方法分为传统方法和基于深度学习的方法两类。传统的图像融合方法在空间域或变换域执行活动水平测量,并手动设计融合规则来实现图像融合。基于空间域的方法直接在图像的原始像素空间进行融合,融合规则采用简单的加权平均法和主成分分析法(pca)。简单直观、融合速度快,但会产生光谱和空间失真。为了获得更好的融合效果,j.piao等人(2019)引入小波变换。将源图像从空间域转换到变换域得到不同频率的分量,再针对不同的分量设计融合规则,最后通过逆变换得到融合图像。尽管这种方法具有良好的结构和避免失真的优点,但融合过程中会产生噪声,丢失边缘和纹理信息。同时,传统方法没有关注到模态之间的差异,融合结果丢失源图像的重要信息,且手动设计的融合规则采用固定的权重,限制了融合效果,无法满足日益增长的复杂的融合要求。
3、基于深度学习的图像融合方法具有强大的特征表征能力,能够实现自适应特征融合,克服了传统融合方法的缺陷。基于自编码器(ae)的融合方法是目前深度学习的主流方法之一。自编码器通常利用卷积神经网络(cnn)进行特征提取和重建,在中间层使用特定融合规则进行融合。如prabhakar等人(2017)提出的deepfuse,编码器解码器由5个卷积层构成,编码器从图像中获取特征后,执行相加融合策略,再将融合特征输入到解码器中得到最终的融合图像,但由于网络结构过于简单导致图像信息丢失。hui等人(2019)提出的densefuse引入了密集块,将每一层的输出与其它层直接级联,可以保存更多的信息,但由于使用相加和l1-norm的融合策略,无法适应多样化的多模态数据,导致融合图像中细节不明显,影响融合效果。hui li(2021)等人提出的rfn-nest中使用残差融合网络(rfn)取代了人工设计的融合策略,通过细节损失函数和特征增强损失函数训练融合网络,保留了更多的纹理细节和特征。但由于cnn结构较小的感受野,只能提取到图像的局部信息,导致全局信息丢失。
4、目前,在多模态医学图像融合中通常利用transformer解决cnn无法捕获全局信息的缺陷。qu l等人(2021)提出了transmef,一种联合cnn和transformer的自编码器网络,可以在特征提取过程中同时捕获局部和全局信息。而其融合规则使用平均法,导致在融合过程中图像的重要细节信息丢失,影响了融合模型的性能。jiayi ma等人(2022)为了实现特征信息的充分融合,提出了swinfusion,其融合规则设计为注意力引导的跨域融合,利用自注意机制和交叉注意机制分别实现域间和跨域融合。而zixiang zhao等人(2023)考虑到局部或全局特征融合的归纳偏置和编码器中的局部或全局特征提取相同,在cddfuse中融合模块使用对应编码器的基础网络单元实现局部或全局特征融合。但由于cnn和transformer的输出表示不同,特征提取过程中无法实现不同分支之间的信息交互,造成了全局和局部信息的丢失。在图像去噪领域,jiale zhang等人(2023)提出了一种具有特征交互的双分支transformer,通过利用双向连接单元实现空间信息和通道信息的交互,从不同维度增强transformer全局信息建模。但是其无法捕获图像的局部信息。
技术实现思路
1、针对目前多模态医学图像融合方法中存在的transformer对局部特征提取能力不足、特征提取过程中纹理、边缘信息丢失的问题,本发明提供了一种全局与局部特征交互并行的多模态医学图像融合方法。
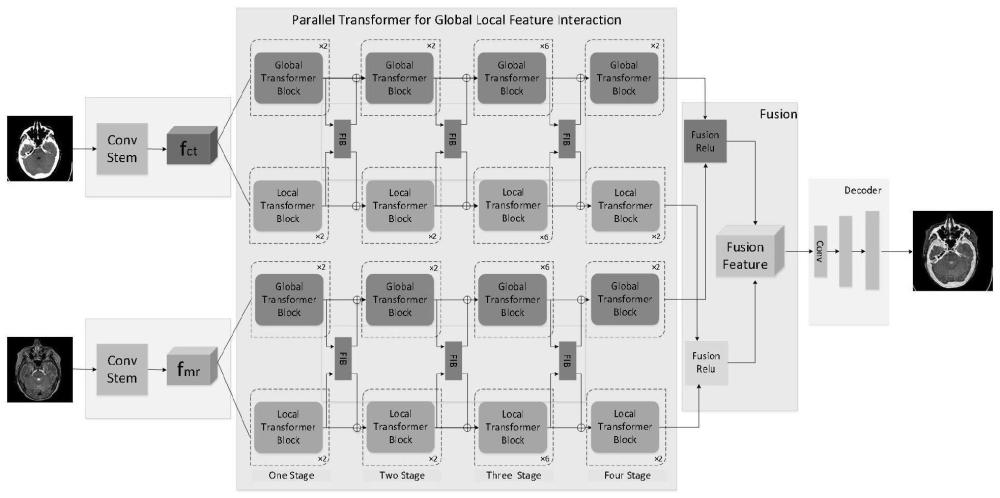
2、本发明以256×256×1的ct图像和256×256×1的mri图像的融合为例,介绍基于全局局部特征交互并行transforemr的多模态医学图像融合方法。不同模态的图像经过由convstem和全局局部特征交互并行transformer组成的encoder模块进行特征提取后,得到不同模态对应的全局深层特征和局部深层特征。并由fusion模块实现不同模态的全局深层特征融合和局部深层特征融合,在decoder模块中将融合特征重建到原始图像大小,得到最终融合结果。本发明通过重建原始输入图像来训练encoder模块和decoder模块的网络参数,损失函数使用图像重建损失和梯度损失。且fusion模块仅在测试阶段保留,在训练阶段移除。
3、总体架构如图1所示,融合方法的整体流程如图2所示。
4、为了达到上述目的,本发明采用了下列技术方案:
5、步骤1:将不同模态的图像分别经过由convstem和全局局部特征交互并行transformer组成的encoder模块提取特征,得到相应模态的全局深层特征xct、xmri和局部深层特征yct、ymri;
6、encoder模块由convstem和全局局部特征交互并行transformer组成,其中,convstem提取图像的浅层特征,全局局部特征交互并行transformer提取全局和局部深层特征,全局深层特征提取由global transformer block实现,局部深层特征提取由localtransformer block实现,为了在特征提取过程中避免全局和局部信息的丢失,在特征提取过程中加入全局局部特征交互模块,根据全局深层特征提取分支和局部深层特征提取分支之间的特征相关性来增强全局信息和局部信息;
7、步骤1.1:采用由4层卷积组成的convstem提取图像的浅层特征;
8、步骤1.2:采用global transformer block模块提取全局深层特征,globaltransformer block结构如图3(左)所示;具体步骤为:
9、步骤1.2.1:将特征图x∈rh×w×c输入到global transformer block中,对其进行层归一化;
10、步骤1.2.2:利用全局多头注意机制根据特征不同位置之间的自注意关系计算权重,捕捉输入特征之间的关系;
11、步骤1.2.3:将得到的特征进行层归一化后,送入前馈神经网络(ffn)中进行非线性变换和特征映射,提高模型的表达力和非线性拟合能力;在g-msa和ffn之后应用残差连接,确保特征的有效传递。
12、将输出第i个global transformer block的输出特征记为xi,其公式表达为:
13、x'i=g-msa(ln(xi-1))+xi-1
14、xi=ffn(ln(x'i))+x'i
15、其中,ln是层归一化操作,g-msa表示全局多头注意机制,x'i是第i个globaltransformer block的中间特征,ffn代表前馈神经网络;
16、global transformer block通过全局多头注意机制实现对图像的全局信息建模,具体结构如图3(右)所示,具体过程为:g-msa首先将层归一化后的图像特征x∈rh×w×c,通过线性变化层(fc)映射为q,k和v,即q,k,v=fc(x);为了降低transformer计算复杂度,对k和v进行平均池化(pool)下采样,减小特征图的尺寸;对q、k、v执行标准注意操作,得到图像特征的全局特征xg;将g-msa过程公式化为:
17、xg=attention(q,pool(k),pool(v))
18、其中attention为标准注意操作,q∈rhw×c,k∈rhw×c,v∈rhw×c,h、w、c分别为图像特征的高度、宽度和通道数,pool为平均池化。
19、步骤1.3:采用local transformer block模块作为局部深层特征提取分支提取局部深层特征,具体结构如图4(左)所示。其使用与glocal transformer block相同的transformer编码器结构,不同的是local transformer block在注意力机制中引入深度卷积实现了transformer提取局部特征。具体步骤为:
20、步骤1.3.1:将特征图y∈rh×w×c输入到local transformer block中,对其进行层归一化;
21、步骤1.3.2:利用局部多头注意机制(l-msa)捕获输入特征图的局部特征;
22、步骤1.3.3:将捕获到的局部特征进行层归一化后,在前馈神经网络中进行非线性变化;
23、将第i个local transformer block输出特征记为yi,可以使用如下公式表示:
24、y'i=l-msa(ln(yi-1))+yi-1
25、yi=ffn(ln(y'i))+y'i
26、其中l-msa表示局部多头注意机制,y'i是第i个local transformer block的中间特征;
27、局部多头注意机制的具体结构如图4(右)所示,local transformer block通过局部多头注意机制实现对图像的局部信息建模,具体过程为:对于层归一化后的图像特征图y∈rh×w×c,l-msa通过线性变化(fc)得到q∈rh×w×c、k∈rh×w×c和v∈rh×w×c;使用深度卷积(dwconv)分别对q、k和v进行局部特征聚合,实现局部信息提取,得到ql、kl、vl;将ql和kl的对应位置上的元素相乘,并对结果使用swish和tanh非线性变换,获得上下文感知权重attn;通过计算attn和vl的hadamard乘积,得到图像的局部特征yl;
28、局部多头注意机制在注意力机制中引入dwconv实现了transformer提取局部特征;l-msa的过程可以由以下公式表示:
29、ql=dwconv(q)
30、kl=dwconv(k)
31、vl=dwconv(v)
32、attn'=fc(swish(fc(ql⊙kl))
33、
34、yl=attn⊙vl
35、其中,dwconv为深度卷积,fc是线性变化,ql、kl、vl均为得到的局部特征,d表示特征通道数,⊙代表hadamard操作,attn'为经过swich变换后的注意力权重,attn为经过swich和tanh变换的注意力权重。
36、步骤1.4:采用全局局部特征交互模块捕获全局和局部深层特征提取分支之间的特征相关性。
37、global transformer block和local transformer block能捕获到图像的全局和局部深层特征,但在特征提取过程中两个模块是孤立的,每个模块只关注其对应的全局或局部信息,导致其余信息丢失。为了解决这个问题,在global transformer block和localtransformer block之间加入全局局部特征交互模块(fib);全局局部特征交互模块计算全局深层特征和局部深层特征之间的相关性权重矩阵;通过将相关性权重矩阵与全局深层特征或局部深层特征相乘来增强全局信息或局部信息;将增强的信息传递到下一个globaltransformer block和local transformer block中,避免了信息的丢失;具体过程如图5所示,具体方法包括以下步骤:
38、步骤1.4.1:第i个global transformer block的输出为全局深层特征xi∈rh×w×c,第i个local transformer block的输出为局部深层特征yi∈rh×w×c;
39、步骤1.4.2:在全局局部特征交互模块(fib)中,xi和yi经过核大小为1×1的卷积,得到特征q∈rh×w×c和特征k∈rh×w×c;
40、步骤1.4.3:为了进行矩阵乘法,使用reshape函数将q、k转化为二维形式,q∈rhw×c、k∈rhw×c;
41、步骤1.4.4:通过softmax激活函数得到不同分支特征的相关系数矩阵m∈rhw×hw;
42、步骤1.4.5:分别与xi和yi相乘得到增强的全局特征和局部特征
43、步骤1.4.6:让与xi、与yi进行残差连接,分别作为下一个global transformer block和local transformer block的输入;
44、第i+1个global transformer block的输入可以表示为:
45、
46、第i+1个local transformer block的输入可以表示为:
47、
48、其中,为增强的全局特征,为增强的局部特征;
49、通过上述方法,可以让网络捕获local transformer block中的全局信息和global transformer block的局部信息,增强特征信息的同时,避免了特征提取过程中信息的丢失。
50、步骤2:fusion模块使用统一的融合规则将不同模态的全局深层特征和局部深层特征融合后输入decoder模块;在decoder模块中,融合特征经过上采样、合并通道数,恢复为原始图像尺寸,得到融合图像ifusion;
51、所述步骤2中fusion模块采用一种基于l1-norm的图像序列矩阵融合规则,分别用于融合不同模态图像的全局深层特征和局部深层特征;该融合策略分别从行向量和列向量维度测量源图像的活动水平,通过量化输入特征中不同区域和通道之间的重要性,使融合结果能够很好的保留源图像的亮度和细节信息;
52、以encoder模块提取到的ct和mri模态的全局深层特征融合为例,融合步骤如下:
53、步骤2.1:对于输入的两个模态的全局深层特征xct(i,j)、xmri(i,j),在行向量维度上分别计算全局深层特征的l1-norm,采用softmax的方式计算两个模态在行向量维度上的权重参数,即具体过程如公式所示:
54、
55、
56、其中,||a||1表示a的l1-norm,xct(i)、xmri(i)均为行向量维度上的全局深层特征,均为行向量维度上的权重参数;exp(·)为指数函数。
57、步骤2.2:将其权重参数与对应模态的全局深层特征相乘,得到两个模态行向量维度的全局深层融合特征计算过程如公式所示:
58、
59、步骤2.3:重复步骤2.1、步骤2.2,在列向量维度上计算输入图像全局深层特征的l1-norm,通过公式得到两个模态在列向量维度上的权重参数
60、
61、
62、其中,||a||1表示a的l1-norm,xct(j)、xmri(j)均为列向量维度上的全局深层特征,均为列向量维度上的权重参数;exp(·)为指数函数。
63、步骤2.4:利用计算得到的权重参数对两个模态的全局深层特征进行融合,得到列向量维度的全局深层融合特征
64、
65、步骤2.5:将行向量维度和列向量维度的全局深层融合特征进行元素相加,得到最终的多模态全局深层融合特征xfusion(i,j);
66、
67、步骤2.6:ct和mri模态的局部深层融合特征yfusion(i,j)也可通过上述的融合步骤获得,之后将不同模态的全局深层融合特征xfusion(i,j)和局部深层融合特征yfusion(i,j)通道级连接,由decoder模块中的反卷积层进行上采样,重建融合图像。
68、步骤3:训练encoder-decoder模块;
69、本发明通过重建原始输入图像来训练encoder模块和decoder模块的网络参数,损失函数使用图像重建损失和梯度损失,且fusion模块仅在测试阶段保留,在训练阶段移除,如图6所示;
70、步骤3.1:训练迭代中,将训练集中batch_size张ct(或mri)图像输入到由convstem和全局局部特征交互并行transformer(parallel transformer for globallocal feature interaction)构成的encoder网络提取特征,得到图像的全局深层特征xct(或xmri)和局部深层特征yct(或ymri);
71、步骤3.2:将特征提取的结果拼接,输入到由5层反卷积构成的decoder网络重建原始输入图像;
72、步骤3.3:最小化输入ct(或mri)图像与其重建图像之间的图像重建损失和梯度损失更新encoder-decoder网络中的参数θen和θde;以输入为ct图像为例,训练过程如算法1所示。
73、
74、步骤3.3.1:一种全局与局部特征交互并行的多模态医学图像融合方法,需要用损失函数优化encoder和decoder模块,为了得到更精确的重建输入图像,设计了图像重建损失和梯度损失用以训练encoder-decoder网络,网络的总损失函数为:
75、
76、其中是图像重建损失,是梯度损失,α1,α2是权重参数,通过对各部分损失加权来提高重建效果;的作用是让图像信息在编码和解码过程中不丢失,能保留源图像更多的细节和纹理;计算公式如下:
77、
78、
79、
80、
81、其中,iinput表示输入源图像,ioutput表示由encoder-decoder网络生成的重建图像,||a||2表示a的l2范数,表示sobel梯度算子;表示结构损失,ssim是结构相似性运算,计算重建图像和源图像的结构相似度;表示像素损失,通过不断优化网络使重建图像和输入图像更相似;表示重建图像和源图像的像素级梯度差异,n为像素点个数。
82、步骤4:测试全局局部特征交互并行的多模态医学图像融合网络。
83、步骤4.1:测试迭代中,将测试集(test_dataset)中的ct和mri图像分别输入到训练好的encoder网络中,提取图像的全局深层特征xct、xmri和局部深层特征yct、ymri;
84、步骤4.2:利用基于l1-norm的图像序列矩阵融合策略,实现不同模态的全局深层特征融合xfusion(i,j)和局部深层特征融合yfusion(i,j),并将其通道连接;
85、步骤4.3:由训练好的decoder网络将多模态融合特征进行上采样,得到融合图像ifusion。测试过程如算法2所示。
86、
87、本发明中训练数据集来自山西省生物医学成像与影像大数据重点实验室,包含10000张不同尺寸大小的脑部ct和mri图像,测试数据集是从哈佛医学院数据集中选取了21对经过配准后的ct和mri图像。实验的硬件平台是gpu为rtx3060ti 8gb gdr6的服务器;软件平台是操作系统为64位的windows10,虚拟环境为pytorch,python版本为3.7。训练次数设置为40个epoch,batch-size设置为2。选择学习速率为10-4的adam优化器,且每隔20个训练周期进行一次衰减,衰减率为0.5。总损失中的系数α1设置为1,α2设置为5,图像重建损失中的系数λ设置为5。
88、与现有技术相比本发明具有以下优点:
89、本发明提出一种全局与局部特征交互并行的多模态医学图像融合方法,通过在encoder模块中使用由局部多头注意机制构成的local transformer block,解决了基于深度学习的多模态医学图像融合方法中transformer对局部特征提取能力不足的问题。在特征提取过程中引入全局局部特征交互模块,减少了图像全局和局部信息的丢失。从实验结果可知,经本发明提出的方法得到的多模态医学融合图像,主观上细节丰富、纹理清晰,客观上评价指标整体优于其余对比方法,更有利于帮助医生进行临床诊断和有效治疗。
- 还没有人留言评论。精彩留言会获得点赞!