用户侧视角下的工业企业储能安装潜力分层识别方法与流程
本发明涉及电网大数据分析,具体涉及一种用户侧视角下的工业企业储能安装潜力分层识别方法。
背景技术:
1、工业企业是用户侧极为重要的组成部分,目前,对于工业企业用户侧储能模式的方案,如响应分时电价参与峰谷套利、响应两部制电价参与最大需量管理、或结合两种类别构建最大需量管理与削峰填谷相结合的储能配置模型等,对工业企业用户侧储能参与需求响应的方案较少,另外随着数据的不断丰富与积累,进行工业企业用户侧储能潜力的条件已逐渐成熟,故亟需一种从工业企业用户侧视角下探究储能潜力分层识别与评估的方法。
2、用户侧储能潜力识别与评估的技术目前主要有两类:一类是数据分析,另外一类是数据挖掘。
3、(1)数据分析
4、该方法是基于现有数据集的解释、整理、检验和分析过程,以获取对数据的洞察。它使用统计方法和相关技术来揭示数据中的模式、趋势、关联和异常,通过统计推断、可视化等手段对数据进行解释和总结,以支持决策和推动业务发展。
5、例如,有提出通过“构建分布式储能汇聚潜力评估模型”进行用户侧储能评估,具体方法是:首先需要确定评价的基本要素,即将对分布式储能汇聚产生影响的敏感因子作为指标层参数;其次,选取6个代表性的准则因子,准则因子包括动态响应能力因子、容量支撑能力因子、功率支撑能力因子、有效汇聚时间比、系统稳定性因子、系统可靠性因子;最后采用层次分析法计算分布式储能系统汇聚潜力指数,作为分布式储能参与节点汇聚提供出力顺序的评估方法。
6、还有文献提出通过一种“基于数据驱动的用户侧储能安装潜力分层评估方法”进行用户侧储能潜力的识别与评估,具体方法是:首先进行“优先评估”,电力系统发生突发事故和电网崩溃,一些重要方受影响较大,此类重要方的用户侧储能安装潜力最大,优先评估;其次做精细评估、构建评估模型,精细评估从最能吸引用户的要素入手,要素从峰谷差、电压波动、配变容量、企业电费和可靠性五个指标评估,最终通过加权求和的方法得到f值,f值代表用户安装储能的潜力大小,f值越大,代表用户安装储能的潜力越大。
7、(2)数据挖掘
8、数据挖掘是从大规模数据集中发现隐藏的模式、关联、趋势、异常和知识的过程,它利用统计学、机器学习、人工智能等技术方法来自动发现数据集中的规律和模式,帮助发现潜在的洞见和未知的知识,提供决策支持。例如,有通过提取用户负荷特征曲线,聚类处理原始负荷曲线,根据特性指标分析曲线的基本特征计算对应的负荷密度,提取加装储能前后用户的用电变化特征,通过分析用户参与储能用电潜力,利用数据挖掘的方式实现对区域电网中潜在储能用户的挖掘。
9、中国专利《基于多负荷优化配置的用户需求侧配电网规划方法》(申请号:202111399339.x;申请日2021.11.19)其中公开了基于配电网的工业产区内电力值的获取和配电方法,但是对储能潜力并没有提出方案。目前,对用户侧储能的应用都在积极探索,根据用户侧储能的特点建立相应的储能,提高用户侧能源的利用效率,保证电网负荷的稳定性,提高用户侧的用能质量,缓解电网高峰的压力,具有重要的工程实践价值和发展前景。
技术实现思路
1、本发明目的是提供一种用户侧视角下的工业企业储能安装潜力分层识别方法,针对背景技术中的问题,根据用户侧储能的特点建立相应的储能,提高用户侧能源的利用效率,保证电网负荷的稳定性,提高用户侧的用能质量。
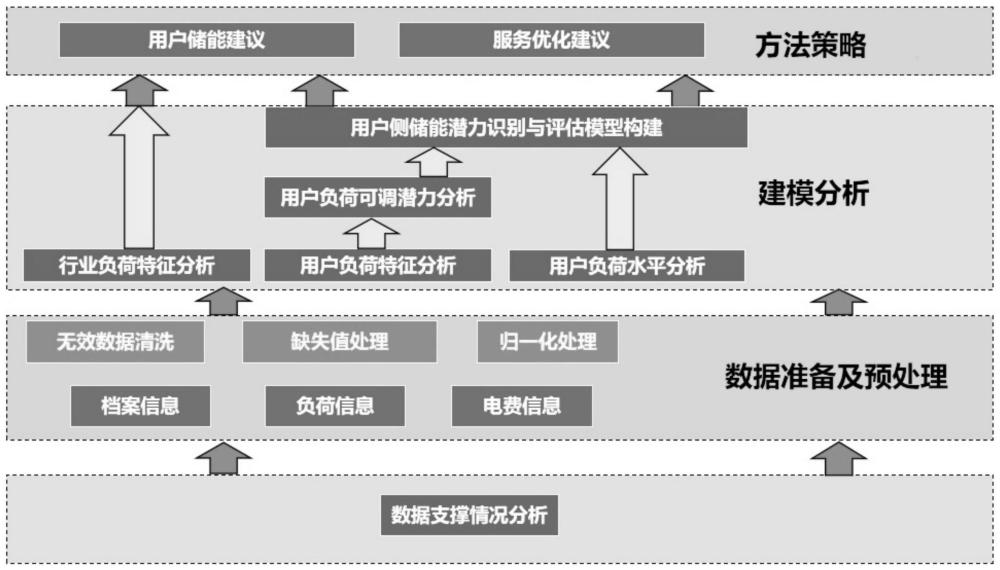
2、为了实现以上目的,本发明采用的技术方案为:一种用户侧视角下的工业企业储能安装潜力分层识别方法,包括如下步骤:
3、一、数据准备及预处理:采集所需数据,包括工业企业用户档案信息、负荷信息;完成采集数据的清洗工作,包括处理缺失值、异常值和噪音数据,对数据进行标准化处理;
4、二、建模分析:开展工业负荷特征分析、用户负荷可调潜力分析、用户负荷水平分析,构建指标;结合用户的指标信息,通过相关分析方法计算各指标的权重,而后根据多个指标与各自权重相乘并求和的方法计算用户综合得分,最后根据综合得分对用户进行分层;包括以下步骤:
5、2.1)、工业负荷特征分析
6、包括根据行业及用户负荷特征数据,通过包括k-means、dbscan、fcm聚类算法对用户历史负荷曲线进行聚类,得到类簇编号及聚类中心,完成用户负荷特征分析;
7、2.2)、用户负荷可调潜力分析
8、评估工业企业用户负荷可调潜力值;
9、2.3)、用户负荷水平分析;
10、2.4)、工业企业用户侧储能潜力识别与评估模型构建
11、构建工业企业用户侧储能潜力识别与评估模型:根据工业企业用户侧储能潜力分层识别与评估需求,结合用户的指标信息,通过包括层次分析法、熵值法、因子分析法相关权重衡量方法计算各指标的权重,而后根据指标与权重相乘并求和的方式计算用户综合权重,最后根据综合权重对用户进行分层,赋予标签;
12、2.5)、储能策略方法库构建
13、构建储能策略方法库:针对不同的用户分层等级对外提出用户储能策略、对内提出服务优化策略,形成储能策略方法库。
14、进一步的,步骤一中所需数据包括工业企业用户的档案信息、负荷信息、电费信息。
15、再进一步的,步骤一中数据预处理包括以下步骤:
16、1.1).数据清洗
17、处理缺失值的方法包括:删除、填充、不处理;其中,删除是将存在缺失值的样本行或特征列删除,得到一个完整的数据集;填充是用设定的值去填充空值,使数据集完整化,根据初始数据集中其余对象取值的分布情况来对一个缺失值进行填充;
18、对于有缺失的数据使用knn算法填充进行填补数据;
19、1.2).数据转换
20、进行数据归一化处理:在进行聚类时使用的归一化方法为零均值归一化(z-scorenormalization);将原始数据映射到均值为0、标准差为1的分布上;具体的,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为:
21、
22、1.3).数据集成
23、数据建模分析前进行集成拼接,去冗余;包括将聚类结果数据与行业档案数据集成在一起,建立数据分析挖掘宽表。
24、进一步的,步骤2.1)中所述行业及用户负荷特征数据包括进行工业行业负荷特征分析,总结行业的负荷特征与规律数据;基于用电用户档案信息、日频度负荷多源数据。
25、进一步的,步骤2.1)中行业负荷特征分析是通过对所有工业子行业用电负荷的分析,总结每个子行业的负荷特征与规律;通过分析同一行业内不同用户之间的用电负荷特征,分析同一行业内不同用户之间的用电负荷特征是否存在差异;通过分析不同行业之间的用电负荷特征,不同行业之间的用电负荷特征是否存在相似性;
26、用户负荷特征分析是通过k-means、dbscan、fcm聚类算法对用户历史负荷曲线进行聚类,得到类簇编号及聚类中心,而后对每一类的负荷特征进行分析刻画,完成用户负荷特征分析。
27、再进一步的,选用k-means聚类算法;该算法聚类过程是:(1)设定k值、确定聚类数;(2)计算每个记录到类中心的距离,并分成k类;(3)将k类中心作为新的中心,重新计算距离;(4)不断迭代,直至所有的数据无法更新到其它的数据集中;
28、其中,聚类k值确定方法:戴维森堡丁指数;戴维森堡丁指数计算的是davies-bouldin得分,自动化计算k值,公式是:
29、
30、其中,dbi是指标值,为第i类样本到其类中心的平均欧氏距离,为第j类样本到其类中心的平均欧氏距离,||wi-wi||2是为第i和第j类的类中心欧氏距离。
31、进一步的,步骤2.2)中基于用户在各个时点的负荷数据及工业负荷特征分析部分的聚类结果,使用相关指标对负荷可调潜力进行量化分析;
32、其指标选择:通过最可能调节量、最大可调节量两个指标进行负荷可调潜力的分析,最可能调节量、最大可调节量均为运行日指定的一个时间段内的负荷可调节量,最可能调节量为基线负荷与其所属用电类别中最低负荷的差值,最大可调节量为基线负荷与最小负荷用电类别平均负荷的差值,其中基线负荷由运行日的前三十天负荷平均值计算得到;
33、
34、δht=xt-min(xc)
35、δpt=xt-mean(xe)
36、其中,xt是基线负荷,n设定为30,xc是基线负荷所属用电类别中的簇类负荷,δht是最可能调节量,xe是最小负荷用电簇类负荷,δpt是最大可调节量。
37、进一步的,步骤2.3)中基于用户日频度历史负荷大数据计算其最大负荷、平均负荷,最大负荷、平均负荷均为运行日指定的一个时间段内的负荷值;最大负荷为用户的负荷最大值,平均负荷为负荷平均值;
38、hmax=max(xij)
39、hmean=mean(∑xij)
40、其中,xij为某一天某一时点的负荷。
41、进一步的,,步骤2.4)中指标信息包括最可能调节量、最大可调节量、最大负荷、平均负荷、峰谷波动度、单位容量最大负荷、单位容量电费;
42、所述峰谷波动度:
43、若用户负荷峰谷差达到设定额度,以及超过该用户的平均负荷,则此用户具有储能的潜力,最小负荷的计算方式与最大负荷相同,为负荷最小值;具体公式为:
44、
45、其中hmax表示最大负荷、hmin表示最小负荷、表示平均负荷;
46、所述单位容量最大负荷:
47、若用户负荷峰值高于该用户的运行容量,则此用户具有储能的潜力,具体公式为:
48、l=hmax/q
49、其中hmax表示最大负荷、q表示用户运行容量;
50、所述单位容量电费:
51、用户电费与运行容量的比值越大,则此用户越具有储能的潜力,具体公式为:
52、c=pt/q
53、其中pt表示电费、q表示用户运行容量;
54、通过层次分析法、熵值法或因子分析法方法计算各指标的权重,最终将每个指标值与各自权重相乘并求和的方法计算用户综合得分,公式为:
55、
56、其中wi表示权重、xi表示指标。
57、再进一步的,计算指标权重的方法选择熵值法,其算法步骤如下:
58、指标归一化处理
59、先对各项指标的计量单位进行标准化处理,即把指标的绝对值转化为相对值,而且对于正负向指标使用不同的算法进行数据标准化处理;因本模型涉及到的七项指标均为正向指标,其标准化方法如下:
60、
61、其中,xij代表第i个用户第j个指标数值(i=1,2,...,n;j=1,2...,m)。
62、计算指标比重
63、计算归一化后的各项x′ij值在当前列指标数据中的比重;
64、
65、计算第j项指标熵值
66、通过上述各项x′ij值在当前列指标数据中的比重,计算第j项指标熵值;
67、
68、其中,k=1/ln(n)>0;
69、计算信息熵冗余度
70、dj=1-ej
71、计算各项指标权重
72、
73、本发明的技术效果在于:本发明的一种用户侧视角下的工业企业储能安装潜力分层识别方法,根据用户侧储能的特点建立相应的储能,提高用户侧能源的利用效率,保证电网负荷的稳定性,提高用户侧的用能质量。
- 还没有人留言评论。精彩留言会获得点赞!