多版本文件比对方法、装置、系统及存储介质与流程
本技术属于大数据信息处理,尤其涉及一种多版本文件比对方法、装置、系统及存储介质。
背景技术:
1、在投标人编制标书过程中,需要经过多轮编辑和修正,期间可能会调整项目经理,报价信息,资质证书等材料。如果一个投标单位,在修正过程中出现修改遗漏的情况,例如投标函中的项目经理和投标人基本信息表中项目经理信息不一致情况,会导致投标单位在本次投标过程中废标。
2、针对该问题,为投标人提供标书多个版本的核对技术,投标人基于该技术能力,快速实现标书多个版本编辑过程中变更修订的内容,包括文件硬件信息、经济标清单差异、技术标文档变更内容等。通过快速的投标文件比对,方便投标单位快速发现并定位标书的变更内容。
3、目前对文本内容的比对,可以通过pdf解析工具或文本提取库,将pdf文档中的文本内容提取出来,并进行对比。可以使用字符串匹配算法,如levenshtein距离、最长公共子序列,或基于文本相似性的算法,如余弦相似度、jaccard相似度等,来比较文本之间的差异。使用此类算法对pdf文件进行比对时,存在一些技术缺陷:
4、格式差异:pdf文件可以包含复杂的排版、字体样式、图表等多种元素,而字符串匹配算法只能基于字符级别的比较,无法处理这些格式差异。因此,在字符串匹配算法中,即使两个pdf文件在内容上相似但在格式上有微小差异,也可能导致较大的匹配误差。
5、信息丢失:pdf文件中的文本内容可能经过压缩、加密或其他处理,导致部分信息丢失或变换。字符串匹配算法在比对过程中可能无法准确处理这些变换,从而导致识别错误或丢失关键信息。
6、文本重排:pdf文件中的文本内容可以被重新排列,改变原始文档的布局和顺序。字符串匹配算法通常依赖于字符串的顺序性,当文本重排时,匹配算法可能无法正确找到相应的匹配项。
7、大规模处理效率低下:pdf文件往往包含大量文本内容,如处理大规模pdf文件集合时,字符串匹配算法的效率可能较低。因为字符串匹配算法需要比较每个字符或子串,时间复杂度可能较高,造成处理时间过长或资源消耗较多。
技术实现思路
1、本技术的目的,在于提供一种多版本文件比对方法、装置、系统及存储介质,结合文件的结构化数据和非结构化数据,以及文件中存在的图片、文本和表格形式内容,基于自然语言处理技术进行多版本文件比对。
2、为了达成上述目的,本技术的解决方案是:
3、第一方面,本技术实施例提供了一种多版本文件比对方法,包括:
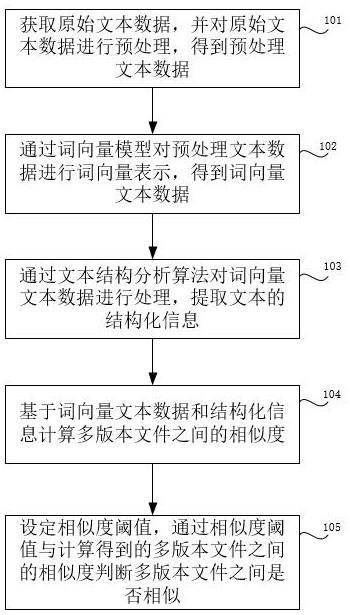
4、获取原始文本数据,并对原始文本数据进行预处理,得到预处理文本数据;
5、通过词向量模型对预处理文本数据进行词向量表示,得到词向量文本数据;通过文本结构分析算法对词向量文本数据进行处理,提取文本的结构化信息;
6、基于词向量文本数据和结构化信息计算多版本文件之间的相似度;设定相似度阈值,通过相似度阈值与计算得到的多版本文件之间的相似度判断多版本文件之间是否相似,判断方法包括:
7、若多版本文件之间的相似度高于相似度阈值,则判断多版本文件之间相似,若多版本文件之间的相似度低于相似度阈值,则判断多版本文件之间不相似。
8、根据本技术实施例的上述方法,还可以具有以下附加技术特征:
9、进一步的,对原始文本数据进行预处理,包括:通过pdf解析工具提取原始文本数据的文本内容,对文本内容进行清洗和规范化处理;pdf解析工具包括pypdf2和pdfplumber;清洗和规范化处理包括:去除特殊字符、去除标点符号和统一大小写。
10、进一步的,词向量模型包括word2vec、glove和bert;文本结构分析算法包括段落识别、标题识别和表格解析,基于词向量文本数据和结构化信息计算多版本文件之间的相似度,包括:基于词向量文本数据计算多版本文件之间的内容相似度和基于结构化信息计算多版本文件之间的结构相似度。
11、进一步的,基于词向量文本数据计算多版本文件之间的内容相似度,包括:计算每个文件的词向量平均或对每个文件的词向量进行加权求和计算,通过度量方法计算多版本文件之间的内容相似度,度量方法包括余弦相似度、杰卡德相似系数和汉明距离;相似度值与多版本文件之间的内容相似度呈正相关。
12、进一步的,基于结构化信息计算多版本文件之间的结构相似度,包括:通过匹配算法计算多版本文件之间的结构相似度,匹配算法包括编辑距离和最长公共子序列。
13、进一步的,设定相似度阈值,根据具体需求和实际数据集进行设定;根据相似度比对结果,生成比对报告,比对报告包括相似内容的摘要、差异点的标记和详细的对比信息。
14、进一步的,通过并行处理技术和分布式计算框架对大规模的多版本文件进行处理,包括:通过并行处理技术将比对任务划分为多个子任务同时进行;通过分布式计算框架将比对任务分发到多个计算节点上进行并行处理。
15、第二方面,本技术实施例提供了一种多版本文件比对装置,装置包括:
16、数据获取模块,被配置为用于获取原始文本数据;
17、数据处理模块,被配置为用于对原始文本数据进行预处理、词向量处理和结构分析处理;
18、文件比对模块,被配置为用于计算多版本文件之间的相似度,并根据设定的相似度阈值判断多版本文件之间是否相似,若多版本文件之间的相似度高于相似度阈值,则判断多版本文件之间相似,若多版本文件之间的相似度低于相似度阈值,则判断多版本文件之间不相似。第三方面,本技术实施例提供了一种多版本文件比对系统,系统包括处理器和存储器,存储器中存储有计算机程序,计算机程序由处理器加载并执行,以实现如本技术实施例第一方面提供的多版本文件比对方法。
19、第四方面,本技术实施例提供了一种计算机可读存储介质,存储介质中存储有计算机程序,计算机程序被处理器执行时,用于实现如本技术实施例第一方面提供的多版本文件比对方法。
20、采用本技术实施例提供的多版本文件对比方法,与现有技术相比,具有如下有益技术效果:
21、1、考虑语义信息:自然语言处理技术可以理解文本的语义信息,而不仅仅是单纯的字符匹配。通过识别文本中的语言结构、语义关系和上下文含义等更准确地比对两个pdf文件之间的差异。
22、2、弹性处理格式差异:pdf文件通常具有复杂的排版、字体等格式差异,而自然语言处理技术在一定程度上弹性处理这些差异。它可以忽略不同的字体、大小、颜色等变化,专注于比对文本内容的实质和意义。
23、3、结构化信息分析:自然语言处理技术将pdf文件中的文本内容进行结构化分析,识别出段落、标题、表格等信息,并在比对过程中考虑到这些结构信息提高对比结果的准确度和可读性。
24、4、处理文本重排:pdf文件中的文本内容可能会重新排列,改变原始文档的布局和顺序。自然语言处理技术可以灵活地处理文本重排,通过词向量模型或句法分析等方法,识别出相似的句子或段落,从而正确找到匹配项。
25、5、支持大规模处理:自然语言处理技术可以应用于大规模的pdf文件集合,通过并行计算、分布式处理等方法,提高处理效率和可扩展性。相比于字符串匹配算法,它能够更快速地处理大量文本数据。
- 还没有人留言评论。精彩留言会获得点赞!