一种表格信息的识别方法与流程
本发明属于表格信息提取,具体涉及一种表格信息的识别方法。
背景技术:
1、在从各类型的财务发票、清单等图像数据中提取关键信息过程中,由于信息字段密集、版式多变且具有自身的特殊性等各种原因,已有通用模型对于这些复杂情况适应性较差,信息提取准确率还亟待提高。当前性能最好的表格信息提取模型,例如百度公司研发的最新表格识别模型slanet、海康威视研发的lgpma表格识别模型对于有横竖表格线,但表格内文字密集、单元格内存在多行等情况容易出现漏检单元格、表格单元错位、单元格粘连、同一单元格内的多行文本错分到不同单元格等问题;而对于销售货物或者提供应税劳务服务清单、电子发票类的表格,不仅文字密集、单元格内存在多行而且缺乏表格线,出现上述错误的概率非常高。
2、总之,现有的表格识别模型识别表格信息的准确率不高。
技术实现思路
1、为了克服上述现有技术存在的不足,本发明提供了一种表格信息的识别方法。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种表格信息的识别方法,包括:
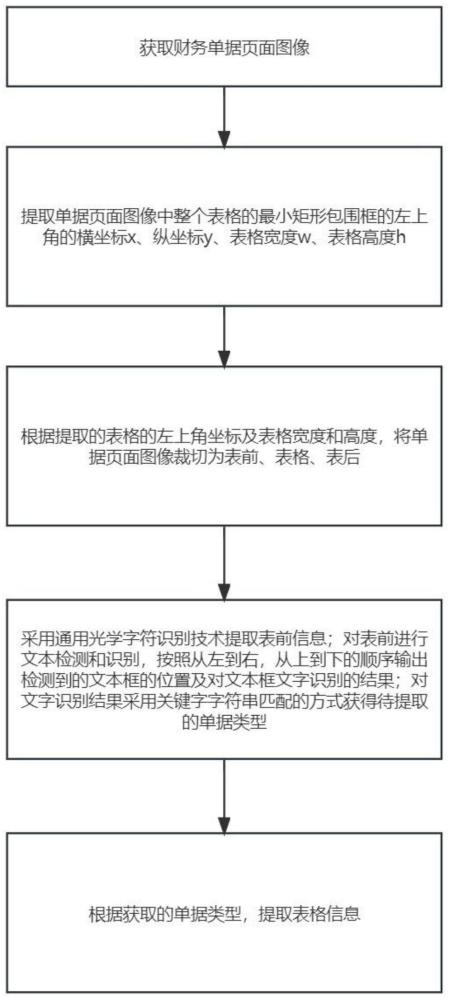
4、获取单据的页面图像;
5、提取页面图像中,表格的表格宽度w、表格高度h,单元格的左上角的横坐标x、纵坐标y;
6、根据表格宽度w和表格高度h,提取页面图像中的表前信息和表格;
7、采用通用光学字符识别技术ocr对表前信息进行文本检测和识别,按照从左到右,从上到下的顺序输出检测到的文字识别结果;并对文字识别结果采用关键字字符串匹配的方式得到单据类型;
8、根据单据类型以及单元格的左上角的横坐标x、纵坐标y,逐格对表格中的文本信息进行识别。
9、进一步,所述提取页面图像中,表格的单元格的左上角的横坐标x、纵坐标y;包括:
10、将财务单据页面图像转为灰度图,对灰度图进行自适应阈值二值化后取反;
11、构造一条横线模板,用横线模板对灰度图进行腐蚀后进行膨胀操作,得到只保留原图像中所有横线的横线图;
12、构造一条竖线模板,用竖线模板对灰度图进行腐蚀后进行膨胀操作,得到只保留原图像中所有竖线的竖线图;
13、截取穿过横线图中心位置的一条长度为图像高度的竖线;查找竖线上所有像素值非零的点的纵坐标,并从像素值非零的点集中取纵坐标相邻的多个点的中心坐标为横线的纵坐标,依次获得横线图中从上到下的横线的纵坐标(y1,y2,……);
14、截取穿过竖线图中心位置的一条长度为图像宽度的横线;查找横线上所有像素值非零的点的横坐标,并从这些像素值非零的点集中取横坐标相邻的多个点的中心坐标为竖线的横坐标,依次获得竖线图中从左到右的竖线的横坐标(x1,x2,……)。
15、进一步,当页面图像中的表格为具有完整表格线表格时,对表格中的文本信息进行识别;包括:
16、从左向右,从上向下逐格截取表格图像中的单元格图像;
17、以单元格图像的左上角为原点,水平向右为x轴的正方向,水平向下为y轴的正方向;
18、设置线宽阈值,将单元格图像的左上角坐标的x、y坐标分别加上线宽阈值的一半,同时将单元格右下角x、y坐标分别减去线宽阈值的一半,得到提取后的文本信息;
19、利用ocr模型对提取后的文本信息进行识别。
20、进一步,当页面图像中的表格为具有纵向表格线,无横向表格线,且具有行标号列的表格时,对表格中的文本信息进行识别;包括:
21、截取表格信息字段行的单元格图像;
22、截取每个信息字段所对应的列的图像,将其送入通用ocr模型识别文本,ocr模型输出识别出的文本内容、以及包围文本的文本框的四个角的坐标;
23、其中:
24、对于识别出的文本内容,如果某一行文本的开头字符不为*,则判断该行文本与上一行文本属于同一个单元格;判断文本框的纵向坐标与行标号列的文本框的纵向坐标是否有交集,如果有交集则判断文本框与对应行标号的文本属于同一表格行。
25、进一步,当表格为既没有横线也没有纵线的表格时,对表格中的文本信息进行识别;包括:
26、将图像送入ocr模型,利用ocr模型输出识别出的文本内容、以及包围文本的文本框的四个角的坐标;
27、遍历文本框的纵坐标;对相邻文本框左上角的纵坐标之间差值高于50%字符高度阈值的为前后行关系,否则为同一行;其中字符高度阈值取多个文本框纵轴方向长度的平均值;
28、根据包围文字的文本框的坐标判断文本属于哪个表格行和哪个表格列。
29、进一步,所述根据包围文字的文本框的坐标判断文字属于哪个表格行和哪个表格列;包括:
30、判断每一行文本属于新的表格行还是属于上一表格行;
31、对于属于新的表格行的文本行,通过比较计算文本框在横轴方向的中点坐标与第一行的表格字段文本框的横轴方向中点的距离,将各文本框归属到相应的表格行;
32、对于属于上一个表格行的文本行,计算延续的文本行的各个字段与上一个文本行的各个字段文本框在横轴方向的包含度,包含度大于50%则与上一行对应字段同属于一个表格列;
33、所述包含度的计算包括:
34、延续行文本框横轴坐标范围属于上一文本行某信息字段文本框的横轴坐标范围内的长度除以延续行文本框横轴方向长度。
35、进一步,所述判断新的文本行属于新的表格行还是上一表格行的延续;包括:
36、如果第一个字段文本以行标识符开头,则为新表格行,否则则为上一表格行的延续。
37、进一步,还包括:
38、如发现某行的信息缺失,检查相关字段文本中是否存在空格,如存在空格,则在第一个空格处将该文本行拆分,否则提示检测识别出错。
39、本发明提供的一种表格信息的识别方法具有以下有益效果:
40、本发明提取财务单据的图像后,提取了图像中整个表格的坐标信息,根据表格整体坐标信息将财务单据分为表前信息和表格,以便根据表头文字识别出表格的类型,并进一步根据不同的表格类型,逐格对表格中的内容进行信息识别。由于是对表格中的内容单独进行识别,而不是大量的内容混杂识别,够能显著提高识别的准确率。解决了现有技术中,不能准确的识别表格中的信息的问题。
技术特征:
1.一种表格信息的识别方法,其特征在于,包括:
2.根据权利要求1所述的一种表格信息的识别方法,其特征在于,所述提取页面图像中,表格的单元格的左上角的横坐标x、纵坐标y;包括:
3.根据权利要求1所述的一种表格信息的识别方法,其特征在于,当页面图像中的表格为具有完整表格线表格时,对表格中的文本信息进行识别;包括:
4.根据权利要求1所述的一种表格信息的识别方法,其特征在于,当页面图像中的表格为具有纵向表格线,无横向表格线,且具有行标号列的表格时,对表格中的文本信息进行识别;包括:
5.根据权利要求1所述的一种表格信息的识别方法,其特征在于,当表格为既没有横线也没有纵线的表格时,对表格中的文本信息进行识别;包括:
6.根据权利要求5所述的一种表格信息的识别方法,其特征在于,所述根据包围文字的文本框的坐标判断文字属于哪个表格行和哪个表格列;包括:
7.根据权利要求6所述的一种表格信息的识别方法,其特征在于,所述判断新的文本行属于新的表格行还是上一表格行的延续;包括:
8.根据权利要求6所述的一种表格信息的识别方法,其特征在于,还包括:
技术总结
本发明提供了一种表格信息的识别方法,属于表格信息提取技术领域,包括:获取单据的页面图像;提取页面图像中,表格的表格宽度w、表格高度h,单元格的左上角的横坐标x、纵坐标y;根据表格宽度w和表格高度h,提取页面图像中的表前信息和表格;采用通用光学字符识别技术OCR对表前信息进行文本检测和识别,按照从左到右,从上到下的顺序输出检测到的文字识别结果;并对文字识别结果采用关键字字符串匹配的方式得到单据类型;根据单据类型以及单元格的左上角的横坐标x、纵坐标y,逐格对表格中的文本信息进行识别。该方法能够提取表格中的信息。
技术研发人员:杨玉燕,贺锋,王建松,张威,黄杰
受保护的技术使用者:广东烟草梅州市有限公司
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!