一种基于门控图神经网络的候选事件预测方法与流程
本发明提供了一种基于门控图神经网络的候选事件预测方法,以支持各领域知识图谱的智能推理应用。其涉及人工智能、图神经网络和知识图谱等相关领域。
背景技术:
1、理解文本中描述的事件对于许多人工智能应用至关重要,例如话语理解、意图识别和对话生成。候选事件预测是这一行工作中最具挑战性的任务,其定义为给出一个现有的事件上下文,需要从候选列表中选择最合理的后续事件。之前的研究要么基于事件对构建预测模型或事件链。尽管成功地使用了事件对和事件链,但事件之间的丰富联系并没有得到充分的探索。
2、为了更好地对事件连接进行建模,我们提出解决基于事件演化图结构的候选事件预测问题,并基于门控图神经网络推断正确的后续事件。进一步的,我们在训练过程中借用了分而治之的思想,提出了一种适用于大规模图的缩放图神经网络,即网络每次只处理相关节点,而不是计算整个图上的表示。
技术实现思路
1、发明目的:本发明旨在提出一种基于门控图神经网络的候选事件预测方法,它可以在大规模密集的有向图上建模事件交互,并学习更好的事件表示用于预测候选事件,从而支持各领域知识图谱的智能推理应用。
2、为了解决上述技术问题,本发明采用的技术方案是:
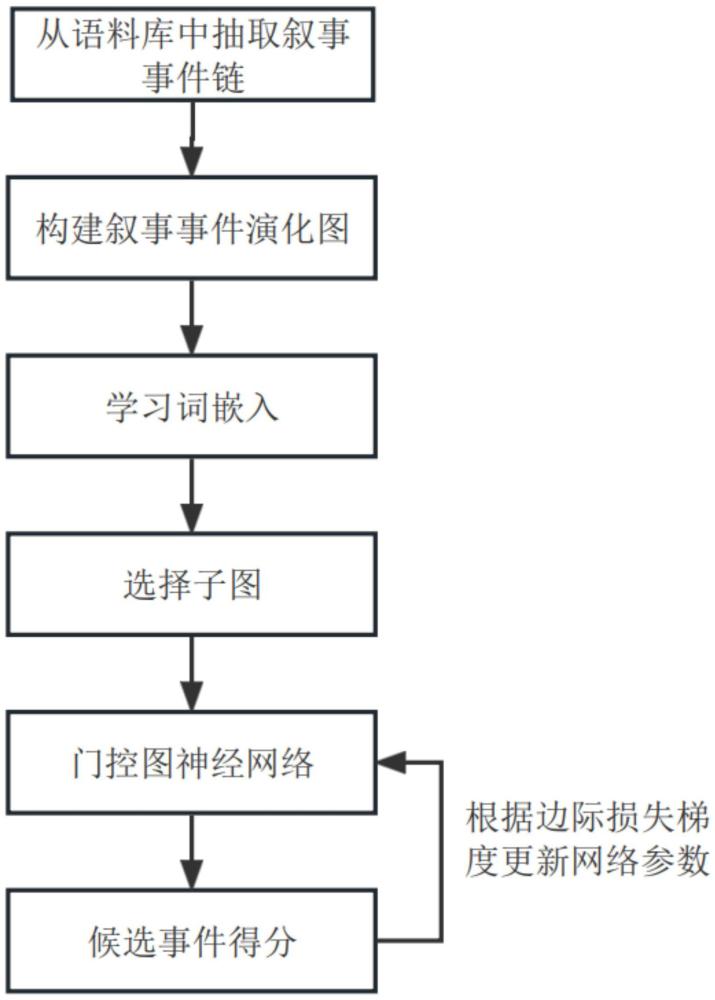
3、一种基于门控图神经网络的候选事件预测方法,包括以下步骤:
4、步骤1,首先从语料库中对历史事件进行事件抽取以形成叙事事件链;
5、步骤2,然后基于所提取的叙事事件链构建一个叙事事件演化图neeg,叙事事件演化图看作是存储事件演化原则和模式的知识库;
6、步骤3,通过组合事件中动词和名词的预训练词嵌入来学习初始事件表示;
7、步骤4,对于每个训练实例,只向其中馈送一个具有上下文和候选事件节点的子图;
8、步骤5,将子图输入到提出的门控图神经网络ggnn中,输出各个候选事件的得分;
9、步骤6,使用边际损失更新模型参数;
10、进一步的,所述步骤1包括:
11、步骤11:数据的来源是语料库中的历史事件,由非结构化的自然语言描述。事件抽取是指从文本中抽取出对人类有用的信息事件,并以结构化的形式表示出来。结构化的形式表示写为{主语;动作;宾语;间接宾语};设事件x{主语x;动作x;宾语x;间接宾语x}先于事件y{主语y;动作y;宾语y;间接宾语y},则{主语x;动作x;宾语x;间接宾语x}->{主语y;动作y;宾语y;间接宾语y};->表示事件的先后顺序。
12、步骤12:提取了一组叙事事件链s={s1,s2,...,sn},其中si={t,e1,e2,...,em}。t是这个链条中所有事件共有的主角实体。ei是由四个成分(p(a0,a1,a2))组成的事件,其中p是谓语动词,a0,a1,a2分别是动词的主语、宾语和间接宾语;然后,按照时间顺序将s加入s中;最后,返回s。
13、进一步的,所述步骤2包括:
14、步骤21:首先确定文本中每个实体的文本范围并进行标注。然后,根据上下文信息确定哪些实体之间存在共指关系。设有一组事件e={e1,e2,...,en},其中每个事件ei都有一个标识符id,为了克服事件的稀疏性问题,将事件ei抽象表示为(vi,vr)的形式,其中vi是谓语动词表示,vr是谓语动词vi对实体对象t的语法依存关系。那么用一个n×n的邻接矩阵k来表示事件之间的关系,其中kij表示事件ei和事件ej之间的关系,通过下面的式子计算,其中count(vi,vj)表示(vi,vj)出现在全部事件链中的频率。
15、
16、其中,(vi,vj)是指两个节点之间共同出现,vk是指跟vi节点存在边关系的节点。
17、步骤22:叙事事件演化知识图谱表示为g={v,l},其中v={v1,v2,...,vp}为节点集,l={l1,l2,...,lq}是边集。具体地,节点集的节点来自事件的主角对象t和谓语动词表示vi;边集来自事件与事件之间的关系kij。
18、进一步的,所述步骤3包括:
19、步骤31:使用deepwalk算法在构建的neeg上训练谓语动词的嵌入,并使用skipgram算法在叙事事件链上训练参数a0,a1,a2的嵌入。
20、进一步的,所述步骤4包括:
21、步骤41:为了扩展到大规模图,在训练过程中不将整个图馈送到ggnn中。相反,对于每个训练实例,只向其中馈送一个具有上下文和候选事件节点的子图。最后,使用学习到的节点表示来解决图上的推理问题。
22、进一步的,所述步骤5包括:
23、步骤51:ggnn的输入是两个矩阵h0和a,其中h0包含初始上下文和后续候选事件的嵌入向量,而a是对应的子图邻接矩阵,这里邻接矩阵a决定了子图中的节点如何相互作用。ggnn的基本递归式是:
24、a(t)=ath(t-1)+b
25、z(t)=σ(wza(t)+uzh(t-1))
26、r(t)=σ(wra(t)+urh(t-1))
27、c(t)=tanh(wa(t)+u(r(t)⊙h(t-1)))
28、h(t)=(1-z(t))⊙h(t-1)+z(t)⊙c(t),
29、其中,a(t),z(t),r(t),c(t),h(t),b,wz,uz,wr,ur,w,u含义分别为:a(t)是节点与相邻节点之间通过边的相互作用的结果,z(t)是更新门,r(t)是重置门,c(t)是新产生的信息,h(t)是最终更新的节点状态,b是偏移量,wz是更新门对a(t)的权重,uz是更新门对h(t-1)的权重,wr是重置门对a(t)的权重,ur是重置门对h(t-1)的权重,w是新产生的信息对a(t)的权重,u是新产生的信息对h(t-1)的权重。σ是逻辑sigmoid函数,tanh是tanh激活函数,⊙是张量积。ggnn的行为类似于广泛使用的门控循环单元gru。公式通过有向邻接矩阵a在图的不同节点之间传递信息的步骤,该步骤包含来自边缘的激活。剩下的是类似于gru的更新,它结合了来自其他节点和前一个时间步的信息,以更新每个节点的隐藏状态。将上述循环传播展开固定步数t,ggnn的输出h(t)用作上下文和候选事件的更新表示。
30、步骤52:在获得每个事件的隐藏状态后,使用这些隐藏状态向量对事件对关系进行建模。对两个事件之间的关系进行建模的一种直接方法是使用余弦距离:
31、
32、其中,hi(t)是指节点vi在t时刻的嵌入表示,hcj(t)是指节点vi的某个候选节点vcj在t时刻的嵌入表示。给定每个上下文事件与每个后续候选事件之间的关联度得分sij,那么通过c=maxjsj来选择正确的后续事件,其中表示候选事件的平均得分。
33、进一步的,所述步骤6包括:
34、步骤61:所有的超参数都在验证集上进行了调优,使用边际损失作为目标函数:
35、
36、其中sij是第i个事件上下文与对应的第j个后续候选事件之间的相关性得分,y是正确的后续事件的索引。margin是边际损失函数参数。θ是模型参数集合。λ为l2正则化的参数。模型参数通过rmsprop算法进行优化。提前停止用于判断何时停止训练循环。
37、与现有技术相比,本发明的有益效果:
38、(1)通过采用故事事件演化图的构建方法,本发明解决了脚本事件预测问题,使得模型能更有效地利用事件网络信息。
39、(2)本发明以图谱形式展示情报信息,具备丰富的可视化功能,从而使得信息直观易懂。决策者可以直观地获取信息、发现规律和趋势,从而提高决策质量和速度。
40、(3)本发明采用基于规则的事件抽取和事件关系抽取方法,能够快速准确地提取和分析各类情报信息。在事件链生成和边权值计算等环节中,实时更新和调整信息,以适应快速变化的战场环境,为决策提供及时准确的支持。
- 还没有人留言评论。精彩留言会获得点赞!