一种用于海关进出口商品规范申报的智能化自动识别方法
本发明涉及一种用于海关进出口商品规范申报的智能化自动识别方法,属于自然语言处理领域。
背景技术:
1、海关进出口贸易在促进国际贸易、提高国内产业水平、加强国际交流等方面都发挥着重要的作用,对经济生活具有深远的影响。
2、进出口商品申报信息规范申报审核是海关根据《中华人民共和国海关进出口商品规范申报目录》以及《中华人民共和国海关进出口货物报关单填制规范》判断海关进出口货物的申报信息是否符合标准,以确保申报信息的准确性和通商的合法性。该过程包括以下几个环节:1.商品申报:进出口企业在海关系统中填写申报表,提供商品的基本信息、分类、价值、数量等。2.申报审核:海关根据国家相关法规和规定,审核进出口商品申报信息的准确性和合法性,以避免涉及违禁品、侵权品、仿冒品等问题。3.数据传输:审核通过后,海关将商品申报信息传输给其他相关机构,例如商检、外汇管理等机构,以实现跨部门协同管理。4.审价、征税:海关根据申报信息对商品的价值和应缴税款进行计算,并向企业征收相应的进口税、增值税等。规范化的进出口商品申报信息可以提高海关的监管效率,减少申报错误和违法行为;还可以降低进出口企业的成本和风险,促进贸易便利化和进出口贸易的平稳进行。通过海关规范申报审核,海关能够确保进出口企业的申报信息真实准确,避免违规行为的发生,保障国家利益和消费者权益。
3、如果进出口企业的商品申报信息不规范,那么它们将不得不面对额外的成本和承担更高的海关管理风险。因此,对海关申报信息的规范审核毫无疑问成为了通商过程中非常关键的一环。首先,由于不规范申报的情况较为复杂,商品申报信息存在漏填、错填以及格式不规范等种种情况,仅依靠人工检查难免会出现疏漏。其次,随着海关贸易量连年提高,海关申报文本信息数据量也随之攀升,人工审查方式的效率很低导致无法满足工作要求,从而导致商品通关效率降低;将自然语言处理技术(natural language processing,nlp)应用到规范申报任务中,通过设计智能分类模型自动地对申报文本进行审核,可以提高规范申报审核的工作效率,降低经济成本,并使规范申报审核任务变得智能化、科学化。
4、规范申报审核本质上属于文本分类的应用领域,但又与传统文本分类任务有所不同,主要是由于其正类样本格式要求较为严格,且某些重要信息分布零散,语义不连续。因此与传统任务相比,规范申报审核较为困难。因此,如何让模型更好地学习出正负样本数据的特征规律成为规范申报审核的重点。
5、目前,词嵌入是自然语言处理中的重要任务之一。传统的词嵌入模型存在一定的局限性,例如表达退化等问题。因此,需要一种能够生成新的词嵌入并对其进行优化的方法,以提高模型的性能和鲁棒性。bert等以transformer为主要结构的预训练模型的文本表示存在表达退化问题,此类模型学习到的文本表示都集中在低维的狭窄锥型空间,其余大量空间没有得到利用。此外由于预训练模型具有较大的预训练权重,这就容易导致过度参数化问题的产生。当文本数据量不够充分时,很容易导致模型过拟合。由于本项工作中负类样本的数据量较少,很容易产生此类问题。本发明将预训练模型的词嵌入所处在的狭窄锥型空间称为流形内空间,其余未利用的空间称为流形外空间。并创新性地构建了gdb(generator-discriminator optimization-bidirectional encoder representationfrom transformers)模型,该模型通过词嵌入生成器和词嵌入判别器联合优化,合成处于流行外空间的词嵌入。在原来训练过程的基础上,用合成的词嵌入对模型进一步微调,达到对词嵌入空间正则化的目的,从而缓解表达退化问题;其次,对模型生成的向量表示用卷积神经网络进一步提取特征,加强对局部信息语义的理解。
技术实现思路
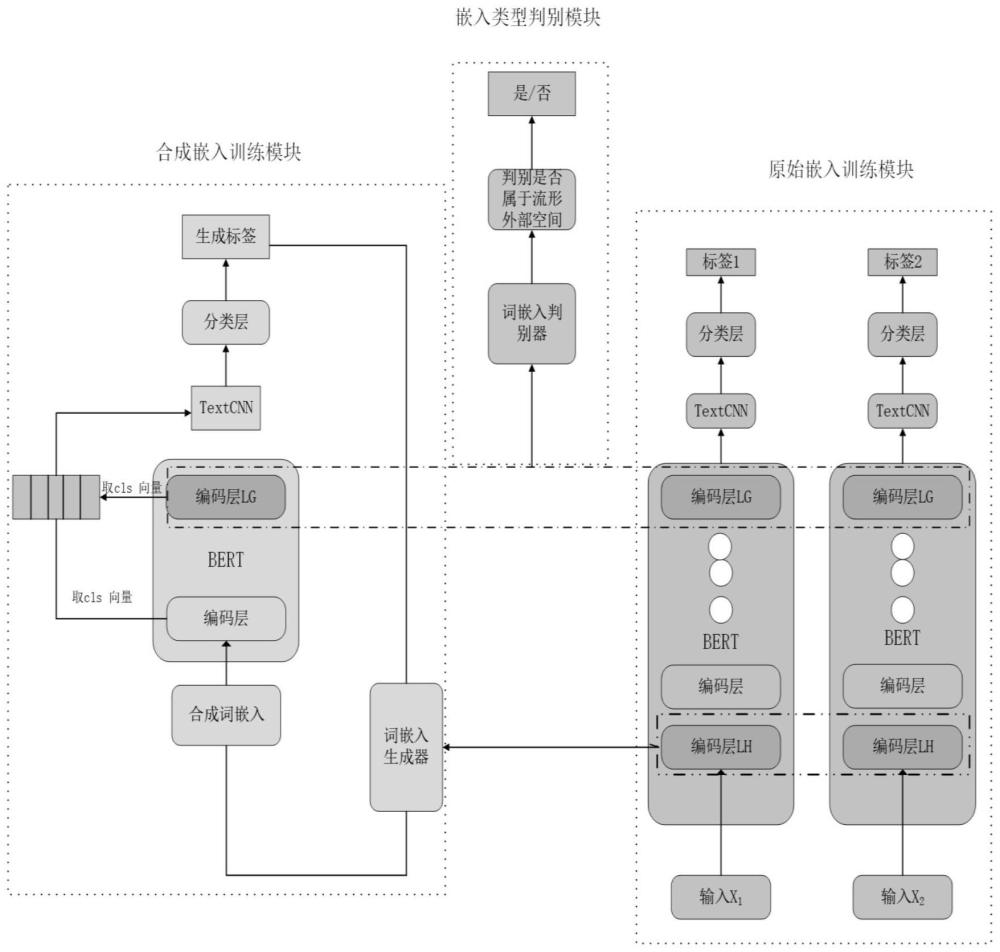
1、gdb模型由三个模块组成,整体架构如图1所示,分别为原始嵌入训练模块、合成嵌入训练模块以及嵌入类型判别模块。gdb模型利用了对抗学习网络的思想以及mix-up数据增强的方法来生成新的词嵌入,并对模型进行正则化,具体包括:
2、步骤1:构建原始嵌入训练模块,将预处理后的海关进出口商品申报文本数据输入bert模型中,经过编码层进行向量表征,再经过卷积操作捕获局部特征,池化操作压缩向量,最后通过分类层得到分类结果并对模型进行微调;
3、步骤2:构建合成嵌入训练模块,在步骤1的基础上通过提取原始嵌入训练模块中的编码层lh的两个向量表示输入到词嵌入生成器中,生成合成词嵌入表示。在bert网络编码层中提取第二层至最后一层的[cls]向量连接在一起作为表征向量,通过卷积操作进一步提取特征进行训练并微调网络,最终达到对流形外空间的正则化目的,从而缓解表达退化;
4、步骤3:构建嵌入类型判别模块,在步骤1和步骤2的基础上,提取原始嵌入训练模块和合成嵌入模块中lg层的编码向量作为输入,通过判别输入的向量类别是否属于流形外部空间来优化词嵌入;
5、步骤4:模块整合进行联合训练,在步骤1-3的基础上,联合多种损失函数构建总体损失,对模型参数进行训练更新。
6、本发明的有益效果:
7、本发明提出的gdb模型通过联合词嵌入生成器和词嵌入判别器,对流形外空间进行正则化,缓解了预训练模型bert中存在的表达退化的问题。并联合卷积神经网络进一步提取文本特征,捕捉文本中的局部连续信息,使模型更深入地学习到规范申报文本中的潜在格式规律,提高了模型的分类能力,从而更加容易地筛选出不规范文本。
技术特征:
1.一种用于海关进出口商品规范申报的智能化自动识别方法,其特征在于,具体包括:
2.根据权利要求1所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤1具体实现方式如下:
3.根据权利要求1或2所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤2具体实现方式如下:
4.根据权利要求1或2所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤3具体实现方式如下:
5.根据权利要求3所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤3具体实现方式如下:
6.根据权利要求1或2或5所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤4具体实现方式如下:
7.根据权利要求3所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤4具体实现方式如下:
8.根据权利要求4所述一种海关进出口商品规范申报的智能化自动识别方法,其特征在于,所述步骤4具体实现方式如下:
技术总结
本发明涉及一种用于海关进出口商品规范申报的智能化自动识别方法,属于自然语言处理技术领域。本发明针对BERT模型中存在的表达退化的问题,创新地提出了GDB模型。通过联合词嵌入生成器和词嵌入判别器,对流形外空间进行正则化,缓解了预训练模型BERT中存在的表达退化的问题。联合卷积神经网络进一步提取文本特征,捕捉文本中的局部连续信息,使模型更深入地学习到规范申报文本中的潜在格式规律,提高了模型的分类能力,从而更加容易地筛选出不规范文本。
技术研发人员:张强,周成杰,车超,冯闯,赵天明
受保护的技术使用者:大连理工大学
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!