基于张量分解的三层加权聚类集成方法
本发明涉及聚类,特别涉及基于张量分解的三层加权聚类集成方法及系统。
背景技术:
1、聚类分析是机器学习领域备受关注的研究热点之一,广泛应用于数据压缩、信息检索、图像分割和文本聚类等领域,同时在生物学、地质学、地理学以及异常数据检测等多领域也受到了越来越多的关注。它属于无监督机器学习范畴,通常不依赖数据集的先验知识,依赖于数据点、样本或对象之间的相似性度量,将数据集自动分成不同的组或簇,致力于使同一簇内的点之间的相似度尽可能高,而不同簇内的点的相似度尽可能低。
2、聚类集成是将集成学习的思想引入聚类分析领域,它开创了聚类集成的研究。该过程通常包含两个主要步骤。首先,对数据集进行多次聚类运算,产生多个不同的聚类结果,这一步骤被称为聚类成员生成。然后,将所有聚类成员组合成一个集合,被称为聚类集体,对它们进行合并,以产生最终的聚类结果。这个步骤被称为聚类集成,也叫做共识函数设计。聚类集成的优势在于能够通过组合多个不同的聚类结果来获得更优秀的最终结果,相较于传统聚类方法,它具有众多独特的优势,包括聚类结果的集成重用、处理具有分类属性的数据集、噪音和孤立点的检测和处理,以及适用于并行处理和分布式数据源等。正因如此,聚类集成迅速发展成为传统聚类方法的重要扩展,吸引了国内外众多学者。为了提升聚类集成的准确性,研究者们提出了很多方法,比如聚类成员选择及加权聚类集成。
3、申请号为cn202310891062.5的发明专利公开了一种基于自适应聚类和困难样本加权的无监督车辆再辨识方法,其中,方法包括:首先,利用当前聚类参数计算最合适的半径值,提升聚类伪标签对车辆样本噪声的鲁棒性;其次,记忆模块记录所有车辆样本特征向量,利用距离作为车辆样本困难程度加权依据,改善模型对困难车辆样本关注力不足的问题;最后,利用加权困难车辆样本结合对比学习方法训练车辆再辨识模型。上述发明可广泛应用于智慧交通和智慧安防中的智能视频监控系统。
4、但是上述现有技术的加权值的确定及聚类集成的好坏很大程度上受聚类成员的影响,加权值不准确及聚类集成不适宜时,聚类不够精准。
5、有鉴于此,亟需基于张量分解的三层加权聚类集成方法及系统,以至少解决上述不足。
技术实现思路
1、本发明目的之一在于提供了基于张量分解的三层加权聚类集成方法,引入预设的聚类算法,生成聚类成员,并基于聚类成员,构建超图邻接矩阵,然后再对点、簇及划分三层分别进行分析并赋相应权值,三层加权超图邻接矩阵转为三层加权共协矩阵,将相干链接矩阵和三层加权共协矩阵叠为三维张量,从全局角度捕捉数据的多样性,进一步提升聚类的准确性。
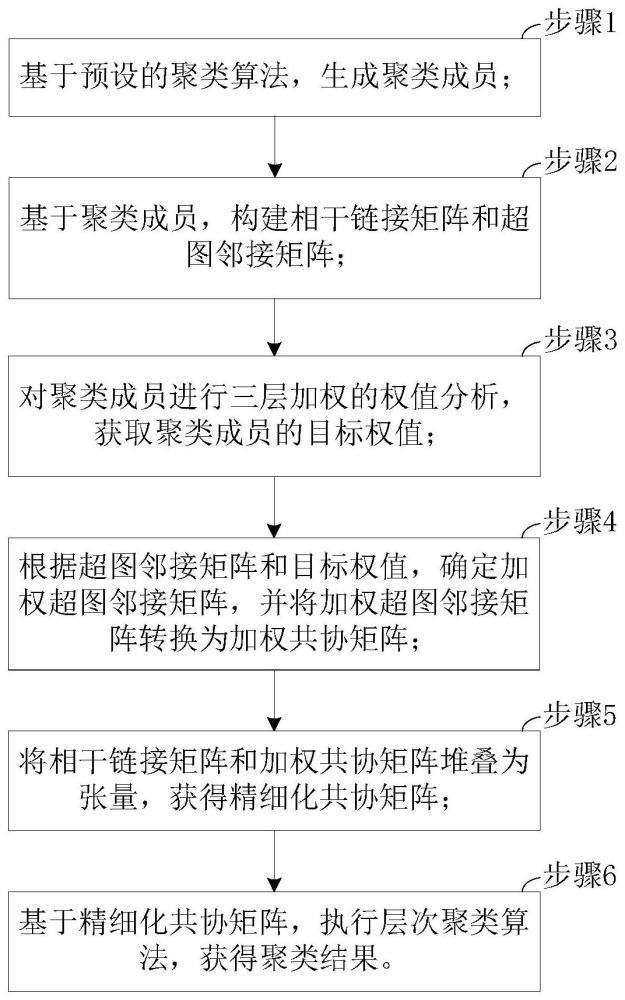
2、本发明实施例提供的基于张量分解的三层加权聚类集成方法,包括:
3、步骤1:基于预设的聚类算法,生成聚类成员;
4、步骤2:基于聚类成员,构建相干链接矩阵和超图邻接矩阵;
5、步骤3:对聚类成员进行三层加权的权值分析,获取聚类成员的目标权值;
6、步骤4:根据超图邻接矩阵和目标权值,确定加权超图邻接矩阵,并将加权超图邻接矩阵转换为加权共协矩阵;
7、步骤5:将相干链接矩阵和加权共协矩阵堆叠为张量,获得精细化共协矩阵;
8、步骤6:基于精细化共协矩阵,执行层次聚类算法,获得聚类结果。
9、优选的,步骤1:基于预设的聚类算法,生成聚类成员,包括:
10、获取数据样本点;
11、获取聚类成员的成员数目;
12、获取每个聚类成员的簇数目;
13、根据成员数目、簇数目和数据样本点,运行预设的聚类算法进行随机生成,获得聚类成员,预设的聚类算法包括:k-means聚类算法、层次聚类算法和谱聚类算法中的一种或多种。
14、优选的,步骤3:对聚类成员进行三层加权的权值分析,获取聚类成员的目标权值,包括:
15、获取聚类成员中的数据样本点的第一权值,第一权值的计算公式如下:
16、
17、其中,wi为第i个数据样本点的第一权值,aij为第i个数据样本点的共协矩阵的元素值,i表示矩阵的第i行,j表示矩阵的第j列,n为数据样本点的个数;
18、获取聚类成员中的簇的第二权值,第二权值的计算公式如下:
19、
20、
21、
22、其中,eci(ci)表示第i个簇的第二权值,ci表示第i个簇,表示第m个聚类成员中的第j个簇,hm(ci)表示聚类成员πm中第i个簇的信息熵,nm为第m个聚类成员中的簇的总个数,为衡量与ci之间的不确定性的函数,hπ(ci)表示聚类集体π中簇ci相对于整体π的信息熵,m是集成规模,θ是超参数;
23、获取聚类成员的第三权值,第三权值的计算公式如下:
24、
25、其中,为第m个聚类成员中的第s个簇,km是第m个聚类成员中的簇的总个数,nmi(πm,πq)表示第m个聚类成员和第q个聚类成员的相似度;
26、将第一权值、第二权值和第三权值共同作为目标权值。
27、优选的,步骤4:根据超图邻接矩阵和目标权值,确定加权超图邻接矩阵,并将加权超图邻接矩阵转换为加权共协矩阵,包括:
28、获取集成规模;
29、根据集成规模和加权超图邻接矩阵,确定加权共协矩阵,加权共协矩阵的转换模型如下:
30、
31、其中,wca是加权共协矩阵,h是加权超图邻接矩阵,t是矩阵转置运算符,m是集成规模。
32、本发明实施例提供的基于张量分解的三层加权聚类集成方法,还包括:
33、在根据集成规模和加权超图邻接矩阵确定加权共协矩阵之前,进行加权共协矩阵构建必要性分析,若必要,则进行相应构建;
34、进行加权共协矩阵构建必要性分析,包括:
35、计算基于加权超图邻接矩阵确定加权共协矩阵所需的第一复杂度;
36、计算基于加权超图邻接矩阵运行预设的目标算法的第二复杂度;
37、若第一复杂度和第二复杂度的复杂度差值大于等于预设的复杂度阈值且第一复杂度大于第二复杂度,则加权共协矩阵构建必要性分析结果为不必要,基于加权超图邻接矩阵和预设的目标算法,确定聚类结果;
38、若第一复杂度和第二复杂度的复杂度差值大于等于预设的复杂度阈值且第一复杂度小于第二复杂度,则加权共协矩阵构建必要性分析结果为必要;
39、若复杂度差值小于预设的复杂度阈值,则加权共协矩阵构建必要性分析结果为必要。
40、优选的,步骤5:将相干链接矩阵和加权共协矩阵堆叠为张量,获得精细化共协矩阵,包括:
41、获取相干链接矩阵的第一维度和加权共协矩阵的第二维度;
42、根据第一维度和第二维度,创建目标张量;
43、将相干链接矩阵复制到目标张量的第一个通道,同时,将加权共协矩阵复制到目标张量的第二个通道;
44、复制完成后,将对应目标张量作为精细化共协矩阵。
45、本发明实施例提供的基于张量分解的三层加权聚类集成方法,还包括:
46、步骤7:对聚类结果进行有效性分析,获取分析结果,并根据分析结果,评估聚类结果的质量;
47、对聚类结果进行有效性分析,获取分析结果,包括:
48、确定聚类结果的有效性分析指标的指标类型,指标类型包括:f值、nm i值、ari、nmi、ch和dunn中的一种或多种;
49、获取聚类算法的第一算法种类集,同时,获取聚类成员中的数据样本点的第一数据特征集;
50、基于历史评价记录,确定指标类型对应预设的第二算法种类集和第二数据特征集;
51、若第二算法种类集包含第一算法种类集且第二数据特征集包含第一数据特征集,将对应指标类型的有效性分析指标作为目标分析指标;
52、根据目标分析指标,确定分析结果;
53、根据分析结果,评估聚类结果的质量,包括:
54、根据分析结果,对比不同加权类型的对照聚类结果的聚类效果,获得对比结果,加权类型包括:点加权、簇加权、划分加权、点-簇加权、点-划分加权、簇-划分加权和点-簇-划分三层加权;
55、根据对比结果,确定聚类结果的质量。
56、优选的,获取数据样本点,包括:
57、获取人工输入的样本点获取需求,并提取样本点获取需求的第一样本点需求特征;
58、访问多个第一目标数据库;
59、每次访问时,获取正在访问的第一目标数据库的数据库内容,并提取数据库内容的第一内容特征,内容特征包括:数据类型和数据生成时间;
60、将第一样本点需求特征和第一内容特征进行匹配,若匹配符合,将对应第一样本点需求特征作为第二样本点需求特征,将对应第一内容特征作为第二内容特征;
61、计算第二样本点需求特征和第一样本点需求特征的特征数目比值,并与对应第一目标数据库关联;
62、基于预设的内容特征-访问成本值库,确定每一第二内容特征的访问成本值,累加访问成本值,获得访问成本值和,并与对应第一目标数据库关联;
63、若第一目标数据库关联的特征数目比值大于等于预设的比值门限,且,第一目标数据库关联的访问成本值和小于等于预设的成本值门限,则将对应第一目标数据库作为第二目标数据库;
64、向第二目标数据库发送数据样本点获取请求,获得数据样本点。
65、本发明实施例提供的基于张量分解的三层加权聚类集成系统,包括:
66、聚类成员生成子系统,用于基于预设的聚类算法,生成聚类成员;
67、矩阵构建子系统,用于基于聚类成员,构建相干链接矩阵和超图邻接矩阵;
68、目标权值获取子系统,用于对聚类成员进行三层加权的权值分析,获取聚类成员的目标权值;
69、权值融合子系统,用于根据超图邻接矩阵和目标权值,确定加权超图邻接矩阵,并将加权超图邻接矩阵转换为加权共协矩阵;
70、精细化共协矩阵获取子系统,用于将相干链接矩阵和加权共协矩阵堆叠为张量,获得精细化共协矩阵;
71、聚类结果确定子系统,用于基于精细化共协矩阵,执行层次聚类算法,获得聚类结果。
72、优选的,权值融合子系统,包括:
73、规模获取模块,用于获取集成规模;
74、加权共协矩阵确定模块,用于根据集成规模和加权超图邻接矩阵,确定加权共协矩阵,加权共协矩阵的转换模型如下:
75、
76、其中,wca是加权共协矩阵,h是加权超图邻接矩阵,t是矩阵转置运算符,m是集成规模;
77、基于张量分解的三层加权聚类集成系统,还包括:
78、加权共协矩阵构建必要性分析模块,用于在根据集成规模和加权超图邻接矩阵确定加权共协矩阵之前,进行加权共协矩阵构建必要性分析,若必要,则进行相应构建;
79、加权共协矩阵构建必要性分析模块,包括:
80、第一复杂度计算子模块,用于计算基于加权超图邻接矩阵确定加权共协矩阵所需的第一复杂度;
81、第二复杂度计算子模块,用于计算基于加权超图邻接矩阵运行预设的目标算法的第二复杂度;
82、第一分析子模块,用于若第一复杂度和第二复杂度的复杂度差值大于等于预设的复杂度阈值且第一复杂度大于第二复杂度,则加权共协矩阵构建必要性分析结果为不必要,基于加权超图邻接矩阵和预设的目标算法,确定聚类结果;
83、第二分析子模块,用于若第一复杂度和第二复杂度的复杂度差值大于等于预设的复杂度阈值且第一复杂度小于第二复杂度,则加权共协矩阵构建必要性分析结果为必要;
84、第三分析子模块,用于若复杂度差值小于预设的复杂度阈值,则加权共协矩阵构建必要性分析结果为必要。
85、本发明的有益效果为:
86、本发明引入预设的聚类算法,生成聚类成员,并基于聚类成员,构建超图邻接矩阵,然后再对点、簇及划分三层分别进行分析并赋相应权值,三层加权超图邻接矩阵转为三层加权共协矩阵,将相干链接矩阵和三层加权共协矩阵叠为三维张量,从全局角度捕捉数据的多样性,进一步提升聚类的准确性。
87、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过本技术文件中所特别指出的结构来实现和获得。
88、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!