一种可驱动数字人建模方法、装置、设备及介质与流程
本发明属于计算机视觉与计算机图形学领域,具体涉及一种可驱动数字人建模方法、装置、设备及介质。
背景技术:
1、可驱动数字人建模是计算机图形学和计算机视觉领域的重点问题。高质量的可驱动数字人在影视娱乐、虚拟现实等领域有着广泛的应用前景和重要的应用价值。但是高质量、高拟真度的可驱动数字人获取通常依靠价格昂贵的激光扫描仪或者多相机阵列系统对人体建模来实现,虽然效果较为真实,但是也显著存在着一些缺点:第一,设备复杂,这些方法往往需要多相机阵列的搭建;第二,速度慢,这些方法往往创建一个数字人需要花费数个月的时间;第三,这些方法需要美工等专家的手动介入,自动化不够。因此,亟需一种可方便快捷、自动化地建模可驱动的数字人的方法。
技术实现思路
1、为了克服现有技术存在的问题,本发明提供一种可驱动数字人建模方法、装置、设备及介质,用于克服目前存在的缺陷。
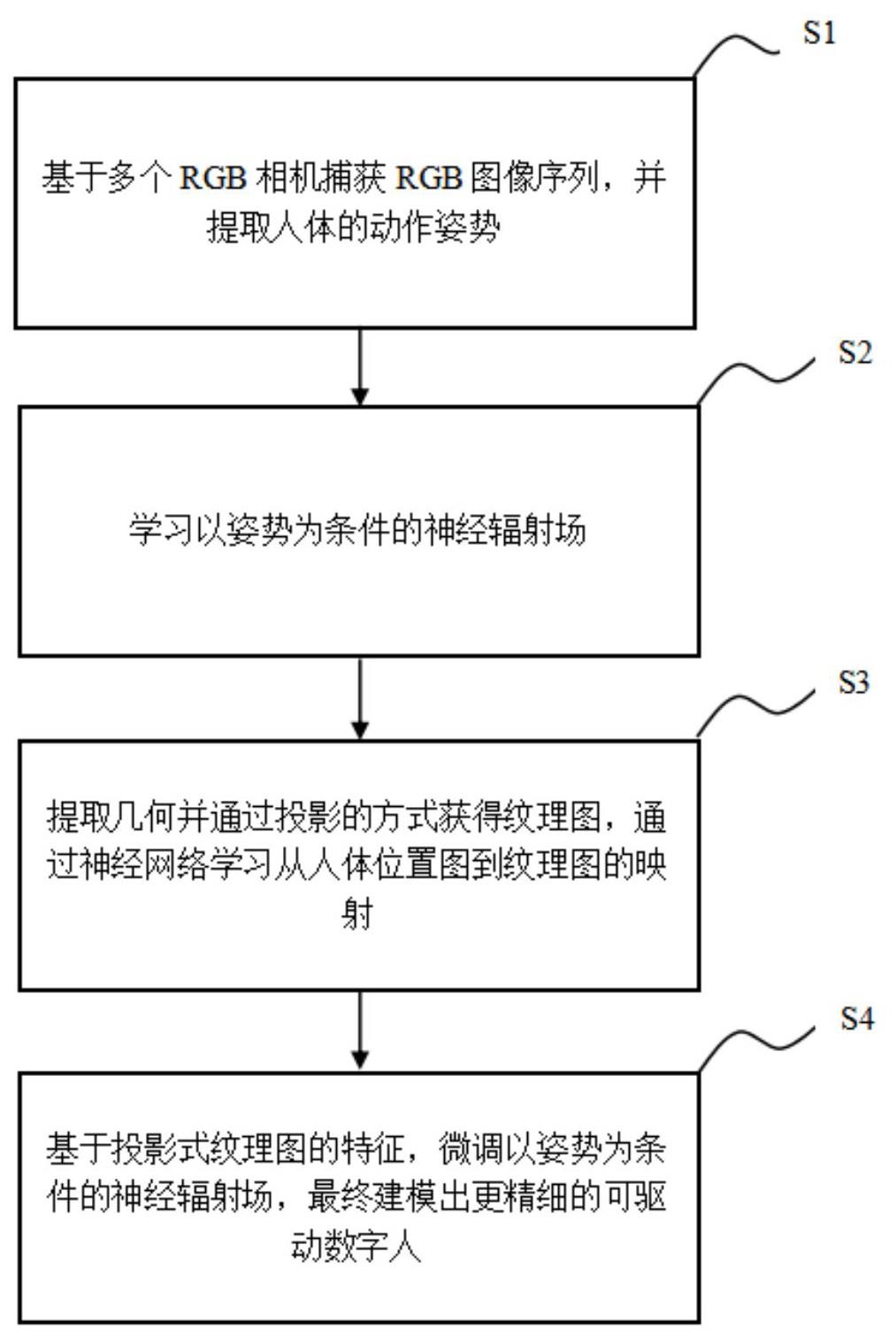
2、一种可驱动数字人建模方法,包括以下步骤:
3、s1.拍摄获取人体表演不同动作的视频,并提取人体的动作姿势;
4、s2.学习以所述动作姿势为条件的神经辐射场;
5、s3.从所述神经辐射场提取纹理图,并通过神经网络学习从人体位置图到纹理图的映射;
6、s4.提取映射后的纹理图的特征,并微调以动作姿势为条件的神经辐射场,从而建模出可驱动的数字人。
7、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,s1具体包括采用多个rgb相机对单个人体拍摄rgb图像序列,得到图像集,并提取人体的动作姿势。
8、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述步骤s2具体包括:通过反向蒙皮将所述动作姿势的空间中任一三维点变形至标准空间,得到对应的三维点,通过神经网络学习标准空间下所述动作姿势到人体动态外观的映射,即
9、,
10、其中是由多层感知器mlp参数化的映射函数,是rgb颜色值,是符号距离函数值,通过
11、,
12、将符号距离函数值转化为体积密度值,和构成神经辐射场,为可优化的系数。
13、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,对所述神经辐射场进行体渲染获得渲染图像,和拍摄得到的真实图像构建损失函数,所述损失函数用于优化所述神经网络。
14、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述s3具体包括:从所述图像集中提取标准空间下的三维几何模型,并将其经过前项蒙皮后投影到每个视点,获得顶点颜色,并将所述三维几何模型通过正交投影投射到正反视角,获得标准姿势下的位置图以及纹理图,其中位置图每个像素值为姿势空间下的坐标,即与人体姿势参数相关;建立位置图到纹理图的映射,即
15、,
16、其中, 为二维卷积层以及池化层参数化的映射函数。
17、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,采用映射的纹理图优化映射函数,从而用于优化所述神经辐射场。
18、如上所述的方面和任一可能的实现方式,进一步提供一种实现方式,所述s4具体包括:从所述映射出的纹理图中提取特征向量,并将其通过采用另一个多层感知器mlp进行处理得到纹理特征,加在映射函数的中间层特征上,并通过最小化渲染图像和真实图像之间的损失,微调以获得更加精细的数字人。
19、本发明还提供了一种可驱动数字人建模的装置,所述装置用于实现所述的方法,所述装置包括:
20、拍摄模块,用于拍摄获取人体表演不同动作的视频,并提取人体的动作姿势;
21、学习模块,用于学习以所述动作姿势为条件的神经辐射场;
22、提取映射模块,用于从所述神经辐射场提取纹理图,并通过神经网络学习从人体位置图到纹理图的映射;
23、建模模块,用于提取映射后的纹理图的特征,并微调以姿势为条件的神经辐射场,从而建模出可驱动的数字人。
24、本发明还提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现所述的方法。
25、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现如上述所述的方法。
26、本发明的有益效果
27、与现有技术相比,本发明有如下有益效果:
28、本发明的可驱动数字人建模方法,包括以下步骤:首先,使用多相机系统拍摄人体表演不同动作的视频,并提取人体的动作姿势;然后学习以姿势为条件的神经辐射场;根据从神经辐射场提取的几何特征获得纹理图,并通过神经网络学习从人体位置图到纹理图的映射;提取投影式纹理图的特征,并微调以姿势为条件的神经辐射场,从而建模出更精细的可驱动数字人。本发明的方法相较于其他可驱动数字人建模的方法,能够生成更真实、动态的渲染结果,以用于全息通信、虚拟偶像、线上直播等应用场景。
技术特征:
1.一种可驱动数字人建模方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的可驱动数字人建模方法,其特征在于,s1具体包括采用多个rgb相机对单个人体拍摄rgb图像序列,得到图像集,并提取人体的动作姿势。
3.根据权利要求2所述的可驱动数字人建模方法,其特征在于,所述步骤s2具体包括:通过反向蒙皮将所述动作姿势的空间中任一三维点变形至标准空间,得到对应的三维点,通过神经网络学习标准空间下所述动作姿势到人体动态外观的映射,即
4.根据权利要求3所述的可驱动数字人建模方法,其特征在于,对所述神经辐射场进行体渲染获得渲染图像,和拍摄得到的真实图像构建损失函数,所述损失函数用于优化所述神经网络。
5.根据权利要求4所述的可驱动数字人建模方法,其特征在于,所述s3具体包括:从所述图像集中提取标准空间下的三维几何模型,并将其经过前项蒙皮后投影到每个视点,获得顶点颜色,并将所述三维几何模型通过正交投影投射到正反视角,获得标准姿势下的位置图以及纹理图,其中位置图每个像素值为姿势空间下的坐标,即与人体动作姿势参数相关;建立位置图到纹理图的映射,即
6.根据权利要求5所述的可驱动数字人建模方法,其特征在于,采用映射的纹理图优化映射函数,从而用于优化所述神经辐射场。
7.根据权利要求5所述的可驱动数字人建模方法,其特征在于,所述s4具体包括:从所述映射出的纹理图中提取特征向量,并将其通过采用另一个多层感知器mlp进行处理得到纹理特征,加在映射函数的中间层特征上,并通过最小化渲染图像和真实图像之间的损失,微调以获得更加精细的数字人。
8.一种可驱动数字人建模的装置,所述装置用于实现权利要求1-7任一项所述的方法,其特征在于,所述装置包括:
9.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现如权利要求1至7任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现如上述权利要求1至7任一项所述的方法。
技术总结
本发明涉及一种可驱动数字人建模方法、装置、设备及介质,包括以下步骤:首先,使用多相机系统拍摄人体表演不同动作的视频,并提取人体的动作姿势;然后学习以姿势为条件的神经辐射场;从神经辐射场提取的几何获得纹理图,并通过神经网络学习从人体位置图到纹理图的映射;提取映射的纹理图的特征,并微调以姿势为条件的神经辐射场,从而建模出更精细的可驱动数字人。本发明的方法相较于其他可驱动数字人建模的方法,能够生成更真实、动态的渲染结果。不仅如此,由于该方法为更为快速方便,可以为用户提供良好的交互式三维重建体验,拥有广阔的应用前景。
技术研发人员:邱见明,赵洁,李哲,陈华荣
受保护的技术使用者:杭州新畅元科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!