一种层次多标签场景的联邦学习方法与流程
本发明涉及联邦学习,特别是一种层次多标签场景的联邦学习方法。
背景技术:
1、在互联网时代,数据已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。由于海量的数据往往分散存储在组织的各个企业、部门或业务系统之中,各数据拥有者需要通力合作以达到更好的信息挖掘和运用效果。另一方面,出于对数据价值的保护和对隐私泄露的担忧,数据拥有者往往不愿意将数据直接转交给他人进行处理。
2、联邦学习是一类机器学习方法,其利用深度学习模型不可解释的特性,用模型参数、激活值或梯度传输代替原始数据交互。联邦学习可以在原始数据不出域的前提下实现合作方的共同建模,一定程度达到了数据隐私和学习效果的平衡。在现有的联邦学习实现方案之中,当合作方所掌握的数据维度有差异时,需要在合作方之间进行样本对齐,通过共享各方数据id的交集,确定交集的训练批次和位置,进行模型训练和参数优化。
3、然而,样本对齐方案在由层次多标签训练场景中仍存在如下问题:层次多标签场景中,各合作方对数据的细分方法有差异,数据被分类为不同粒度的多个标签,且这些标签呈递进的层次结构。在该场景中,低层次标签和高层次标签有相关性,甚至可能有因果性,样本对齐方案共享数据id的交集,拥有高层次标签的合作方可以通过标签间的相关性推导出交集中的低层次标签,导致拥有低层次标签的合作方在交集中的标签信息被泄露。
技术实现思路
1、本发明的目的在于提供一种在层次多标签场景下能够保证低层级样本标签的合作方的数据隐私的联邦学习方法,以提升联邦学习在层次多标签场景下的安全可用性。
2、本发明所述的层次多标签场景的联邦学习方法,包括以下步骤:
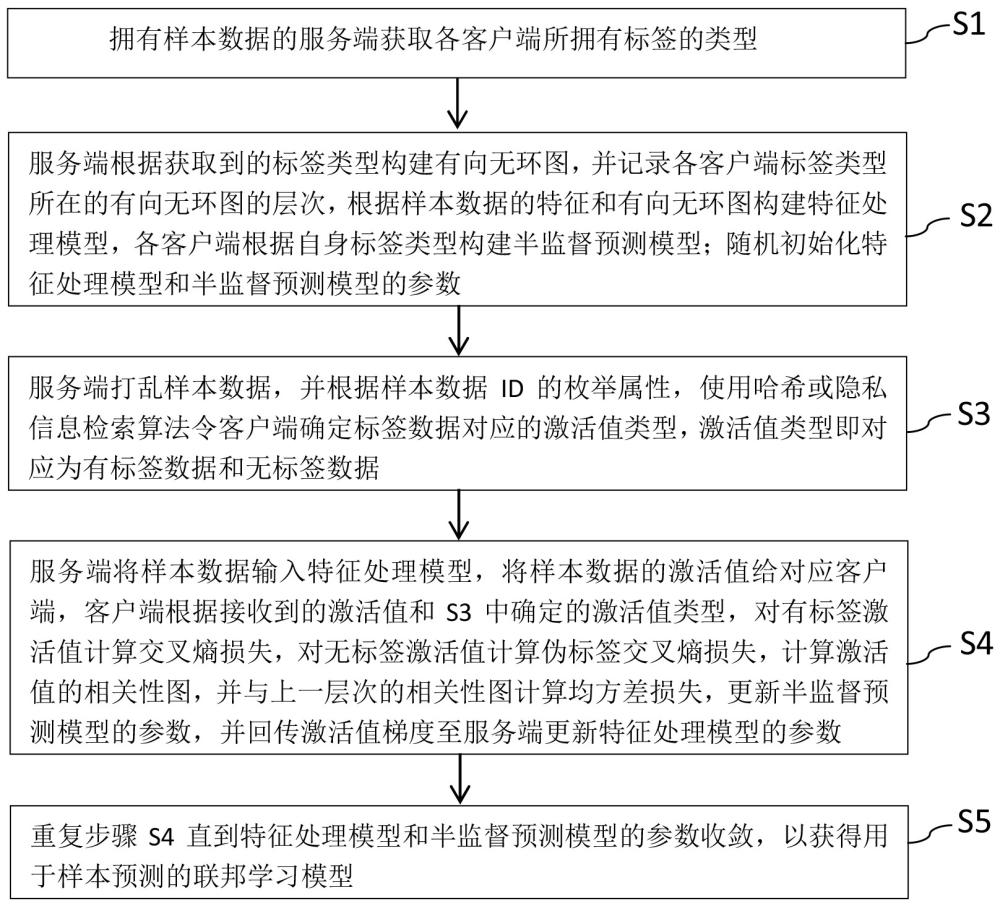
3、s1、拥有样本数据的服务端获取各客户端所拥有标签的类型;
4、s2、服务端根据获取到的标签类型构建有向无环图,并记录各客户端标签类型所在的有向无环图的层次,根据样本数据的特征和有向无环图构建特征处理模型,各客户端根据自身标签类型构建半监督预测模型;随机初始化特征处理模型和半监督预测模型的参数;
5、s3、服务端打乱样本数据,并根据样本数据id的枚举属性,使用哈希或隐私信息检索算法令客户端确定标签数据对应的激活值类型,激活值类型即对应为有标签数据和无标签数据;
6、s4、服务端将样本数据输入特征处理模型,将样本数据的激活值给对应客户端,客户端根据接收到的激活值和s3中确定的激活值类型,对有标签激活值计算交叉熵损失,对无标签激活值计算伪标签交叉熵损失,计算激活值的相关性图,并与上一层次的相关性图计算均方差损失,更新半监督预测模型的参数,并回传激活值梯度至服务端更新特征处理模型的参数;
7、s5、重复步骤s4直到特征处理模型和半监督预测模型的参数收敛,以获得用于样本预测的联邦学习模型。
8、本发明所述的层次多标签场景的联邦学习方法,在层次多标签场景下,由于层次多标签采用了向无环图结构表示,因此在构建特征处理模型时,通过获取到的标签类型构建有向无环图,并记录各客户端标签类型所在的有向无环图的层次,根据样本数据的特征和有向无环图来构建特征处理模型,其特征处理模型可获取不同层次的激活值,且各客户端可以通过自身所在层次获得对应层次的激活值,从而能够支撑后续有标签和无标签数据的计算流程;然后通过计算无标签激活值的伪标签交叉熵损失,保证训练数据中有标签和无标签数据均有梯度回传,从而保护数据隐私,另外,通过计算相邻层次之间的相关性图的均方差损失,低层次客户端得以指导高层次客户端的参数优化,达到联邦学习的效果,从而提升了联邦学习在层次多标签场景下的安全可用性。
9、作为本发明的一种优选方案,所述有向无环图为分类多标签序列,分类多标签为对样本按照不同层级、不同粒度或不同细分方法进行分类的样本的多个标签。
10、作为本发明的一种优选方案,所述样本数据包括语音、文本、图像和其他人工定义特征数据。
11、作为本发明的一种优选方案,服务端根据样本数据的特征和有向无环图构建特征处理模型具体包括:
12、服务端根据样本数据的特征选择全连接网络、卷积神经网络或循环神经网络不同的嵌入形式构建特征嵌入层;
13、将构建特征嵌入层依据有向无环图的最大深度的残差多层感知机构建特征嵌入层的层数,最终构建出特征处理模型。
14、作为本发明的一种优选方案,样本数据id的枚举属性包括样本数据id不可枚举和可以枚举;
15、样本数据id不可枚举,服务端则使用哈希算法对不可枚举的样本数据id进行哈希处理,并将哈希处理后的标签数据对应的激活值发送至对应的客户端;
16、样本数据id可枚举,服务端则使用隐私信息检索算法对可枚举的样本数据id进行处理加密,客户端将加密后的id作为key向服务端进行查询,得到有标签数据对应自身的激活值。
技术特征:
1.一种层次多标签场景的联邦学习方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的层次多标签场景的联邦学习方法,其特征在于,所述有向无环图为分类多标签序列,分类多标签为对样本按照不同层级、不同粒度或不同细分方法进行分类的样本的多个标签。
3.根据权利要求1所述的层次多标签场景的联邦学习方法,其特征在于,所述样本数据包括语音、文本、图像和其他人工定义特征数据。
4.根据权利要求1所述的层次多标签场景的联邦学习方法,其特征在于,服务端根据样本数据的特征和有向无环图构建特征处理模型具体包括:
5.根据权利要求1所述的层次多标签场景的联邦学习方法,其特征在于,样本数据id的枚举属性包括样本数据id不可枚举和可以枚举;
技术总结
本发明公开的层次多标签场景的联邦学习方法,在层次多标签场景下通过获取到的标签类型构建有向无环图,并记录各客户端标签类型所在的有向无环图的层次,根据样本数据的特征和有向无环图来构建特征处理模型,其特征处理模型可获取不同层次的激活值,且各客户端可以通过自身所在层次获得对应层次的激活值,从而能够支撑后续的计算流程;然后通过计算无标签激活值的伪标签交叉熵损失,保证训练数据中有标签和无标签数据均有梯度回传,从而保护数据隐私,另外,通过计算相邻层次之间的相关性图的均方差损失,低层次客户端得以指导高层次客户端的参数优化,达到联邦学习的效果,从而提升了联邦学习在层次多标签场景下的安全可用性。
技术研发人员:叶宇中,刁则鸣,耿夏楠
受保护的技术使用者:国家计算机网络与信息安全管理中心广东分中心
技术研发日:
技术公布日:2024/2/19
- 还没有人留言评论。精彩留言会获得点赞!