基于深度正向投影和查询反投影的场景重构方法及驾驶辅助系统
本发明属于计算机图像处理技术,尤其涉及一种基于深度正向投影和查询反投影的场景重构方法及驾驶辅助系统。
背景技术:
1、在自动驾驶中,占据栅格是指监测和估计道路和交通场景中各种元素的使用情况,例如车道、停车位、行人等。占据栅格任务的目标是对于每个位置估计其被交通元素所占据的概率,可以用于自动驾驶中的路径规划和行为决策等模块,从而实现更安全、更高效的自动驾驶行驶。占据栅格任务通常使用图像语义分割技术,将输入的摄像头图像分割成多个语义类别,然后进一步推断每个像素点被哪些交通元素占据。随着深度学习技术的发展,占据栅格在自动驾驶系统中发挥着越来越重要的作用,已成为自动驾驶技术的核心组成部分之一。
2、在自动驾驶中,占据栅格预测任务与3d目标检测任务类似,都需要一个中间表征来表达整个场景,但是占据栅格需要稠密的输出,因此需要稠密的中间表征。常见的稠密中间表征包含鸟瞰图空间与体素空间,两种中间表征的主要区别为表征是否具有高度维度,鸟瞰图空间将高度维度压缩,没有高度信息,而体素空间保留了高度信息。
3、专利文献cn116012376 b公开了一种目标检测方法、装置以及车辆,方法包括:获取车辆周围环境的各环视图像,采用卷积神经网络提取各环视图像对应的图像特征图和深度概率特征图;根据各环视图像对应的深度概率特征图,确定各环视图像中各像素点对应的多个目标深度类别的目标深度值和目标深度概率值;根据各环视图像中各像素点对应的多个目标深度类别的目标深度值和目标深度概率值、以及各环视图像对应的图像特征图,获得车辆周围环境对应的鸟瞰图特征图;根据对应的鸟瞰图特征图,经过卷积神经网络前向运算得到网络输出特征结果,并对网络输出特征结果进行特征解码,获得对车辆周围环境中的目标的检测结果。
4、学术文献bevformer:learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers[c]//european conference oncomputer vision(eccv).2022公开了根据鸟瞰图空间或体素空间中间表征对应的3d参考点投影回到多视角图像中,根据投影点进行局部特征提取,再利用注意力机制将图像特征聚合到查询这一中间表征中,拼接所有查询得到稠密的中间表征。
5、而现有技术尚未对这两种范式进行系统性的分析,也缺乏对两种方式融合的探索。
技术实现思路
1、本发明的目的在于提供一种基于深度正向投影和查询反投影的场景重构方法及驾驶辅助系统,该方法能够获取完善准确的场景三维表征,为后续场景重建和辅助驾驶提供有效指导。
2、为了实现本发明的第一个目的,提供了一种基于深度正向投影和查询反投影的场景重构方法,包括以下步骤:
3、获取视频数据,其包括逐帧排列的环视图像和对应的相机内外参数;
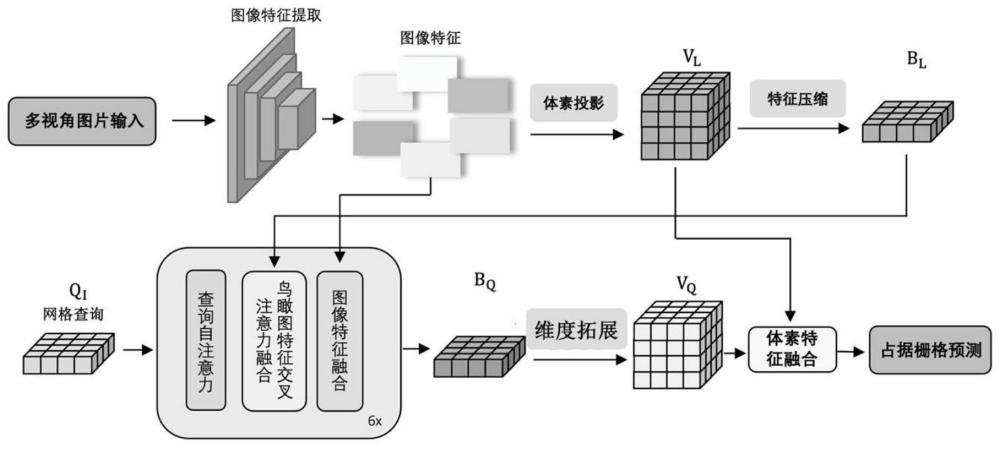
4、对所述环视图像进行特征提取,以获得对应的第一特征图;
5、将获得的第一特征图和对应的相机内外参数输入至预构建的深度预测网络,所述深度预测网络包括特征提取模块和深度预测模块,所述特征提取模块用于提取输入的第一特征图的上下文特征,所述深度预测模块根据输入的相机内外参数和第一特征图进行预测,以输出与所述第一特征图尺度一致的深度值图;
6、将预构建的三维空间划分为多个体素,并基于所述深度值图将所述上下文特征投影至三维空间中各体素内进行池化操作,以生成体素对应的第一特征向量;
7、将所述第一特征向量沿高度维度进行堆叠,以构建三维空间对应的中间表征,并将所述中间表征和所述第一特征图,以及输入的待查询网格进行交叉注意力处理,经迭代后获得增强中间表征;
8、将所述增强中间表征沿高度维度进行拆分并利用卷积扩充高度维度,以构建三维空间中体素的第二特征向量;
9、将所述第一特征向量和所述第二特征向量进行拼接融合,以获得第三特征向量,并基于所述第三特征向量对三维空间的空间占据栅格进行预测,以获得待查询网格范围内每个空间占据栅格的预测信息。
10、本发明基于深度引导的正向投影方式能够学习整个场景的结构信息,同时利用查询反投影方式能够学习特定空间3d坐标到图像空间2d坐标的转换,从而将场景中间表征融合,以获取更完善准确的场景三维表征。
11、具体的,通过骨干网络对环视图像进行图像特征提取,以获得对应的第一特征图,所述第一特征图包含特征图和特征图对应的长度,宽度以及通道数。
12、具体的,所述骨干网络采用resnet50。
13、具体的,所述相机内外参数包括相机内的投影矩阵以及相对于世界坐标系的单应性变换矩阵。
14、具体的,所述交叉注意力处理包括查询自注意力,中间表征交叉注意力以及图像特征交叉注意力;
15、所述查询自注意力用于输入的待查询网格中各体素间特征向量的交互;
16、所述中间表征交叉注意力用于将中间表征的特征向量与待查询网格中各体素特征向量进行交互,以获得带有三维空间结构信息的待查询网格;
17、图像特征交叉注意力采用反向查询的方式将中间表征中的每个位置映射回对应的第一特征图中,并利用可变形注意力机制获取映射点与相邻点的二维局部特征并进行聚合,将聚合获得的特征向量与待查询网格中各体素特征向量进行交互,以获得带有融合特征信息的待查询网格。
18、具体的,所述中间表征交叉注意力的输出表达式如下:
19、
20、其中,表示根据坐标p在中进行双线性插值采样,k表示总共k个采样点的下标,表示第k个采样点的注意力权重kth,满足表示带有三维空间结构信息的待查询网格,bl表示中间表征,表示待查询网格的坐标,表示待查询网格输入至偏移预测网络后的相对坐标。
21、具体的,所述图像特征交叉注意力输出表达式如下:
22、
23、其中,m表示相机内外参数,表示根据坐标p在中进行双线性插值采样,表示第k个采样点的注意力权重kth,表示带有三维空间结构信息的待查询网格,表示带有融合特征信息的待查询网格,表示待查询网格在第一特征图的投影坐标输入至偏移预测网络后的相对坐标,表示中间表征映射点的三维坐标。
24、具体的,所述拼接融合的具体过程如下:
25、将第一特征向量和第二特征向量输进行特征拼接,并采用卷积操作对拼接结果进行融合,以获得对应的第三特向量。
26、为了实现本发明的第二目的,提供了一种驾驶辅助系统,通过上述的基于深度正向投影和查询反投影的场景重构方法实现,包括:
27、图像获取单元,通过车载相机获取车辆周围的视频数据;
28、图像分析单元,根据所述基于深度正向投影和查询反投影的场景重构方法对获取的视频图像进行数据处理,以生成车辆周围空间占据栅格的预测信息;
29、可视化单元,以自身车辆为中心进行三维空间构建,并将车辆周围空间占据栅格的预测信息引入所述三维空间中,以获得车辆周围的三维场景语义表征。
30、与现有技术相比,本发明的有益效果:
31、提出了一种融合框架,将深度引导的正向投影方式和查询反投影方式相结合,通过正向投影方式能够学习整个场景的结构信息,以及利用查询反投影方式将场景内的细节进行补充,从而提高三维信息表示的准确性。
- 还没有人留言评论。精彩留言会获得点赞!