一种基于“切片-排序”操作的序列分类方法
本发明涉及的是一种深度机器学习中自然语言处理领域的序列分类方法,具体是一种基于“切片-排序”操作的序列分类方法。
背景技术:
1、在自然语言处理领域中,序列分类(sequence classification),又称自动序列分类(automatic sequence categorization),是一个经典任务。这个任务是指计算机将载有信息的一段序列映射到预先给定的某一类别或某几类别主题的过程。这一任务的最初解决方案是专家规则(pattern),利用知识工程建立专家系统来进行分类,优点是较为直观且可解释性强,缺点是需要大量人力资源,且覆盖范围,准确率和泛化性都很难保证。后来伴随着统计机器学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模序列分类问题的方法,即特征工程+机器学习模型。其中机器学习模型又分为传统机器学习方法和深度学习文本分类方法。
2、近年来,基于多头注意力机制的transformer在序列分类领域中越来越占据主导地位。它作为许多基础模型的骨干模块,在各种应用场景中都取得了优异的性能。例如,自然语言处理领域的bert和gpt模型,计算机视觉领域的vit模型,用于时序建模的informer模型,用于图数据建模的graphormer模型等等。
3、多头注意力机制(multi-head attention)是深度学习中一种重要的注意力机制,被广泛应用于自然语言处理领域的transformer模型以及各种变体模型中。它的主要目标是在输入数据中找到不同位置的相关性,以便更好地捕捉上下文信息和建模序列之间的依赖关系。多头注意力机制包括以下主要组成部分:
4、自注意力头(self-attention heads):多头注意力允许模型学习多个不同的注意力权重集合,通常由若干个自注意力头组成。每个自注意力头都可以学习关注不同的输入部分,有助于捕获不同种类的关系。将多个自注意力头的结果拼接在一起就得到了多头注意力机制的输出。
5、查询(query)、键(key)和值(value):对于每个自注意力头,输入数据都会被线性映射成三个不同的表示:查询、键和值。这些表示将用于计算注意力权重和输出。
6、注意力权重计算:每个注意力头都会计算一个注意力权重分布,它决定了每个位置对于当前位置的重要性。这通常是通过计算查询和键之间的相似性得到的,然后将这些相似性标准化为概率分布。这些权重用于加权值以获得每个位置的输出。
7、多头汇总:多个注意力头的输出被拼接在一起,然后通过线性变换进行进一步处理,以产生最终的多头注意力机制的输出。
8、然而,虽然多头注意力机制有着优异的性能,但是仍存在着如下所示的问题:
9、(1)过平滑。多头注意力机制中使用softmax函数对注意力矩阵归一化,然而这会导致在长序列中出现过平滑问题。给定一个向量可以得到y=[yn]=softmax(x),其中yn是y的第n个元素。这些元素的标准差,即
10、
11、将会随着n的增大而快速减小。这相当于,y的所有元素的区分度将下降。
12、(2)高复杂度。多头注意力机制中涉及到矩阵乘法操作,其时间复杂度为空间复杂度为也就是时间和空间复杂度会随着输入序列长度的增长而以平方的速度增长。这使得多头注意力机制难以适用长序列输入。
13、为了解决这些问题,人们提出了许多transformer的变体。一些通过设计稀疏或低秩的注意力矩阵来提升多头注意力机制的性能,如“generating long sequences withsparse transformers”和“reformer:the efficient transformer”;还有一些通过最优传输重新设计注意力矩阵来提升多头注意力机制的可解释性,如“sinkformers:transformers with doubly stochastic attention”和“sparse sinkhorn attention”。
14、然而以上这些模型仍旧依赖经典的多头注意力机制中的“query-key-value”结构,不能从根本上解决问题。为此,本发明提出了一种新的“切片-排序”操作替代了这一结构。
技术实现思路
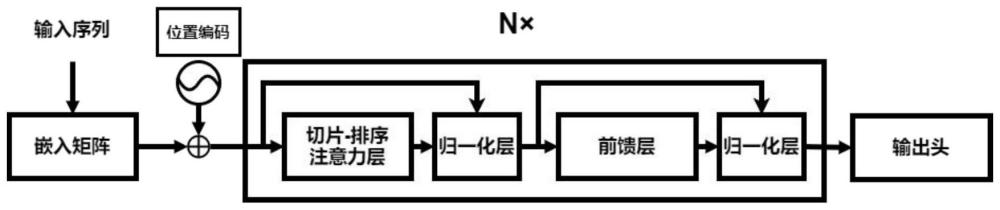
1、为此,本发明首先提出一种基于“切片-排序”操作的序列分类方法,首先输入一段由n个符号组成的文本序列,通过嵌入矩阵转变为被高效压缩且信息密集的表征,在这种表征中,相似的符号将具有相似的编码;经过嵌入矩阵后经过位置编码,利用类似transformer架构的模型,加入关于序列中符号的相对或绝对位置的信息;而后采用多个相同的包含“切片-排序”操作或“最大值交换”操作或“顺序交错”操作的注意力层的神经网络层,所述注意力层将输入线性的投影到隐空间中并且对每个特征维度排序;最后通过输出头结构,以一个全连接前馈层mlp(·),将输入的表征矩阵投影到输出维度上,得到对该文本的预测分类。
2、所述嵌入矩阵是可训练的参数,在不同大小的数据集中,嵌入矩阵的维数从8维到1024维之间变换。
3、所述位置编码的计算方式如下:
4、
5、
6、x:=x+pe
7、其中,pos是符号在序列中的位置,i为维度。
8、所述“切片-排序”注意力层的具体实现方式为:
9、
10、其中,是投影矩阵,同时v=xwv,将矩阵v的每一列称为切片,表示为vi,i=1,…,dv,每一个切片对应了1d空间中的n个维度为dmodel的样本的投影结果;同时,对一个切片vi进行排序对应于一个排序矩阵pi与该切片相乘;之后,“切片-排序”操作会将所有的排序后的切片拼接起来作为输出,即该操作的时间复杂度为空间复杂度一般为最坏情况为在得到注意力层的输出后,将其输入到一个全连接前馈层mlp(·)中,同时、对这两个层应用了残差链接和层归一化操作。
11、所述“最大值交换”操作为,对于每一个切片vi,找到它的最大值并将其与该切片第一个元素交换位置。
12、所述“顺序交错”操作以不同的顺序对矩阵v的列进行排序,同时在不同的神经网络层以不同的频率交错排序的顺序,假定sliceformer有n个基于“顺序交错”操作的注意力深层神经网络,为第n层第i列的切片,那么有其中,ψn(i)定义为
13、
14、所述输出头将输入的表征矩阵投影到输出维度上,得到预测分类,如下所示:
15、本发明所要实现的技术效果在于:
16、针对文本的处理,实现低时间和空间复杂度:给定一个矩阵“切片-排序”操作将对矩阵的n个切片进行排序操作,之后我们会将所有的排序后的切片拼接起来作为输出,即该操作的时间复杂度为空间复杂度一般为最坏情况为本发明的时间和空间复杂度都远远低于多头注意力机制。
17、隐式注意力矩阵:对于每个切片vi,i=1,...,dv,排序操作隐式地将注意力矩阵实现为排序矩阵pi。排序矩阵天然满足稀疏、满秩和双随机的性质,这将大大提升模型的学习能力。除此之外,“切片-排序”操作所隐式生成的注意力头的数量可能比传统多头注意力的多得多,这意味着更大的模型容量。
- 还没有人留言评论。精彩留言会获得点赞!