图像生成方法、模型训练方法及对应装置与流程
本技术涉及计算机视觉,特别是涉及一种图像生成方法、模型训练方法及对应装置。
背景技术:
1、人工智能技术的不断发展给计算机视觉技术提供了新的契机,其中自动生成图像的能力越来越强大。基于文本的图像生成技术为很多内容创作者提供了全新的工具,让原本需要专业人员和昂贵设备制作的图像内容创作变得更加容易和低成本。然而,目前大多数技术仅以文本作为引导条件,无法实现对生成图像的更精细化控制。
技术实现思路
1、有鉴于此,本技术提供了一种图像生成方法、模型训练方法及对应装置,以便于提高对生成图像的精细化控制能力。
2、本技术提供了如下方案:
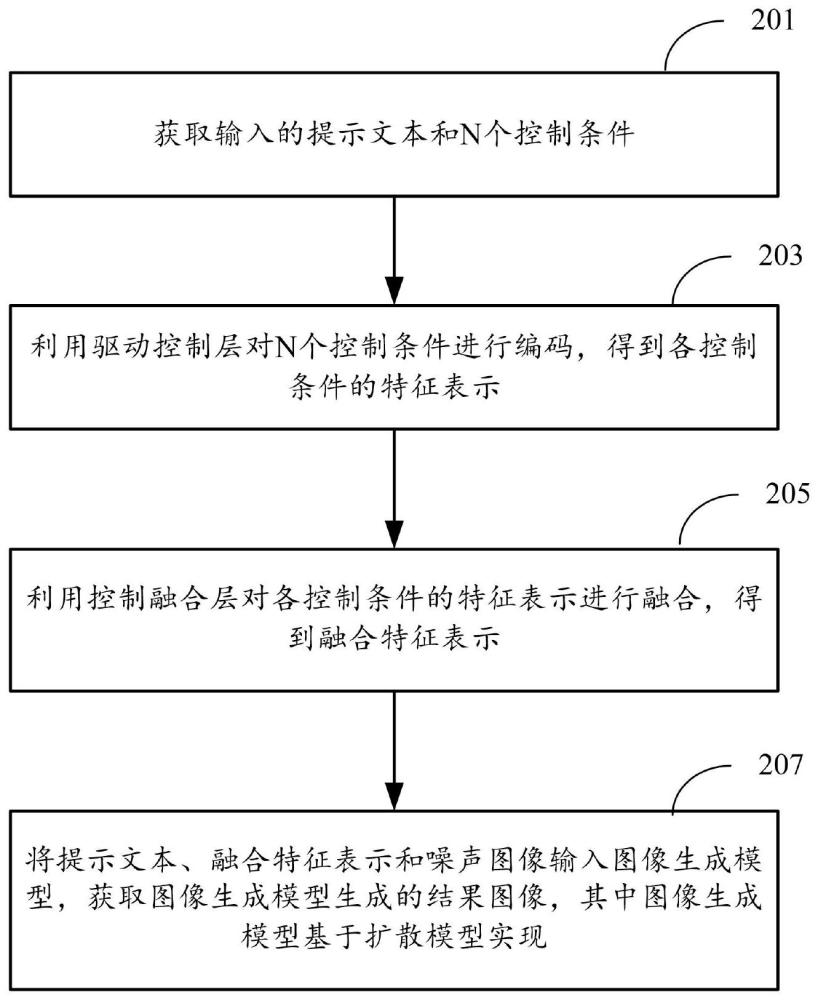
3、第一方面,提供了一种图像生成方法,所述方法包括:
4、获取输入的提示文本和n个控制条件,所述n为正整数;
5、利用驱动控制层对所述n个控制条件进行编码,得到各控制条件的特征表示;
6、利用控制融合层对所述各控制条件的特征表示进行融合,得到融合特征表示;
7、将所述提示文本、所述融合特征表示和噪声图像输入图像生成模型,获取所述图像生成模型生成的结果图像,其中所述图像生成模型基于扩散模型实现。
8、根据本技术实施例中一可实现的方式,所述驱动控制层包括n个条件编码器,各类型的控制条件分别对应有独立的条件编码器;
9、所述利用驱动控制层对所述n个控制条件进行编码包括:将所述n个控制条件分别输入对应的条件编码器进行编码。
10、根据本技术实施例中一可实现的方式,所述方法还包括:依据门控超参数,确定所述控制条件参与图像生成的时间步数量tth;
11、在将所述融合特征表示输入图像生成模型时,在所述前tth个时间步将所述融合特征表示输入所述图像生成模型中的去噪网络,以使所述去噪网络在前tth个时间步利用所述提示文本的特征表示和所述融合特征表示进行所述去噪声处理;在其余时间步不将所述融合特征表示输入所述去噪网络,以使所述去噪网络在其余时间步利用所述提示文本的特征表示进行所述去噪声处理。
12、根据本技术实施例中一可实现的方式,所述图像生成模型中的去噪网络包括至少m个尺度的隐层,所述m为正整数;
13、所述各控制条件的特征表示包括各控制条件对应的m个尺度的特征表示;
14、所述利用控制融合层对所述各控制条件的特征表示进行融合包括:分别对各控制条件对应的同一尺度的特征表示进行融合,得到m个尺度的融合特征表示;
15、在将所述融合特征表示输入图像生成模型时,将所述m个尺度的融合特征表示分别输入对应尺度的隐层;所述去噪网络中的各隐层分别将本隐层预测的隐向量与本隐层被输入的融合特征表示进行融合,将融合得到的隐向量输入下一隐层;
16、其中,所述隐层包括编码器隐层和/或解码器隐层。
17、第二方面,提供了一种图像生成方法,由云端服务器执行,所述方法包括:
18、向用户终端发送服务界面,所述服务界面用以输入提示文本和控制条件;
19、获取用户终端发送的提示文本和n个控制条件,所述n为正整数;
20、利用驱动控制层对所述n个控制条件进行编码,得到各控制条件的特征表示;
21、利用控制融合层对所述各控制条件的特征表示进行融合,得到融合特征表示;
22、将所述提示文本、所述融合特征表示和噪声图像输入图像生成模型,获取所述图像生成模型生成的结果图像,其中所述图像生成模型基于扩散模型实现;
23、将所述结果图像发送给所述用户终端以进行展示。
24、根据本技术实施例中一可实现的方式,所述服务界面包括用以输入提示文本的组件和用以输入控制条件的组件;
25、所述用以输入控制条件的组件包括:风格条件输入组件、位置条件输入组件和颜色条件输入组件中的至少一种,其中所述位置条件输入组件包括:实体编辑组件和手绘组件;
26、获取所述控制条件包括:解析所述提示文本包含的实体,在所述实体编辑组件显示解析得到的实体;获取用户利用所述手绘组件输入的位置框,按照位置框的输入顺序和所述实体编辑组件显示的实体顺序记录位置框与实体之间的对应关系。
27、第三方面,提供了一种模型训练方法,所述方法包括:
28、获取包括多个训练样本的训练数据,所述训练样本包括:提示文本、控制条件、对真值图像对应的隐向量进行ttrain个时间步的加噪声处理后得到的加噪图像隐向量以及在所述ttrain个时间步增加的噪声构成的噪声样本序列;
29、利用所述训练数据训练驱动控制层,其中所述训练包括:利用所述驱动控制层对训练样本中的控制条件进行编码,得到所述控制条件的特征表示;将该训练样本中的提示文本、控制条件的特征表示以及加噪图像隐向量输入图像生成模型,所述图像生成模型基于扩散模型实现,由图像生成模型利用所述提示文本和控制条件的特征表示对所述加噪图像隐向量进行去噪声处理,其中所述训练的目标包括:最小化所述去噪声处理过程中ttrain个时间步预测的噪声构成的预测噪声序列与对应噪声样本序列之间的差异。
30、根据本技术实施例中一可实现的方式,所述驱动控制层包括至少n个条件编码器,各类型的控制条件分别对应有独立的条件编码器,所述n为正整数;
31、使用各类型的控制条件对应的训练样本分别对各条件编码器进行训练。
32、根据本技术实施例中一可实现的方式,所述获取包括多个训练样本的训练数据包括:
33、获取第一图像、第一图像对应的风格信息以及第一图像的描述文本分别作为真值图像、控制条件和提示文本,用以构成风格控制条件对应的训练样本;或者,
34、将第二图像和第二图像的标题输入目标检测模型,获取目标检测模型输出的所述标题中实体在第二图像中的位置信息,将所述第二图像、所述标题以及所述位置信息分别作为真值图像、提示文本和控制条件,用以构成位置控制条件对应的训练样本;或者,
35、将第三图像进行下采样后调整到原始尺寸,得到该第三图像的颜色图,将第三图像、第三图像的描述文本以及颜色图分别作为真值图像、提示文本和控制条件,用以构成颜色控制条件对应的训练样本。
36、根据本技术实施例中一可实现的方式,所述扩散模型中的去噪网络包括至少m个尺度的隐层;
37、所述控制条件的特征表示包括控制条件对应的m个尺度的特征表示;
38、在将控制条件的特征表示输入图像生成模型时,将所述m个尺度的特征表示分别输入对应尺度的隐层;所述去噪网络中的各隐层分别将本隐层预测的隐向量与本隐层被输入的特征表示进行融合,将融合得到的隐向量输入下一隐层;
39、其中,所述隐层包括编码器隐层和/或解码器隐层。
40、第四方面,提供了一种图像生成装置,所述装置包括:
41、用户接口单元,被配置为获取输入的提示文本和n个控制条件,所述n为正整数;
42、驱动控制单元,被配置为利用驱动控制层对所述n个控制条件进行编码,得到各控制条件的特征表示;
43、控制融合单元,被配置为利用控制融合层对所述各控制条件的特征表示进行融合,得到融合特征表示;
44、图像生成单元,被配置为将所述提示文本、所述融合特征表示和噪声图像输入图像生成模型,获取所述图像生成模型生成的结果图像,其中所述图像生成模型基于扩散模型实现。
45、第五方面,提供了一种模型训练装置,所述装置包括:
46、样本获取单元,被配置为获取包括多个训练样本的训练数据,所述训练样本包括:提示文本、控制条件、对真值图像对应的隐向量进行ttrain个时间步的加噪声处理后得到的加噪图像隐向量以及在所述ttrain个时间步增加的噪声构成的噪声样本序列;
47、模型训练单元,被配置为利用所述训练数据训练驱动控制层,其中所述训练包括:利用所述驱动控制层对训练样本中的控制条件进行编码,得到所述控制条件的特征表示;将该训练样本中的提示文本、控制条件的特征表示以及加噪图像隐向量输入图像生成模型,所述图像生成模型基于扩散模型实现,由图像生成模型利用所述提示文本和控制条件的特征表示对所述加噪图像隐向量进行去噪声处理,其中所述训练的目标包括:最小化所述去噪声处理过程中ttrain个时间步预测的噪声构成的预测噪声序列与对应噪声样本序列之间的差异。
48、根据第六方面,提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一方面至第三方面中任一项所述的方法的步骤。
49、根据第七方面,提供了一种电子设备,包括:
50、一个或多个处理器;以及
51、与所述一个或多个处理器关联的存储器,所述存储器用于存储程序指令,所述程序指令在被所述一个或多个处理器读取执行时,执行上述第一方面至第三方面中任一项所述的方法的步骤。
52、根据本技术提供的具体实施例,本技术公开了以下技术效果:
53、1)本技术在提示文本的基础上进一步融入n个控制条件,利用驱动控制层和控制融合层分别对n个控制条件进行编码和融合得到融合特征表示,然后将融合特征表示、提示文本和噪声图像输入基于扩散模型实现的图像生成模型,使得图像生成模型不仅能够得到提示文本的引导,还能够在n个控制条件的指导下更加精细化地控制图像生成,提高图像生成的灵活性。
54、2)本技术中可以依据门控超参数控制融合特征表示输入图像生成模型的程度,使得融合特征表示仅在前tth个时间步参与图像生成模型中去噪网络的去噪声处理。这种处理方式使得图像生成模型生成的结果图像既能够满足控制条件的约束,又能够具备丰富的多样性。
55、3)本技术不仅在去噪网络的编码器隐层输入控制条件的融合特征表示,在解码器隐层也输入控制条件的融合特征表示,使得去噪网络充分理解控制条件的约束并用于图像生成,从而提高对生成图像的控制能力。
56、4)本技术通过服务界面上用以输入控制条件的组件,方便地实现各控制条件的输入,特别是通过手绘组件和实体编辑组件的配合,方便地实现位置条件的输入。这种服务界面实现了一种简单易用的用户接口,无需很高的专业知识背景,普通用户也能够简单上手。
57、5)本技术实施例中仅针对驱动控制层训练各控制条件对应的条件编码器,无需对图像生成模型的结构和参数进行变更,一方面降低了参数计算量和训练成本,另一方面,具有高度的可扩展性和即插即用性。
58、当然,实施本技术的任一产品并不一定需要同时达到以上所述的所有优点。
- 还没有人留言评论。精彩留言会获得点赞!