一种人员成长路径匹配方法、设备及介质
本技术涉及人力资源的,具体涉及一种人员成长路径匹配方法、设备及介质。
背景技术:
1、人员成长路径规划是现代人力资源管理中的一个重要环节,合理科学的成长路径规划可以帮助组织将人员安排至合适的岗位,也可为个人的发展规划提供建议,使人员的职业目标及计划和组织的需要保持一致,实现个人和组织的双赢。
2、目前,针对人员成长路径规划主要为基于节点局部信息的相似性和基于路径相似性的方法。其中,基于节点局部信息的相似性基本思想是一组节点对的共同邻居数量越多,则更容易产生链接,其相似性越高;基于路径相似性则是捕捉路径拓扑之间的相似性,即两条路径中的相同拓扑点与相同边越多,则相似性越高。
3、然而,上述两种人员成长路径规划方式中,基于节点局部信息的相似性在大规模的人员成长路径匹配会导致匹配结果不完整,基于路径的相似性若路径长度相差较大即使拓扑结构相似,也会导致相似度较低的情况发生,从而降低匹配结果的精准度。
技术实现思路
1、针对基于节点局部信息的相似性与基于路径的相似性对人员成长路径匹配精度低的问题,本技术提供了一种人员成长路径匹配方法、设备及介质。
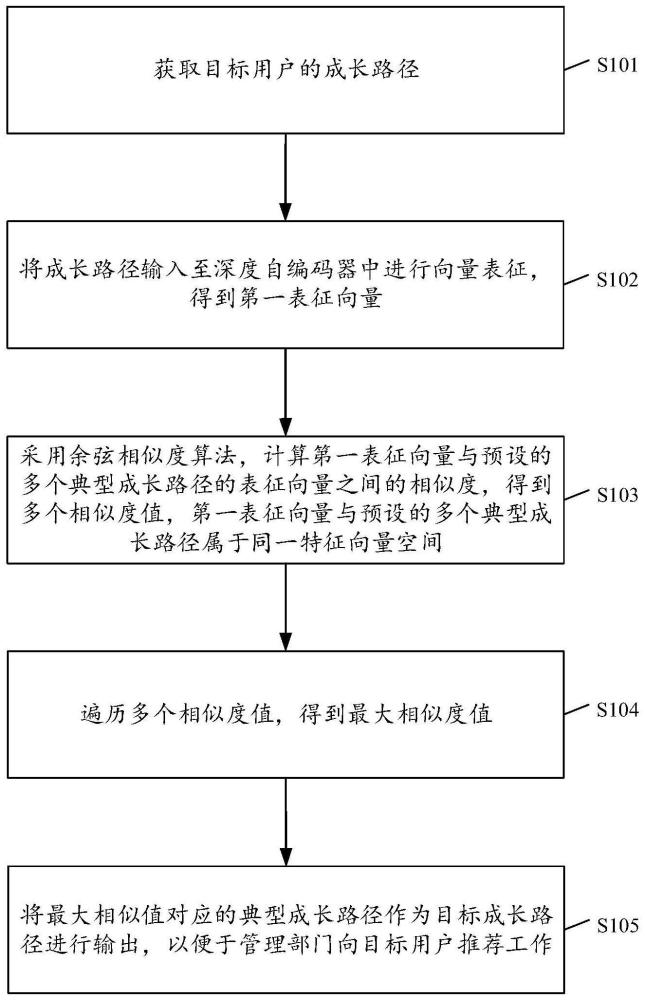
2、第一方面,本技术提供一种人员成长路径匹配方法,应用于服务器,方法包括:获取目标用户的成长路径;将成长路径输入至深度自编码器中进行向量表征,得到第一表征向量;采用余弦相似度算法,计算第一表征向量与预设的多个典型成长路径的表征向量之间的相似度,得到多个相似度值,第一表征向量与预设的多个典型成长路径属于同一特征向量空间;遍历多个相似度值,得到最大相似度值;将最大相似值对应的典型成长路径作为目标成长路径进行输出,以便于管理部门向目标用户推荐工作。
3、通过采用上述技术方案,对于目标用户的成长路径,首先将其输入至深度自编码器中,以得到低维向量空间的第一表征向量,此时第一表征向量不仅能够表征长度不同的大规模成长路径,并且第一表征向量与典型成长路径的表征向量属于同一特征向量空间中,能够有效降低路径长度相差较大对相似度的影响;最后,从预设的多个典型成长路径的向量表征中,选取与第一向量表征相似度最高的向量表征,将该向量表征对应的典型成长路径作为目标用户的推荐成长路径,以提高人员成长路径的匹配精度。
4、第二方面,本技术提供一种人员成长路径匹配设备,设备为服务器,服务器包括接收模块、处理模块与输出模块,其中:
5、接收模块,用于获取目标用户的成长路径;
6、处理模块,用于将成长路径输入至深度自编码器中进行向量表征,得到第一表征向量;采用余弦相似度算法,计算第一表征向量与预设的多个典型成长路径的表征向量之间的相似度,得到多个相似度值,第一表征向量与预设的多个典型成长路径属于同一特征向量空间;
7、输出模块,用于遍历多个相似度值,得到最大相似度值;将最大相似值对应的典型成长路径作为目标成长路径进行输出,以便于管理部门向目标用户推荐工作。
8、可选的,接收模块将成长路径构建为加权有向图g(v,e,w),其中,v为目标用户发展经历的岗位节点,e为有向边集合,用于表示岗位节点之间的发展指向,w为有向边权重集合;
9、处理模块提取加权有向图的多个一阶邻近关系与多个二阶邻近关系,一阶邻近关系包括两个岗位节点之间的连接关系,二阶邻近关系为两个岗位节点领域之间的连接关系,岗位节点领域由多个连接的岗位节点组成;将多个一阶邻近关系输入至深度自编码器中进行监督训练,将多个二阶邻近关系输入至深度自编码器中进行半监督训练;
10、当深度自编码器的损失函数值小于预设损失函数值,则确定深度自编码器训练完成,输出模块输出深度自编码器的隐层,将隐层作为第一表征向量,深度自编码器的损失函数为第一损失函数与第二损失函数之和,其中,第一损失函数为监督训练对应的损失函数,第二损失函数为半监督训练对应的损失函数。
11、通过采用上述技术方案,将目标用户的成长路径构建为加权有向图,然后根据加权有向图中的一阶邻近关系与二阶邻近关系作为训练集输入至深度自编码器中进行监督训练与半监督训练,深度自编码器具备输入层、隐层以及输出层,其中,隐层用于提取输入数据的特征,将特征以隐层中的激活值向量进行特征表达,因此当深度自编码器训练完成时,隐层也完成了输入数据的特征提取与特征向量的表达,最后将隐层的特征向量求平均值进行聚合,从而实现将高维度的成长路径转换为低维度的第一表征向量,以此即保证第一表征向量涵盖成长路径的所有关键特征,也使其能够与不同路径长度的典型成长路径进行匹配,得到最优的典型成长路径。
12、可选的,获取目标用户的成长路径之前,还包括:获取模块获取目标用户的岗位变动信息;基于岗位变动信息构建目标用户的第一成长路径;处理模块对第一成长路径的多个岗位进行特征提取,得到多个岗位各自对应的多个岗位特征;基于多个岗位各自对应的多个岗位特征,从预设岗位数据库从获取多个岗位各自对应的子岗位;基于多个岗位各自对应的子岗位,构建第二成长路径,将第二成长路径作为目标用户的成长路径。
13、通过采用上述技术方案,为了进一步提升典型成长路径与目标用户的成长路径的匹配精度,通过对用户原始的第一成长路径中的每个岗位进行特征提取,再将提取的岗位特征与预设岗位数据库进行匹配,从而得到第一成长路径中每个岗位可能存在的细化岗位,例如,后厨可能分为糕点师、调味师以及蒸锅手等,然后将每个岗位可能存在的细化岗位构建为第二成长路径,以此作为目标用户当前的成长路径,为后续进行深度自编码器提供更多的岗位细节,从而提升典型成长路径的匹配精度。
14、可选的,处理模块采用第一损失函数计算一阶邻近关系的一阶邻近度,一阶邻近度为两个岗位节点之间的相似度,将一阶邻近度作为第一损失函数值。
15、通过采用上述技术方案,通过将一阶邻近度作为监督训练的损失函数值,从而使得深度自编码器的神经网络中将两个有向边相连的岗位节点具备相似性,进而使得深度自编码器保留加权有向图的局部结构,提升最终隐层输出数据的准确性。
16、可选的,其中,loss1nd为第一损失函数值,wij为第i岗位节点与第j岗位节点之间的有向边权重,hi为第i岗位节点的向量表征,hj为第j岗位节点的向量表征。
17、通过采用上述技术方案,第一损失函数值大于0,则说明两个岗位节点之间存在有向边连接,其中以有向边权重来调整两个岗位节点之间关联度,从而实现加权有向图的局部结构的保留。
18、可选的,处理模块根据加权有向图中多个岗位节点各自对应的节点入度与节点出度,构建加权有向网络的邻接矩阵;根据邻接矩阵与惩罚参数,采用预设第二损失函数计算深度自编码器进行半监督训练的第二损失函数值。
19、通过采用上述技术方案,通过将多个岗位节点各自对应节点入度与节点出度构建为邻接矩阵,以此将多个岗位节点之间的连接关系与关联权重进行表示,此时加权有向图中多个节点之间的关联权重差异较大,为降低个别高度节点对于神经网络优化的影响,引入惩罚参数,增加非零元素重构误差的惩罚,避免了重构过程中重构零元素的倾向,使深度自编码器对稀疏网络具有鲁棒性,结构数据也被非零元素完全保留。
20、可选的,第二损失函数值,具体为:
21、
22、其中,xi为邻接矩阵,为邻近矩阵的均值,bi为惩罚参数,⊙为哈达玛积,它执行两个相同维度矩阵之间对应元素相乘的操作。
23、通过采用上述技术方案,为了进一步降低个别高度节点对神经网络优化的影响,计算第二损失函数值采用绝对值代替平方差,从而降低高权重节点对损失函数的贡献,使得优化过程倾向于更多的低权重节点。
24、第三方面,本技术提供一种电子设备,包括处理器、存储器、用户接口及网络接口,所述存储器用于存储指令,所述用户接口和网络接口用于给其他设备通信,所述处理器用于执行所述存储器中存储的指令,以使所述电子设备执行如第一方面中任意一项所述的方法。
25、第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质存储有指令,当所述指令被执行时,执行如第一方面中任意一项所述的方法。
26、综上所述,本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
27、1、对于目标用户的成长路径,首先将其输入至深度自编码器中,以得到低维向量空间的第一表征向量,此时第一表征向量不仅能够表征长度不同的大规模成长路径,并且第一表征向量与典型成长路径的表征向量属于同一特征向量空间中,能够有效降低路径长度相差较大对相似度的影响;最后,从预设的多个典型成长路径的向量表征中,选取与第一向量表征相似度最高的向量表征,将该向量表征对应的典型成长路径作为目标用户的推荐成长路径,以提高人员成长路径的匹配精度。
28、2、将目标用户的成长路径构建为加权有向图,然后根据加权有向图中的一阶邻近关系与二阶邻近关系作为训练集输入至深度自编码器中进行监督训练与半监督训练,深度自编码器具备输入层、隐层以及输出层,其中,隐层用于提取输入数据的特征,将特征以隐层中的激活值向量进行特征表达,因此当深度自编码器训练完成时,隐层也完成了输入数据的特征提取与特征向量的表达,最后将隐层的特征向量求平均值进行聚合,从而实现将高维度的成长路径转换为低维度的第一表征向量,以此即保证第一表征向量涵盖成长路径的所有关键特征,也使其能够与不同路径长度的典型成长路径进行匹配,得到最优的典型成长路径。
- 还没有人留言评论。精彩留言会获得点赞!