一种基于身份脸型特征的深度伪造检测方法
本发明涉及深度伪造检测,具体涉及一种基于身份脸型特征的深度伪造检测方法。
背景技术:
1、近年来深度伪造技术不断发展,一些开源方法导致普通大众也可以改变图像的身份,并且在普通人看来难以区分真假。一方面利用深度伪造可以用于娱乐和影视制作等项目,另一方面它被滥用于恶意传播、网络诈骗等非法目的,导致了十分恶劣的影响。
2、传统的深度伪造检测方法直接将深度伪造检测问题作为二分类问题,使用骨干网络直接对真假图像进行分类,检测性能表现一般。后来的方法大多精心设计模块捕捉生成器遗留的伪造痕迹,但是这些方法的泛化性表现较差,模型拟合与特定方法,在实际应用中对于未知伪造方式生成的人脸检测性能急剧下降。
技术实现思路
1、本发明为了克服以上技术的不足,提供了一种检测人脸具有更强的针对性的基于身份脸型特征的深度伪造检测方法。
2、本发明克服其技术问题所采用的技术方案是:
3、一种基于身份脸型特征的深度伪造检测方法,包括如下步骤:
4、a)获取视频,得到训练集和测试集,从训练集中提取张量xtrain,从测试集中提取张量x′test和x′ref;
5、b)将张量xtrain输入到身份编码器中,输出得到人脸身份特征
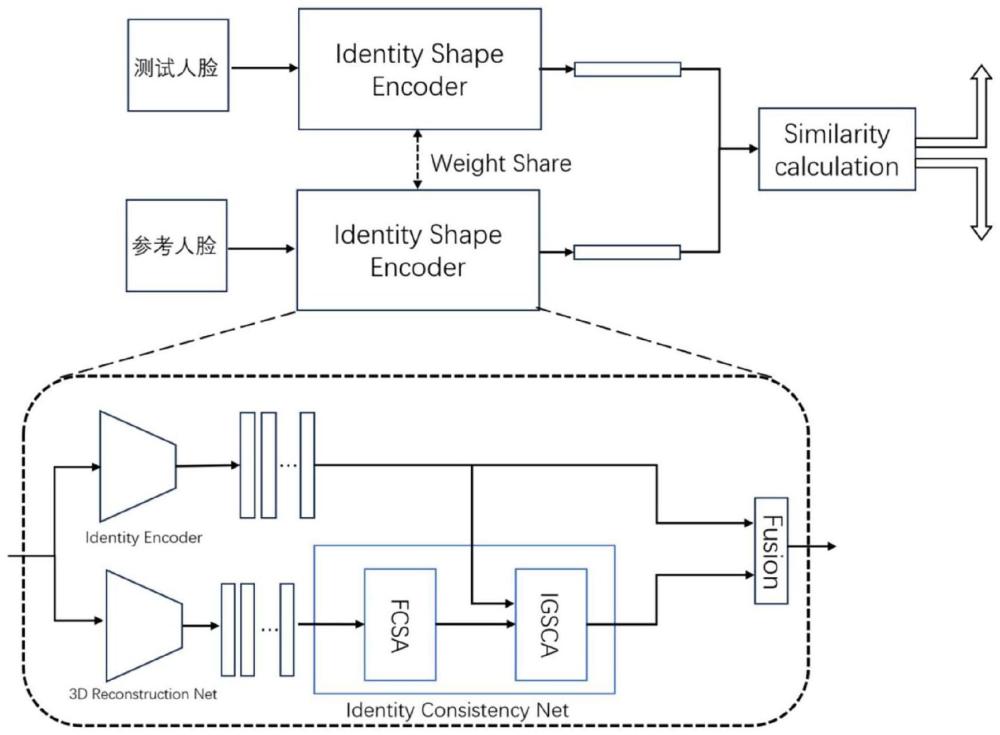
6、c)建立身份特征一致性网络,身份特征一致性网络由3d重建编码器、身份脸型一致性提取网络、融合单元构成;
7、d)将张量xtrain输入到身份特征一致性网络的3d重建编码器中,输出得到脸型特征fshape;
8、e)将特征fshape及人脸身份特征fid输入到身份特征一致性网络的身份脸型一致性提取网络中,输出得到身份脸型一致性特征fisc;
9、f)将人脸身份特征fid与身份脸型一致性特征fisc输入到身份特征一致性网络的融合单元中进行融合得到特征fic;
10、g)计算损失函数l,利用损失函数l对身份特征一致性网络进行训练,得到优化后的身份特征一致性网络;
11、h)将张量x′test输入到优化后的身份特征一致性网络中,输出得到特征f′ic,将x′ref输入到优化后的身份特征一致性网络中,输出得到特征f″ic,通过公式s=δ(f′ic,f″ic)计算得到相似度值s,式中δ(·,·)为余弦相似度计算函数,当相似度值s大于等于阈值τ时判定视频中的人脸为真实人脸,当相似度值s小于τ时判定视频中的人脸为伪造人脸。
12、进一步的,步骤a)包括如下步骤:
13、a-1)从面部伪造数据集faceforensics++中选择n个视频作为训练集vtrain,选择m个视频作为测试集vtest,vtrain=vf+vr={v1,v2,...,vn,...,vn},训练集中包含nf个伪造视频和nr个真实视频,nf+nr=n,vf为伪造视频集,vr为真实视频集,vn为第n个视频,n∈{1,...,n},第n个视频vn具有l个图像帧构成,vn={x1,x2,...,xj,...,xl},xj为第j个图像帧,j∈{1,...,l},xj的类型标签为yj,第j个图像帧xj为真实图像时,xj取值为0,第j个图像帧xj为伪造图像时,xj取值为1,第j个图像帧xj的源身份标签为测试集vtest=v′f+v′r={v1,v2,...,vm,...,v′m},测试集中包含mf个伪造视频和mr个真实视频,mf+mr=m,v′f为伪造视频集,v′r为真实视频集,v′m为第m个视频,m∈{1,...,m};
14、a-2)使用opencv包中的videoreader类逐帧读取训练集中第n个视频vn后随机提取第n个视频vn中t个连续的视频帧作为训练视频vtrain,通过mtcnn算法检测训练视频vtrain中每个视频帧的人脸关键点并标正人脸图像,将标正的人脸图像截取后得到人脸图像矩阵x′train;
15、a-3)使用opencv包中的videoreader类逐帧读取测试集中的伪造视频集v′f的第m个视频v′m后随机提取第m个视频v′m中t个连续的视频帧作为测试视频vtest_1,使用opencv包中的videoreader类逐帧读取测试集中的真实视频集v′r的第m个视频v′m后随机提取第m个视频v′m中两组t个连续的视频帧,第一组连续的视频帧为测试视频vtest_2,第二组连续的视频帧为参考视频vref,通过公式vtest=vtest_1+vtest_2计算得到测试视频vtest,通过mtcnn算法检测测试视频vtest中每个视频帧的人脸关键点并标正人脸图像,将标正的人脸图像截取后得到人脸图像矩阵x′test,通过mtcnn算法检测参考视频vref中每个视频帧的人脸关键点并标正人脸图像,将标正的人脸图像截取后得到人脸图像矩阵x′ref;
16、a-4)利用pytorch中的totensor()函数将人脸图像矩阵x′train转化为张量xtrain,xtrain∈rt×c×h×w,将人脸图像矩阵x′test转化为张量xtest,xtest∈rt×c×h×w,将人脸图像矩阵x′ref转化为张量xref,xref∈rt×c×h×w,r为实数空间,c为图像帧通道数,h为图像帧高度,w为图像帧高度。
17、进一步的,步骤b)中身份编码器由arcface人脸识别模型构成,将张量xtrain输入到身份编码器中,输出得到训练集中的第n个视频vn的身份特征f′id,f′id∈rt×512,将身份特征f′id通过pytorch中的tensor.transpose()函数转换得到训练集中的第n个视频vn的人脸身份特征n∈{1,...,n}。
18、进一步的,步骤d)包括如下步骤:
19、d-1)身份特征一致性网络的3d重建编码器由预训练的deep3dfacerecon网络构成;
20、d-2)将张量xtrain输入到3d重建编码器中,输出得到3dmm身份特征f′shape;d-3)将3dmm身份特征f′shape利用pytorch中的tensor.transpose()函数转换得到脸型特征fshape,fshape∈r257×t。
21、进一步的,步骤e)包括如下步骤:
22、e-1)身份特征一致性网络的身份脸型一致性提取网络由脸型一致性自注意力模块、身份引导脸型一致性注意力模块构成;
23、e-2)身份脸型一致性提取网络的脸型一致性自注意力模块由时间卷积块、第一残差卷积块、第二残差卷积块、第三残差卷积块、第一自注意力块、第二自注意力块、第三自注意力块、第四自注意力块构成;
24、e-3)脸型一致性自注意力模块的时间卷积块由1d卷积层、layernorm层、leakeyrelu函数构成,将脸型特征fshape输入到1d卷积层中,输出得到特征将特征输入到layernorm层中,输出得到特征将特征输入到leakeyrelu函数中,输出得到特征e-4)脸型一致性自注意力模块的第一残差卷积块、第二残差卷积块、第三残差卷积块均由1d卷积层、layernorm层、leakeyrelu函数构成,将特征输入到第一残差卷积块的1d卷积层中,输出得到特征将特征输入到第一残差卷积块的layernorm层中,输出得到特征将特征输入到第一残差卷积块的leakeyrelu函数中,输出得到特征将特征与特征相加得到特征将特征输入到第二残差卷积块的1d卷积层中,输出得到特征将特征输入到第二残差卷积块的layernorm层中,输出得到特征将特征输入到第二残差卷积块的leakeyrelu函数中,输出得到特征将特征与特征相加得到特征将特征输入到第三残差卷积块的1d卷积层中,输出得到特征将特征输入到第三残差卷积块的layernorm层中,输出得到特征将特征输入到第三残差卷积块的leakeyrelu函数中,输出得到特征将特征与特征相加得到特征e-5)脸型一致性自注意力模块的第一自注意力块、第二自注意力块、第三自注意力块、第四自注意力块均由多头注意力机制、layernorm层构成,将特征通过pytorch中的tensor.transpose()函数转换得到特征将特征输入到第一自注意力块的多头注意力机制中,输出得到特征将特征输入到第一自注意力块的layernorm层中,输出得到特征将特征与特征相加得到特征将特征输入到第二自注意力块的多头注意力机制中,输出得到特征将特征输入到第二自注意力块的layernorm层中,输出得到特征将特征与特征相加得到特征将特征输入到第三自注意力块的多头注意力机制中,输出得到特征将特征输入到第三自注意力块的layernorm层中,输出得到特征将特征与特征相加得到特征将特征输入到第四自注意力块的多头注意力机制中,输出得到特征将特征输入到第四自注意力块的layernorm层中,输出得到特征将特征与特征相加得到特征
25、e-6)身份特征一致性网络的身份引导脸型一致性注意力模块由身份特征映射块、第一交叉注意力块、第二交叉注意力块、第三交叉注意力块、第四交叉注意力块、第一空洞卷积块、第二空洞卷积块、第三空洞卷积块、第四空洞卷积块、第五空洞卷积块构成;
26、e-7)身份引导脸型一致性注意力模块的身份特征映射块由1d卷积层、layernorm层、leakeyrelu函数构成,将人脸身份特征输入到身份特征映射块的1d卷积层中,输出得到特征将特征输入到身份特征映射块的layernorm层中,输出得到特征将特征输入到身份特征映射块的leakeyrelu函数中,输出得到特征将特征通过pytorch中的tensor.transpose()函数转换得到特征e-8)身份引导脸型一致性注意力模块的第一交叉注意力块、第二交叉注意力块、第三交叉注意力块、第四交叉注意力块均由多头注意力机制、layernorm层、leakeyrelu函数构成,将特征通过线性变换计算第一交叉注意力块的多头注意力机制的query值,将特征通过线性变换计算第一交叉注意力块的多头注意力机制的key值和value值,得到第一交叉注意力块的多头注意力机制的输出特征将特征输入到第一交叉注意力块的layernorm层中输出得到特征将特征与特征进行相加操作得到特征将特征通过线性变换计算第二交叉注意力块的多头注意力机制的query值,将特征通过线性变换计算第二交叉注意力块的多头注意力机制的key值和value值,得到第二交叉注意力块的多头注意力机制的输出特征将特征输入到第二交叉注意力块的layernorm层中输出得到特征将特征与特征进行相加操作得到特征将特征通过线性变换计算第三交叉注意力块的多头注意力机制的query值,将特征通过线性变换计算第三交叉注意力块的多头注意力机制的key值和value值,得到第三交叉注意力块的多头注意力机制的输出特征将特征输入到第三交叉注意力块的layernorm层中输出得到特征将特征与特征进行相加操作得到特征将特征通过线性变换计算第四交叉注意力块的多头注意力机制的query值,将特征通过线性变换计算第四交叉注意力块的多头注意力机制的key值和value值,得到第四交叉注意力块的多头注意力机制的输出特征将特征输入到第四交叉注意力块的layernorm层中输出得到特征将特征与特征进行相加操作得到特征
27、e-9)身份引导脸型一致性注意力模块的第一空洞卷积块、第二空洞卷积块、第三空洞卷积块、第四空洞卷积块、第五空洞卷积块由空洞卷积层、groupnorm层、leakeyrelu函数构成,将特征输入到第一空洞卷积块的空洞卷积层中,输出得到特征将特征输入到第一空洞卷积块的groupnorm层中,输出得到特征将特征输入到第一空洞卷积块的leakeyrelu函数中,输出得到特征将特征与特征进行相加操作得到特征将特征输入到第二空洞卷积块的空洞卷积层中,输出得到特征将特征输入到第二空洞卷积块的groupnorm层中,输出得到特征将特征输入到第二空洞卷积块的leakeyrelu函数中,输出得到特征将特征与特征进行相加操作得到特征将特征输入到第三空洞卷积块的空洞卷积层中,输出得到特征将特征输入到第三空洞卷积块的groupnorm层中,输出得到特征将特征输入到第三空洞卷积块的leakeyrelu函数中,输出得到特征将特征与特征进行相加操作得到特征将特征输入到第四空洞卷积块的空洞卷积层中,输出得到特征将特征输入到第四空洞卷积块的groupnorm层中,输出得到特征将特征输入到第四空洞卷积块的leakeyrelu函数中,输出得到特征将特征与特征进行相加操作得到特征将特征输入到第五空洞卷积块的空洞卷积层中,输出得到特征将特征输入到第五空洞卷积块的groupnorm层中,输出得到特征将特征输入到第五空洞卷积块的leakeyrelu函数中,输出得到特征将特征与特征进行相加操作得到身份脸型一致性特征fisc,fisc∈r512。
28、优选的,步骤e-3)中时间卷积块的1d卷积层的卷积核大小为1、步长为2、填充为0;步骤e-4)中第一残差卷积块、第二残差卷积块、第三残差卷积块的1d卷积层的卷积核大小均为1、步长均为2、填充均为0;步骤e-5)中第一自注意力块、第二自注意力块、第三自注意力块、第四自注意力块的多头注意力机制的头数量均为6;步骤e-7)中身份特征映射块的1d卷积层的卷积核大小为3、步长为1、填充为1;步骤e-8)中第一交叉注意力块、第二交叉注意力块、第三交叉注意力块、第四交叉注意力块的多头注意力机制的头数量均为8;步骤c-9)中第一空洞卷积块、第二空洞卷积块的空洞卷积层的卷积核大小均为3、步长均为1、填充均为0、扩张系数均为2,第三空洞卷积块、第四空洞卷积块、第五空洞卷积块的空洞卷积层的卷积核大小均为3、步长均为1、填充均为0、扩张系数均为4,第一空洞卷积块、第二空洞卷积块、第三空洞卷积块、第四空洞卷积块、第五空洞卷积块的groupnorm层的分组大小均为16。
29、进一步的,步骤f)包括如下步骤:
30、f-1)将人脸身份特征输入到身份特征一致性网络的融合单元中,利用pytorch中的torch.mean()函数计算人脸身份特征的平均值,得到身份特征
31、f-2)利用pytorch中的torch.concat()函数将身份特征与身份脸型一致性特征fisc进行拼接,得到特征fic。
32、进一步的,步骤g)包括如下步骤:
33、g-1)通过公式l=ηlsid+λl(femb)计算损失函数l,式中η和λ均为缩放系数,lsid为伪造身份嵌入优化损失,l(femb)为有监督的对比学习损失,式中表示等于时取值为1,不等于时取值为0,为第i个图像帧xi的源身份标签,i∈{1,...,l},δ(·,·)为余弦相似度计算函数,为训练集中第i个视频vi的人脸身份特征,i∈{1,...,n},为训练集中第j个视频vj的人脸身份特征,j∈{1,...,n};
34、g-2)利用adam优化器通过损失函数l训练身份特征一致性网络,得到优化后的身份特征一致性网络。
35、优选的,η取值为0.2,λ取值为0.8。
36、优选的,步骤h)中τ∈(0,1)。
37、本发明的有益效果是:引入身份特征与3d人脸形状特征相结合,设计了脸型一致性自注意力模块、身份引导脸型一致性注意力模块,挖掘其中的身份脸型不一致特征,根据不同检测人脸的参考人脸信息,具有更强的针对性。利用参考人脸的身份信息和形状信息实现更强的泛化检测性能,提高人脸检测性能和精准度。
- 还没有人留言评论。精彩留言会获得点赞!