基于情感调控对抗网络的虚拟教师人脸视频生成方法
本发明属于人工智能领域,涉及说话人脸视频生成技术,具体涉及一种基于情感调控对抗网络的虚拟教师的说话人脸高精细视频生成方法。
背景技术:
1、人脸是人类最主要的生物特征,也是目前应用最为广泛的生物特性之一。人物面部携带并表达着人物的身份和情感等信息。会说话的人脸生成旨在使用视觉输入和音频创建逼真的视频。这些视频在教育、数字动画、短视频创作、娱乐、广告、游戏等领域都有巨大的应用需求与前景。
2、虚拟教师正日益成为在教育元宇宙的突破性技术,已引起学术界、产业界的广泛关注。但在教育元宇宙中由于教师与学生处于时空上的准分离状态,很难感受到对方的情感,致使其“情感缺失”,导致学生专注度下降、学习投入不足等典型问题。因此,在教育元宇宙中构建情感可调控、细致丰富、与真人相似的虚拟教师,在学生出现学习效率下降、学习投入不足等状态时,给予学生情感化引导,如满意的表情、称赞的话语、鼓励的手势、关切的微笑、温情的提示等,让学生感受到真实教学场景下的情感吸引力,与虚拟教师产生“情感共鸣”,是保障学生参与度和学习效果的有效途径。因此,会说话的、情感丰富且可调控的人脸生成是构建虚拟教师的核心关键技术。
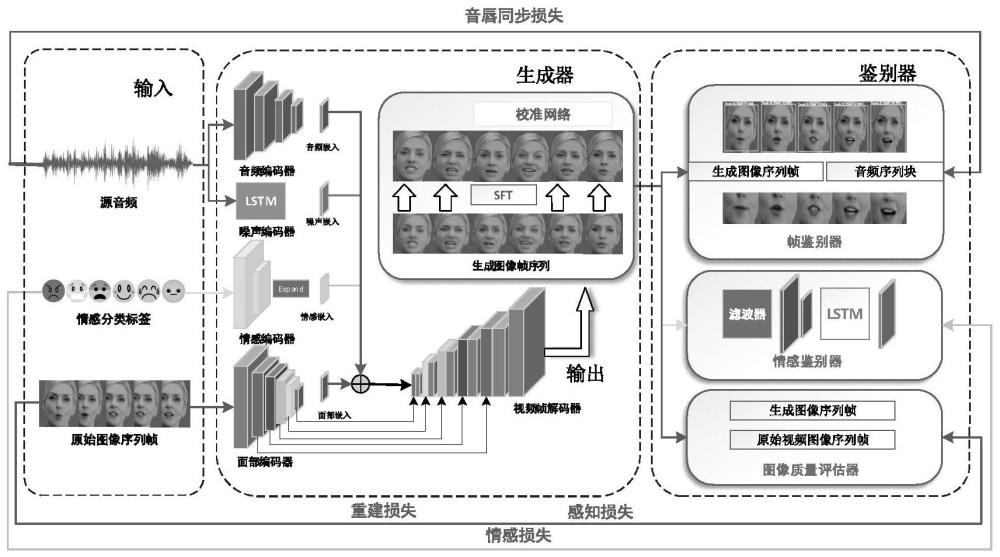
3、其中一种方法是将语音转换为面部关键点,然后使用预测的关键点来估计视频中的人脸帧。从音频文件中提取的特征通常包括梅尔频率倒频谱系数(mfcc)、能量以及这些特征的一阶时间和二阶时间导数,将人脸图像和音频特征作为输入,并生成说话人脸的视频。在生成头部姿态方面的工作,有的方法使用lstm动态预测音频对应的头部姿势,或者对音频特征进行预处理,去除身份信息,以提取3dmm的表情特征,与源视频中的人脸纹理特征和姿势特征进行融合。关于音频和口型同步方面的工作,通过引入了与输入音频相对应的口腔区域的视觉信息,增强细粒度的视听一致性,将来自连续图像的唇部运动特征与相应的音频特征对齐。
4、通过添加视觉情感,可以使虚拟教师的"说话的脸"视频变得更加逼真。有方法基于此提出了一种双分支结构模型,一个分支仅用于修改面部上半部分的情感,而另一个分支则使用基于lstm的音频到面部特征点模块修改下半部分。这就导致了人脸上半部分和下半部分情感的不一致和矛盾。或者根据音频数据明确分离出音频中的情感信息,然后在生成的会说话的人脸中呈现。但是仅从音频中预测情感是很困难的,需要视觉线索来理解或解释上下文,无法独立控制视觉中的情感表达,且受到语音情感识别精度的限制。
5、现有方法存在的一些问题:一是生成的口型不准确,虽然现有的方法可以产生相对连贯和自然的嘴部动作,但是很难令生成的嘴部动作变化和音频变化保持一致,缺乏一定的真实性;二是生成人脸的情感不同步,面部表情是生成的说话人脸是否逼真的关键因素,虽然可以从额外的数据中挖掘情感信息,但是由于情感与音频之间的域差,导致视听情感的不同步;三是生成人脸的图像质量低,由于现存方法往往无法捕捉到由于面部表情变化所引起的面部的纹理变化,即生成的图片模糊,比如,牙齿或者嘴唇细节不清晰等。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于情感调控对抗网络的虚拟教师人脸视频生成方法,提高生成视频的视听一致性,优化生成面部特征细节,且允许独立控制生成的视觉信号的情感。
2、为达到上述目的,本发明提供如下技术方案:
3、一种基于情感调控对抗网络的虚拟教师人脸视频生成方法,其特征在于:该方法包括以下步骤:
4、s1、获取包含情感分类的人物视频数据集,对人物视频数据集预处理后按比例分为训练数据集、验证数据集和测试数据集;
5、s2、采用音频编码器和噪声编码器处理从所述人物视频数据集中分离出的音频,提取音频特征,用于对齐生成虚拟教师人脸图像的说话口型;采用面部编码器根据输入的人脸图像提取面部特征,并编码为向量表示;
6、其中,在模型的训练过程中,通过对视频中不同帧的同一身份的人脸进行对齐以简化训练,具体地,首先为视频人脸选择一张具有面部对称性的模板图像,对于每段人脸视频,采用三个点来估计第一帧的模板面部关键点和标准面部关键点之间的相似性。
7、s3、将音频特征和面部特征输入视频解码器,并以情感标签为调控条件,通过跳转连接生成音频与口型同步且表达指定情感的虚拟教师人脸视频;所述情感标签通过对基本情感类别进行建模得到;对建模的基本情感类别进行编码得到情感特征,并将所述情感特征嵌入到所述面部特征中,从而能够独立控制虚拟教师人脸的情感;
8、其中,基本情感类别包括快乐、悲伤、恐惧、愤怒、厌恶和中性。
9、s4、在所述视频解码器的输出部分加入校准网络,增强生成的虚拟教师人脸的面部细节;
10、s5、将所生成的虚拟教师人脸视频分别输入帧鉴别器、图像质量鉴别器和情感鉴别器中;所述帧鉴别器用于判断虚拟教师人脸视频中嘴唇的形状和运动是否与音频内容相匹配;所述图像质量鉴别器用于分析虚拟教师人脸视频与原始的人脸视频数据集间的图像质量差异;所述情感鉴别器用于评估虚拟教师人脸是否能准确表达所需的情感;
11、s6、经过步骤s5中各鉴别器调整后,输出最终的虚拟教师说话人脸高精细视频。
12、进一步地,步骤s5中,通过帧鉴别器分别判断虚拟教师人脸视频中嘴唇的形状和运动是否与音频内容相匹配,以及判断虚拟教师人脸视频中音频与视频的时间对准程度;
13、判断虚拟教师人脸视频中嘴唇的形状和运动是否与音频内容相匹配包括:通过面部编码器提取与嘴唇运动相关的特征elip,并通过帧鉴别器将特征elip与音频特征对齐;计算二元交叉熵损失的余弦相似性以测量生成的唇部图像与真实唇部图像之间的相似程度;
14、嘴唇同步的损失表示为:
15、
16、式中,esync表示嘴唇同步损失,衡量生成口型的准确性;n表示输入图像帧的数量,表示第i个生成图像帧的估计参数,表示第i个原始图像帧的估计参数,表示第i个图像参考帧,||·||1表示l1范式;
17、判断虚拟教师人脸视频中音频与视频的时间对准程度包括:通过一训练好的视听同步模块从干净的音频和视频剪辑对中学习,并输出音频特征fa和视频特征fv,从而计算余弦相似度的二元交叉熵:
18、
19、式中,||·||2表示l2范式;再根据该余弦相似度的二元交叉熵计算音视频同步的损失,从而判断音频与视频的时间对准程度:
20、
21、ai表示与视频帧序列相对应的音频片段;fa和fv分别表示对视听同步模块进行训练的音频模块和视频模块。
22、进一步地,步骤s5中,通过图像质量鉴别器分析虚拟教师人脸视频与原始的人脸视频数据集间的图像质量差异;并根据生成视频的图像帧与原始视频图像帧之间的差异调整生成器参数以减少重建损失;其中重建损失如下式所示:
23、
24、式中,lrecon表示重建损失。
25、进一步地,步骤s5中,通过情感鉴别器评估虚拟教师人脸是否能准确表达所需的情感,具体地,通过分析情感标签与生成视频的情感之间的关联程度以判断生成视频中人脸表情与情感表达的一致性和真实性;其中情感损失表示为:
26、
27、式中,lemo表示情感损失,m表示基本情感类别,表示样本i属于某基本情感类别的预测概率;yi表示样本i的情感类别预测结果,若预测正确则yi=1,否则yi=0。
28、本发明的有益效果在于:
29、(1)本发明通过对情感进行编码并嵌入面部特征中,能够独立控制虚拟教师的情感表达,不需要话语中的情感信息;可以将虚拟教师融入到教育元宇宙中,根据教育元宇宙中学生的行为,调控合适的情感反馈;
30、(2)本发明通过帧鉴别器同时提取人脸特征序列和音频特征序列的特征,经过编码和归一化处理,确定生成人脸视频中嘴唇的形状和运动是否与音频内容相匹配,并在整个视频中保持虚拟老师的身份的一致性;
31、(3)本发明通过校准网络模块提取多分辨率空间特征,对扭曲特征进行空间特征变换;增强了虚拟教师生成的面部细节(包括牙齿、嘴唇、眉毛等),并提高了图像的清晰度。
32、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!