主动定向式数据蒸馏的联邦学习方法、装置及系统
本发明涉及联邦学习,具体涉及一种主动定向式数据蒸馏的联邦学习方法、装置及系统。
背景技术:
1、随着对数据安全和隐私的关注日益增加,数据在组织间或个人之间的共享变得越发复杂。在这一背景下,联邦学习技术应运而生,它能够在分布式设备上进行模型训练,并同时在本地维护数据。一般而言,联邦学习的范式涉及通过计算服务器上不同局部模型参数的平均值来迭代更新全局模型,同时在每个客户端上通过多轮通信利用私有数据来优化局部模型。然而,在现实世界中,不同客户端的局部数据通常并不是独立且同分布的,从而导致了不同的本地优化方向,进而影响了聚合后的全局模型性能。
2、为了解决这个问题,通常采用基于正则化的方式,即通过约束每个局部模型的更新方向与全局模型保持一致来实现。其次,采用知识蒸馏方式,通过使全局模型在额外的公共数据集上的输出与局部模型集成的输出保持一致,从而改进全局模型。另外,采用合成数据共享方式,通过数据增强或者利用生成对抗网络(gan)生成合成数据集,以近似底层的全局数据分布,并与所有客户端共享,以缓解本地数据的异构性问题。最近提出的数据蒸馏可以通过生成经过压缩且安全的小数据集,以更好地近似原始数据集,从而更好地解决联邦学习中的数据异质性问题。
技术实现思路
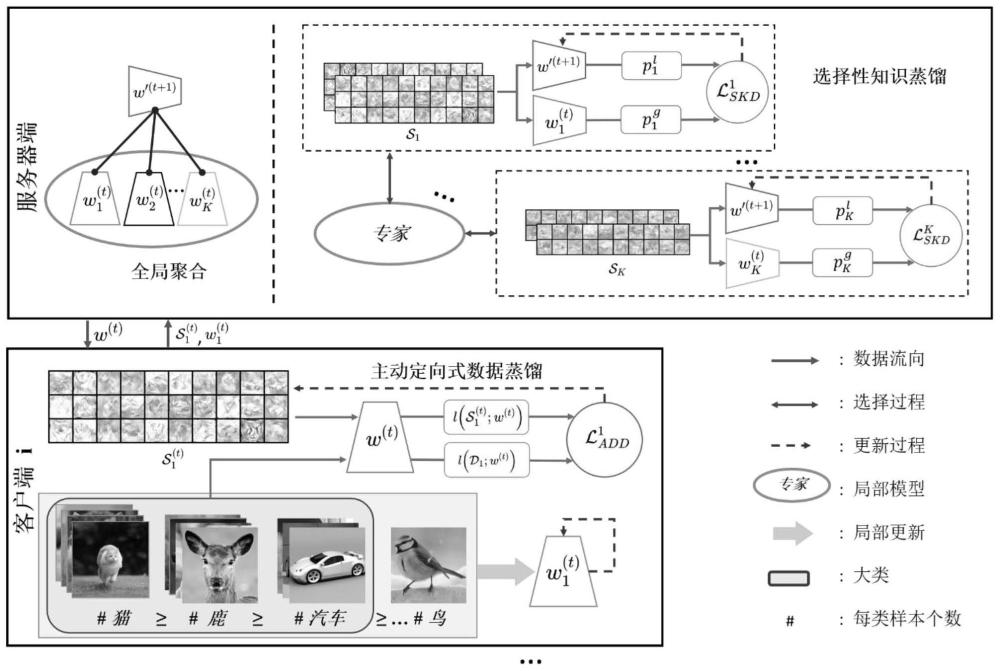
1、本发明的目的是设计一种主动定向式数据蒸馏的联邦学习方法、装置及系统,遵循联邦学习中常用的迭代局部训练和全局聚合范式。在局部训练过程中,除了训练局部模型外,每个客户端还进行数据蒸馏,利用全局模型进行梯度匹配得到蒸馏的数据,这使得全局模型能够主动地从每个局部数据集中蒸馏关键信息。为了保护数据隐私,每个客户端在本地保留蒸馏完的数据标签,并与服务器共享本地模型和蒸馏数据。因此,服务器上的蒸馏数据是未标记的。为了利用无标签的蒸馏数据,设计了一个选择性的知识蒸馏。在全局聚合阶段,服务器首先聚合所有接收到的局部模型以获得中间全局模型,然后,由于局部模型偏向于与其对应的同一个客户端生成的蒸馏数据(即,局部模型在不同的蒸馏数据上的表现不同),服务器将特定的局部模型识别匹配相应的蒸馏数据的专家。最后,通过将全局模型的输出与配对专家的输出进行对齐来优化中间全局模型,有效改善全局模型因数据异质性性能下降问题。
2、本发明的技术方案,包括:
3、一种主动定向式数据蒸馏的联邦学习方法,应用于一客户端k,所述方法包括:
4、从服务器获取全局模型w(t)的当前参数,t为当前通信轮数;
5、判断当前通信轮数t是否大于一设定的早期通信轮数t′;
6、在t≤t′的情况下,基于本地数据集优化全局模型w(t),并利用全局模型w(t)对本地数据集进行蒸馏后,将得到的局部模型和蒸馏数据返回至服务器,以使该服务器基于所有客户端返回的所述局部模型和所述蒸馏数据生成全局模型w(t+1);
7、在t>t′的情况下,基于本地数据集优化全局模型后,将得到的局部模型返回至服务器,以使该服务器基于所有客户端返回的所述局部模型生成全局模型w(t+1)。
8、进一步地,所述利用全局模型w(t)对本地数据集进行蒸馏,包括:
9、依据本地数据集的多数类,生成蒸馏数据的初始集;
10、判断局部蒸馏次数j是否大于设定的数据蒸馏迭代次数eadd;
11、在j≤tadd的情况下,使用全局模型w(t)计算蒸馏数据和真实数据的交叉熵损失,且基于蒸馏数据和真实数据的交叉熵损失之间的距离,计算局部主动定向式数据蒸馏损失后,根据所述局部主动定向式数据蒸馏损失对蒸馏数据求梯度进行优化蒸馏数据,并令j=j+1后,返回至所述判断局部蒸馏次数j是否大于设定的数据蒸馏迭代次数eadd;
12、在j>eadd的情况下,得到当前通信轮数t的蒸馏数据
13、依据蒸馏数据进行数据更新,得到蒸馏数据
14、进一步地,所述生成蒸馏数据的初始集,包括:
15、基于标准正态分布的随机噪声,生成蒸馏数据的初始集;
16、或,
17、从本地数据集随机选择,得到蒸馏数据的初始集。
18、进一步地,所述局部主动定向式数据蒸馏损失其中,ck为本地数据集的多数类,d表示余弦相似度计算,l表示交叉熵损失,表示交叉熵损失过程中的梯度,表示第c个多数类对应的蒸馏数据,表示本地数据集中第c个多数类对应的数据。
19、进一步地,所述该服务器基于所有客户端返回的所述局部模型和所述蒸馏数据生成全局模型w(t+1),包括:
20、聚合所有客户端返回的所述局部模型得到全局模型
21、判断全局蒸馏次数i是否大于设定的选择性知识蒸馏迭代次数eskd;
22、在i≤eskd的情况下,根据所述蒸馏数据计算局部模型中的领域知识后,基于将不同局部模型中的领域知识迁移到全局模型所对应的损失更新全局模型并令i=i+1之后,返回至所述判断全局蒸馏次数i是否大于设定的选择性知识蒸馏迭代次数eskd;
23、在i>eskd的情况下,令全局模型
24、进一步地,根据所述蒸馏数据计算局部模型中的领域知识后,基于将不同局部模型中的领域知识迁移到全局模型所对应的领域知识迁移损失更新全局模型包括:
25、将蒸馏数据传播到相应的局部模型以得到局部领域知识
26、将蒸馏数据传播到全局模型以得到全局领域知识
27、计算领域知识迁移损失kl为kullback-leibler散度,k表示客户端的总数量;
28、根据知识蒸馏损失对全局模型进行优化。
29、一种主动定向式数据蒸馏的联邦学习装置,应用于一客户端k,所述装置包括:
30、通信轮次判断模块,用于从服务器获取全局模型w(t)的当前参数,t为当前通信轮数;判断当前通信轮数t是否大于一设定的早期通信轮数t′;
31、第一更新模块,用于在t≤t′的情况下,基于本地数据集优化全局模型w(t),并利用全局模型w(t)对本地数据集进行蒸馏后,将得到的局部模型和蒸馏数据返回至服务器,以使该服务器基于所有客户端返回的所述局部模型和所述蒸馏数据生成全局模型w(t+1);
32、第二更新模块,在t>t′的情况下,基于本地数据集优化全局模型后,将得到的局部模型返回至服务器,以使该服务器基于所有客户端返回的所述局部模型生成全局模型w(t+1)。
33、一种主动定向式数据蒸馏的联邦学习系统,所述系统包括:一服务器和若干个客户端k;其中,任一所述客户端k用于:
34、从服务器获取全局模型w(t)的当前参数,t为当前通信轮数;判断当前通信轮数t是否大于一设定的早期通信轮数t′;
35、在t≤t′的情况下,基于本地数据集优化全局模型w(t),并利用全局模型w(t)对本地数据集进行蒸馏后,将得到的局部模型和蒸馏数据返回至服务器,以使该服务器基于所有客户端返回的所述局部模型和所述蒸馏数据生成全局模型w(t+1);
36、在t>t′的情况下,基于本地数据集优化全局模型后,将得到的局部模型返回至服务器,以使该服务器基于所有客户端返回的所述局部模型生成全局模型w(t+1)。
37、一种计算机设备,所述计算机设备包括:处理器以及存储有计算机程序指令的存储器;所述处理器执行所述计算机程序指令时实现上述任一项所述的主动定向式数据蒸馏的联邦学习方法。
38、一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述任一项所述的主动定向式数据蒸馏的联邦学习方法。
39、与现有方法相比,本发明能够实现主动的信息提取,利用梯度匹配从本地数据集中蒸馏必要的信息。随着全局模型通过增加通信轮数进行优化,本发明关注具有大梯度的数据实例。因此,在不同的通信轮中蒸馏的数据会有很大的差异。其次,主动蒸馏的数据有利于全局模型的训练,因此本发明的方法可以更快地收敛,得到更好的结果。另外,本发明的方案更加安全,与其他直接使用蒸馏数据及其标签微调全局模型的方法不同,本发明不会泄漏蒸馏数据的标签。实验表明,本发明在多种异构数据设置下的数据集上,本发明的发明能够显著提升性能。
- 还没有人留言评论。精彩留言会获得点赞!