基于分布式文件自动并行处理方法及装置与流程
本发明涉及数据处理,具体而言,涉及基于分布式文件自动并行处理方法及装置。
背景技术:
1、自动驾驶的算法和模块是数据驱动的,对于数据的需求,首先是数据量要大,同时数据多样性要丰富,源源不断的数据需要合理有效的方法去利用,推动自动驾驶模型迭代升级。这是一个长尾工程,为充分发挥算法的优势,优化自动驾驶模型,需要收集、分析和处理更多新场景的数据进行投喂,打通数据采集、数据挖掘、数据标注、模型训练和车端部署评测流程的全流程,使之进行高效流转,是自动驾驶核心力的关键。通过预设流程自动发起条件,对采集的海量文件通过并行的方式加速数据执行,能大大提高数据处理的效率,加快数据在全流程的流转应用。
2、相关技术中,在执行数据处理工作流的过程中,通过建立多个级别的分级数据缓冲区,进行数据读取或写入,但这种方法仍有部分不足:海量数据写入缓冲区耗时,数据来源渠道多样化、数据量大,构建缓冲区模块耗时较长,无法实现及时数据处理,同时缺少数据源条件配置,无法响应业务侧动态配置自动化任务的需求,也缺少自动化任务调度策略,因此,亟需一种低成本可扩展性高的并行处理方法,满足各个算法场景的数据处理需求,实现海量数据的快速流转,为自动驾驶快速迭代提供数据的支持。
3、针对相关技术中存在的上述问题,暂未发现高效且准确的解决方案。
技术实现思路
1、本发明提供了一种基于分布式文件自动并行处理方法及装置、存储介质、电子装置,以解决相关技术中存在的上述技术问题。
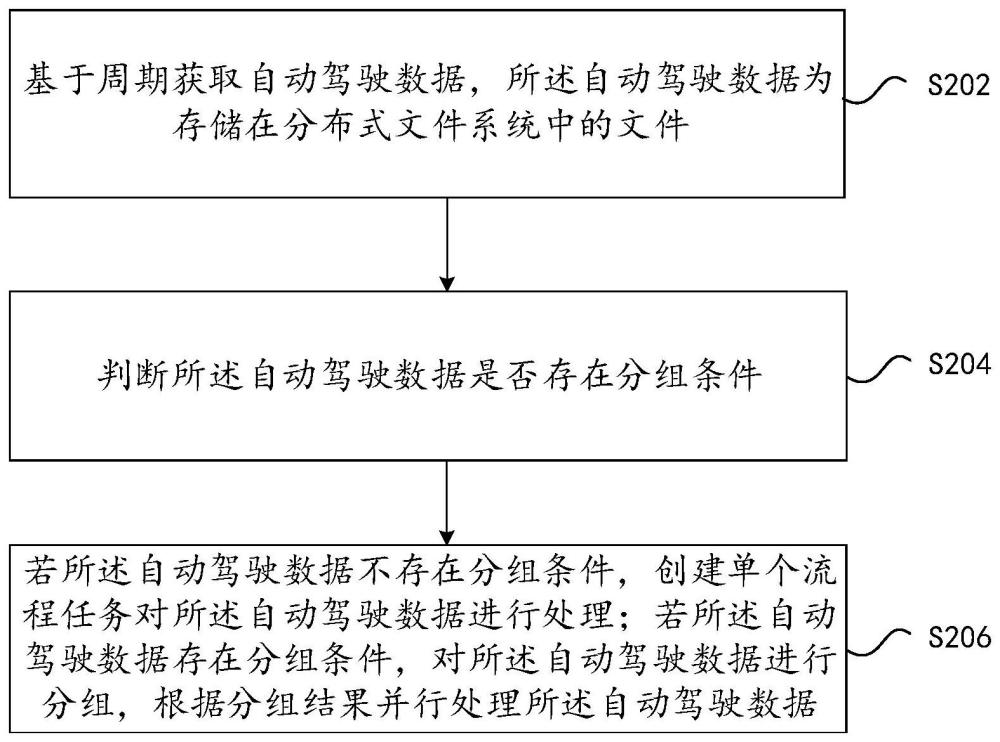
2、根据本发明的一个实施例,提供了一种基于分布式文件自动并行处理方法,其特征在于,包括:基于周期获取自动驾驶数据,所述自动驾驶数据为存储在分布式文件系统中的文件;判断所述自动驾驶数据是否存在分组条件;若所述自动驾驶数据不存在分组条件,创建单个流程任务对所述自动驾驶数据进行处理;若所述自动驾驶数据存在分组条件,对所述自动驾驶数据进行分组,根据分组结果并行处理所述自动驾驶数据。
3、可选地,基于周期获取自动驾驶数据包括:确定当前执行周期;查找所述当前执行周期的上一周期任务;判断所述上一周期任务是否完成;若所述上一周期任务完成,确定开始时间为所述当前执行周期的起始时间值;若所述上一周期任务没有完成,确定开始时间为所述上一周期任务的数据截止时间;基于所述开始时间和文件查询条件在所述分布式文件系统中进行查找,得到所述自动驾驶数据。
4、可选地,基于所述开始时间和文件查询条件在所述分布式文件系统中进行查找,得到所述自动驾驶数据,包括:基于所述开始时间遍历查找所述分布式文件系统中的所有文件;判断遍历到的目标文件是否满足所述文件查询条件,以及判断所述目标文件的入库时间是否在预设时间范围内;若遍历到的目标文件满足所述文件查询条件,且所述目标文件的入库时间在预设时间范围内,将所述目标文件添加至自动驾驶数据;若遍历到的目标文件不满足所述文件查询条件,或所述目标文件的入库时间不在预设时间范围内,忽略所述目标文件。
5、可选地,对所述自动驾驶数据进行分组包括:解析所述自动驾驶数据中的车辆编码;基于所述车辆编码对所述自动驾驶数据分组,得到多组自动驾驶数据,其中,每组自动驾驶数据对应同一个车辆编码。
6、可选地,对所述自动驾驶数据进行分组包括:判断所述自动驾驶数据的数据量是否小于单次任务数据量阈值;若所述自动驾驶数据的数据量大于或等于所述单次任务数据量阈值,以所述单次任务数据量阈值为单位步长按照时序截取所述自动驾驶数据,直到剩余的数据量小于所述单次任务数据量阈值,得到多组自动驾驶数据。
7、可选地,根据分组结果并行处理所述自动驾驶数据包括:针对所述分组结果的每组自动驾驶数据,创建一个流程任务;判断所述流程任务数是否大于预设并行数;若所述流程任务数小于或等于预设并行数,对所述流程任务并行处理;若所述流程任务数大于预设并行数,对m个所述流程任务进行并行处理,并对剩余的a-m个所述流程任务进行排队并行处理,其中所述a为所述流程任务数,所述m为所述预设并行数。
8、可选地,对剩余的a-m个所述流程任务进行排队并行处理包括:对所述m个所述流程任务进行监测,判断当前并行处理数目是否小于m;若所述并行处理数目小于m,从所述a-m个所述流程任务中选择m-b个流程任务,并将所述m-b个流程任务加入并行处理,其中所述b为当前剩余的并行处理数目。
9、根据本发明的另一个实施例,提供了一种基于分布式文件自动并行处理装置,包括:获取模块,用于基于周期获取自动驾驶数据,所述自动驾驶数据为存储在分布式文件系统中的文件;判断模块,用于判断所述自动驾驶数据是否存在分组条件;处理模块,用于若所述自动驾驶数据不存在分组条件,创建单个流程任务对所述自动驾驶数据进行处理;若所述自动驾驶数据存在分组条件,对所述自动驾驶数据进行分组,根据分组结果并行处理所述自动驾驶数据。
10、可选地,所述获取模块包括:确认单元,用于确定当前执行周期;查找单元,用于查找所述当前执行周期的上一周期任务;判断单元,用于判断所述上一周期任务是否完成;确定单元,用于若所述上一周期任务完成,确定开始时间为所述当前执行周期的起始时间值;若所述上一周期任务没有完成,确定开始时间为所述上一周期任务的数据截止时间;查找单元,用于基于所述开始时间和文件查询条件在所述分布式文件系统中进行查找,得到所述自动驾驶数据。
11、可选地,所述查找单元包括:查找子单元,用于基于所述开始时间遍历查找所述分布式文件系统中的所有文件;判断子单元,用于判断遍历到的目标文件是否满足所述文件查询条件,以及判断所述目标文件的入库时间是否在预设时间范围内;处理子单元,用于若遍历到的目标文件满足所述文件查询条件,且所述目标文件的入库时间在预设时间范围内,将所述目标文件添加至自动驾驶数据;若遍历到的目标文件不满足所述文件查询条件,或所述目标文件的入库时间不在预设时间范围内,忽略所述目标文件。
12、可选地,所述处理模块包括:解析单元,用于解析所述自动驾驶数据中的车辆编码;分组单元,用于基于所述车辆编码对所述自动驾驶数据分组,得到多组自动驾驶数据,其中,每组自动驾驶数据对应同一个车辆编码。
13、可选地,所述处理模块还包括:判断单元,用于判断所述自动驾驶数据的数据量是否小于单次任务数据量阈值;截取单元,用于若所述自动驾驶数据的数据量大于或等于所述单次任务数据量阈值,以所述单次任务数据量阈值为单位步长按照时序截取所述自动驾驶数据,直到剩余的数据量小于所述单次任务数据量阈值,得到多组自动驾驶数据。
14、可选地,所述处理模块还包括:创建单元,用于针对所述分组结果的每组自动驾驶数据,创建一个流程任务;判断单元,用于判断所述流程任务数是否大于预设并行数;处理单元,用于若所述流程任务数小于或等于预设并行数,对所述流程任务并行处理;若所述流程任务数大于预设并行数,对m个所述流程任务进行并行处理,并对剩余的a-m个所述流程任务进行排队并行处理,其中所述a为所述流程任务数,所述m为所述预设并行数。
15、可选地,所述处理单元包括:监测子单元,用于对所述m个所述流程任务进行监测,判断当前并行处理数目是否小于m;处理子单元,用于若所述并行处理数目小于m,从所述a-m个所述流程任务中选择m-b个流程任务,并将所述m-b个流程任务加入并行处理,其中所述b为当前剩余的并行处理数目。
16、根据本发明的又一个实施例,还提供了一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述任一项装置实施例中的步骤。
17、根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项装置实施例中的步骤。
18、本发明的有益效果:
19、1、通过设置周期获取自动驾驶数据,对分布式存储的自动驾驶数据分组并行处理,解决了相关技术中数据处理工作时间过长的技术问题。
20、2、极大的提升了数据流转的效率,满足各个算法场景的数据处理需求,为自动驾驶快速迭代提供数据的支持;
21、3、采用云端中的工作流引擎,无额外软件、硬件成本投入,节省人力物力。
- 还没有人留言评论。精彩留言会获得点赞!