基于污水检测的磁混凝高效沉淀池污水处理系统的制作方法
本发明涉及数据处理领域,具体涉及基于污水检测的磁混凝高效沉淀池污水处理系统。
背景技术:
1、在磁混凝高效沉淀池污水处理系统中,往往需要对温度数据进行异常检测,而常用的一种异常检测算法为孤立森林算法。该算法不借助类似距离、密度等指标去描述样本与其它样本的差异,而是直接刻画所谓的梳理程度。而该算法中样本集的数量(孤立树的个数)往往是固定的,这会导致对于不同数据分布特征的数据段进行孤立森林异常检测时会出现不同的问题,进而影响算法的有效性,影响磁混凝高效沉淀池污水处理系统的效率。
2、在现有技术中,孤立森林算法中对样本数据中的数据分布本身就有一定的要求,例如对于较为平滑的数据段,如果再进行固定的个数的孤立树的建立是没有必要的,会导致算法的计算量大;对于变化剧烈的数据段,其中异常数据可能较多,那么就需要更多的孤立树来精确计算其异常得分值。同时由于系统中有一些温度变化为正常现象,但传统算法中基于数据大小作为特征值的孤立树建立方法在当前场景中不适用。
3、针对上述问题,本发明提出了基于污水检测的磁混凝高效沉淀池污水处理系统。首先通过采集到的各个位置的温度数据之间的规律性计算出一个沉淀区温度评估值,可用于构建孤立数的特征值,并且依据样本集中的温度评估值自适应确定样本集的数量,从而有效提高系统效率。
技术实现思路
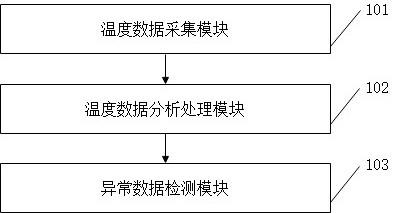
1、为了解决上述问题,本发明提供基于污水检测的磁混凝高效沉淀池污水处理系统,所述系统包括:
2、温度数据采集模块,用于采集磁混凝高效沉淀区不同位置处的温度数据;
3、温度数据分析处理模块,用于对各个位置处的温度数据进行分段,获得每一个位置温度数据的多个数据区间;获得每个数据区间中每个数据点的数据变化区间,根据数据变化区间两个端点数据获得正常温度数据参考值;根据数据变化区间的数据变化与正常温度数据参考值获得每个数据点的温度变化程度;根据温度变化程度获得每个数据点的第一温度评估值;对第一温度评估值进行阈值化处理获得各个位置的温度数据中各数据点的第二温度评估值;根据每个数据点的第二温度评估值获得每个数据区间调整后的样本数量;
4、异常数据检测模块,用于根据每个数据区间调整后的样本数量,通过孤立森林算法,获得异常数据。
5、进一步的,所述对各个位置处的温度数据进行分段,获得每一个位置温度数据的多个数据区间,包括的步骤为:
6、将各个位置处的温度数据按照预设时间长度进行数据区间的划分,获得各个位置处的温度数据的多个数据区间。
7、进一步的,所述获得每个数据区间中每个数据点的数据变化区间,根据数据变化区间两个端点数据获得正常温度数据参考值,包括的步骤为:
8、将每个数据区间中的任意一个数据点记为当前数据点,以当前数据点为中心,向数据点的两端进行延伸,延伸的到导数为0的数据点截止,由延伸的数据点构成当前数据点的数据变化区间,然后获得数据区间中每个数据点的数据变化区间;根据数据变化区间两个端点数据获得正常温度数据的参考值。
9、进一步的,所述根据数据变化区间两个端点数据获得正常温度数据的参考值,将该值记为获得正常温度数据的参考值,包括的步骤为:
10、
11、式中,表示第个温度数据中第个数据区间中第个数据点所在数据变化区间的两个端点数据的第一均值,表示第个温度数据中第个数据区间中第个数据点的数据变化区间中左侧端点数据的温度值, 表示第个温度数据中第个数据区间中第个数据点的数据变化区间中右侧端点数据的温度值;
12、然后获得所有数据点所在的数据区间的两个端点数据的均值,求所有数据点所在的数据区间的两个端点数据的第一均值的均值,并作为正常温度数据的参考值。
13、进一步的,所述根据数据变化区间的数据变化与正常温度数据参考值获得每个数据点的温度变化程度,包括的步骤为:
14、
15、式中,表示第个温度数据中第个数据区间中第个数据点的温度变化程度, 表示第个温度数据中第个数据区间中第个数据点的数据变化区间中第个数据点的温度值,表示第个温度数据中第个数据区间中第个数据点所在数据变化区间的两个端点数据的第一均值,数据变化区间记为,表示数据变化区间的左端点的时间点,表示数据变化区间的右端点的时间点,表示数据变化区间的区间长度。
16、进一步的,所述根据温度变化程度获得每个数据点的温度评估值,包括的步骤为:
17、将第个温度数据中第个数据区间中第个数据点的温度变化程度记为,将第个温度数据中第个数据区间中第个数据点的温度变化程度记为,将第个温度数据中第个数据区间起始时间点记为,将第个温度数据中第个数据区间的起始时间点记为,根据与的差值、与的差值以及第个温度数据中第个数据区间的方差获得第个温度数据中第个数据区间中第个数据点的第一温度评估值。
18、进一步的,所述根据与的差值、与的差值以及第个温度数据中第个数据区间的方差获得第个温度数据中第个数据区间中第个数据点的第一温度评估值,包括的步骤为:
19、
20、式中,表示第个温度数据中第个数据区间中第个数据点的第一温度评估值,表示第个温度数据中第个数据区间的方差,表示线性归一化函数。
21、进一步的,所述获得各个位置的温度数据中各数据点的温度评估值,包括的步骤为:
22、
23、式中,表示第个温度数据中第个数据区间中第个数据点的第二温度评估值,表示第个温度数据中第个数据区间中第个数据点的第一温度评估值,表示第个温度数据中第个数据区间中第个数据点的左右邻域各五个数据点的导数的均值,表示预设阈值。
24、进一步的,所述根据每个数据点的温度评估值获得每个数据区间调整后的样本数量,包括的步骤为:
25、
26、式中,表示第个温度数据中第个数据区间调整后的样本数量,表示第个温度数据中第个数据区间中所有数据点的温度评估值的方差,10为放大系数。
27、进一步的,所述根据每个数据区间调整后的样本数量,通过孤立森林算法,获得异常数据,包括的步骤为:
28、根据确定的每个温度数据中每个数据区间的样本数量,然后采用温度评估值作为孤立树建立的特征值进行孤立森林算法的异常检测得到异常得分值,当异常得分值时,为预设阈值,则标记该数据区间内的温度数据为异常数据。
29、本发明具有如下有益效果:在通过孤立森林算法对磁混凝高效沉淀池的温度数据进行异常监测时,因为样本集中所包含的数据点的数量关系到对温度数据判断的准确性,因此本发明根据不同监测位置处的温度数据的变化来自适应确定样本集的数量,从而使得对温度数据的监测更加的准确。
30、并且发明能够通过将沉淀区多个位置的温度数据之间的联系考虑其整体温度即温度评估值,避免了采用单个维度温度数据的假异常情况造成的偏差,使得异常检测更加准确。能够通过分析进行孤立树建立是的样本集中数据的分布情况确定样本集的数量,相较于传统的孤立森林算法中固定样本集的数量的方法,可以在有效减小算法计算量的同时提高算法的准确性及效率,进而提高基于污水检测的磁混凝高效沉淀池污水处理系统的效率。
- 还没有人留言评论。精彩留言会获得点赞!