一种基于驱动文本生成数字人的播报视频的方法及装置与流程
本技术实施例涉及人工智能,尤其涉及一种基于驱动文本生成数字人的播报视频的方法及装置。
背景技术:
1、随着元宇宙、虚拟现实、虚拟数字人等概念的兴起和人工智能技术的蓬勃发展,虚拟数字人已被应用于语音播报、新闻播报、客服介绍等相关领域。在语音驱动技术方面,已有的技术包括传统的基于语言学的模型或基于神经网络的模型实现,虽然这些技术已经取得了一定的进展,但仍然存在一些挑战,例如:有一部分现有技术是先采集生物对象发出的音频数据,对音频数据进行特征提取,得到音频数据的多模态特征,基于多模态特征,生成生物对象的目标动作数据,基于目标动作数据驱动生物对象对应的虚拟形象,这种方式需要采集真实、具有情感的语音数据,制作周期比较长、人工代价相对较大;另一部分现有技术的虚拟人唇形驱动过程只考虑了口型与文本的同步性,并未研究虚拟人的情绪表情与驱动文本的一致性,并且其使用到的语音合成技术并未考虑驱动文本中的情感因素,故其所生成的语音是类播音音调,与具有真实情感的人声存在差异、真实性较差。
技术实现思路
1、本技术实施例提供一种基于驱动文本生成数字人的播报视频的方法及装置,以解决相关技术中文本驱动数字人播报时,未考虑到文本的情感信息、导致最终播报视频时,播放效果的真实性较差、缺乏感染力的技术问题。
2、为解决上述技术问题,本技术实施例提供如下几个方面:
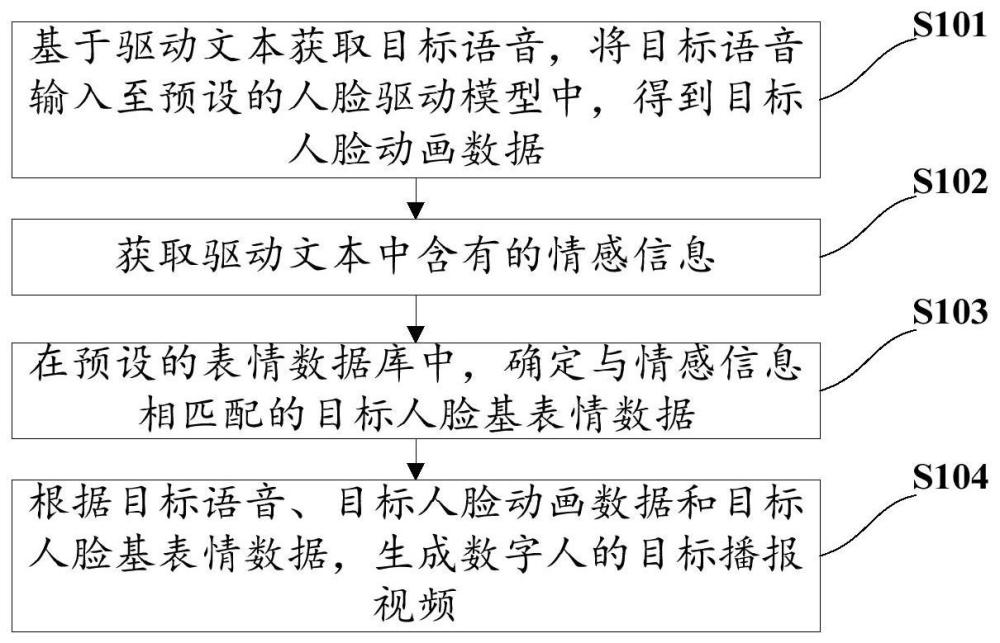
3、第一方面,本技术实施例提供一种基于驱动文本生成数字人的播报视频的方法,所述方法包括:
4、基于驱动文本获取目标语音,将所述目标语音输入至预设的人脸驱动模型中,得到目标人脸动画数据;其中,所述目标语音能够表达所述驱动文本所含有的情感信息;
5、获取所述驱动文本中含有的情感信息;
6、在预设的表情数据库中,确定与所述情感信息相匹配的目标人脸基表情数据;
7、根据所述目标语音、所述目标人脸动画数据和所述目标人脸基表情数据,生成数字人的目标播报视频。
8、可选的,基于驱动文本获取目标语音包括:
9、获取所述驱动文本的音素序列特征向量以及位置特征向量;
10、将所述音素序列特征向量和所述位置特征向量进行拼接融合,得到音素位置特征向量;
11、对所述驱动文本进行上下文特征提取,得到上下文特征向量;
12、对所述音素位置特征向量和所述上下文特征向量进行特征处理,得到增强特征向量;
13、对所述增强特征向量进行解码,得到梅尔频谱;
14、基于所述梅尔频谱和声码器,生成所述目标语音。
15、可选的,获取所述驱动文本中含有的情感信息包括:
16、将所述驱动文本输入至预设的情感分析模型中,得到所述驱动文本中含有的情感信息;
17、在将所述驱动文本输入至预设的情感分析模型中,得到所述驱动文本中含有的情感信息之前,所述方法还包括:
18、将源领域的文本语料集和目标领域的文本语料集输入到隐含狄利克雷分布lda模型中,得到所述源领域所对应的源领域第一主题特征和所述目标领域所对应的目标领域第一主题特征;
19、计算所述源领域第一主题特征与所述目标领域第一主题特征之间的信息量和信息损失量;
20、基于所述信息量和所述信息损失量对所述lda模型进行优化,其中,优化后的所述lda模型更加适应所述目标领域的数据分布;
21、将所述源领域的文本语料集和所述目标领域的文本语料集重新输入到优化后的所述lda模型中,得到所述源领域所对应的源领域第二主题特征和所述目标领域所对应的目标领域第二主题特征;
22、将所述源领域的文本语料集输入双向编码表征模型bert模型中,得到所述源领域的语义特征;
23、将所述语义特征、所述源领域第二主题特征以及所述目标领域第二主题特征相结合,生成词向量矩阵;
24、基于所述词向量矩阵对预先设置的情感分类器进行训练,得到所述情感分析模型。
25、可选的,在预设的表情数据库中,确定与所述情感信息相匹配的目标人脸基表情数据之前,所述方法还包括:
26、建立所述表情数据库,其中包括:
27、获取用于模型训练的文本语料集以及与所述文本语料集中的每条文本语料一一对应的情绪标签;
28、根据所述情绪标签生成与所述情绪标签对应的人脸表情数据;
29、将所述人脸表情数据存储在数据库中,将所述数据库确定为所述表情数据库。
30、可选的,在将所述目标语音输入至预设的人脸驱动模型中,得到目标人脸动画数据之前,所述方法还包括:
31、基于语音数据集和人脸模型数据集对深度学习网络模型进行训练,得到所述人脸驱动模型;
32、其中,所述语音数据集中的每条语音与所述人脸模型数据集中的每个人脸模型数据是一一对应关系。
33、可选的,根据所述目标语音、所述目标人脸动画数据和所述目标人脸基表情数据,生成数字人的目标播报视频包括:
34、将所述目标人脸表情数据作为基表情数据;
35、以所述目标语音为参照标准,将所述基表情数据与所述目标人脸动画数据进行融合渲染,得到与所述目标语音相匹配的口型动画以及与所述情感信息相匹配的脸部表情;
36、将所述口型动画、所述脸部表情以及所述目标语音进行合成,得到所述目标播报视频。
37、第二方面,本技术实施例提供一种基于驱动文本生成数字人的播报视频的装置,所述装置包括:
38、第一生成模块,用于基于驱动文本获取目标语音,将所述目标语音输入至预设的人脸驱动模型中,得到目标人脸动画数据;其中,所述目标语音能够表达所述驱动文本所含有的情感信息;
39、获取模块,用于获取所述驱动文本中含有的情感信息;
40、确定模块,用于在预设的表情数据库中,确定与所述情感信息相匹配的目标人脸基表情数据;
41、第二生成模块,用于根据所述目标语音、所述目标人脸动画数据和所述目标人脸基表情数据,生成数字人的目标播报视频。
42、可选的,所述第一生成模块,还用于获取所述驱动文本的音素序列特征向量以及位置特征向量;
43、将所述音素序列特征向量和所述位置特征向量进行拼接融合,得到音素位置特征向量;
44、对所述驱动文本进行上下文特征提取,得到上下文特征向量;
45、对所述音素位置特征向量和所述上下文特征向量进行特征处理,得到增强特征向量;
46、对所述增强特征向量进行解码,得到梅尔频谱;
47、基于所述梅尔频谱和声码器,生成所述目标语音。
48、可选的,所述获取模块,还用于将所述驱动文本输入至预设的情感分析模型中,得到所述驱动文本中含有的情感信息;
49、所述装置还包括:
50、第二确定模块,用于在将所述驱动文本输入至预设的情感分析模型中,得到所述驱动文本中所含有的情感信息之前,将源领域的文本语料集和目标领域的文本语料集输入到隐含狄利克雷分布lda模型中,得到所述源领域所对应的源领域第一主题特征和所述目标领域所对应的目标领域第一主题特征;
51、计算模块,用于计算所述源领域第一主题特征与所述目标领域第一主题特征之间的信息量和信息损失量;
52、模型优化模块,用于基于所述信息量和所述信息损失量对所述lda模型进行优化,其中,优化后的所述lda模型更加适应所述目标领域的数据分布;
53、所述第二确定模块,还用于将所述源领域的文本语料集和所述目标领域的文本语料集重新输入到优化后的所述lda模型中,得到所述源领域所对应的源领域第二主题特征和所述目标领域所对应的目标领域第二主题特征;
54、第三确定模块,用于将所述源领域的文本语料集输入双向编码表征模型bert模型中,得到所述源领域的语义特征;
55、第三生成模块,用于将所述语义特征、所述源领域第二主题特征以及所述目标领域第二主题特征相结合,生成词向量矩阵;
56、第四确定模块,用于基于所述词向量矩阵对预先设置的情感分类器进行训练,得到所述情感分析模型。
57、可选的,所述装置还包括:
58、建立模块,用于在预设的表情数据库中,确定与所述情感信息相匹配的目标人脸基表情数据之前,建立所述表情数据库,其中包括:获取用于模型训练的文本语料集以及与所述文本语料集中的每条文本语料一一对应的情绪标签;根据所述情绪标签生成与所述情绪标签对应的人脸表情数据;将所述人脸表情数据存储在数据库中,将所述数据库确定为所述表情数据库。
59、可选的,所述装置还包括:
60、第五确定模块,用于在将所述目标语音输入至预设的人脸驱动模型中,得到目标人脸动画数据之前,基于语音数据集和人脸模型数据集对深度学习网络模型进行训练,得到所述人脸驱动模型;
61、其中,所述语音数据集中的每条语音与所述人脸模型数据集中的每个人脸模型数据是一一对应关系。
62、可选的,所述第二生成模块,用于将所述目标人脸表情数据作为基表情数据;以所述目标语音为参照标准,将所述基表情数据与所述目标人脸动画数据进行融合渲染,得到与所述目标语音相匹配的口型动画以及与所述情感信息相匹配的脸部表情;将所述口型动画、所述脸部表情以及所述目标语音进行合成,得到所述目标播报视频。
63、第三方面,本技术实施例提供一种电子设备,包括:处理器、存储器及存储在所述存储器上并可在所述处理器上运行的程序,所述程序被所述处理器执行时实现如第一方面所述的基于驱动文本生成数字人的播报视频的方法的步骤。
64、第四方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述的基于驱动文本生成数字人的播报视频的方法的步骤。
65、由此,本技术首先基于驱动文本获取目标语音,然后将驱动文本进行情感分析并获取情感标签对应的人脸模型数据,将目标语音通过人脸驱动模型生成人脸动画数据,将该人脸动画数据和基于驱动文本情感分析获取到的人脸模型数据以及目标语音相融合,最终生成与驱动文本情绪情感风格相一致的人脸动画。与相关技术相比,具备如下优点:充分利用了驱动文本的情绪情感信息,以进行后续的目标语音、目标人脸动画数据以及目标人脸基表情数据的生成,并融合这几个参数生成数字人的播报视频,由此,可生成丰富的人脸动画,虚拟数字人的表情可更加真实和流畅,从而提升虚拟数字人的真实感和情感表达效果,实现丰富的虚拟数字人的情感表达,提升其真实感和表现力。
- 还没有人留言评论。精彩留言会获得点赞!