一种基于图计算的证券价格趋势预测方法与流程
本发明为一种基于图计算的证券价格趋势预测方法。
背景技术:
1、证券价格趋势预测是指根据某一证券产品的历史信息(如收盘价、成交量等)来预测其未来交易价格相比于基准价格的变化趋势。其中,基准价格的选取并不固定,当日收盘价、多日均价、多日中最高价均可作为基准。由于该问题的挑战性及潜在的经济价值,目前已存在一些流行的技术或方法,具体介绍如下。
2、基于统计模型的证券价格趋势预测方法
3、该方法以统计模型为核心,首先依照严格的数学推导及条件假设构造多参数的数学模型,进而通过拟合证券历史数据来确定模型参数。例如,差分整合移动平均自回归模型(autoregressive integrated moving average model,arima)是常用的模型之一,该模型将待预测序列假定为平稳序列(即序列值围绕其均值上下波动,无大范围变化),通过估计序列的自相关系数和偏相关系数来确定模型参数,并拟合待预测序列的走势。
4、统计模型具有1)参数少,形式以标量为主;2)以拟合参数间的线性关系为主;3)具有较多条件假设3种主要缺陷,上述缺陷使得统计模型难以多维数据间的非线性关系,并难以处理时间跨度过长或噪声过多的数据,因此在证券价格趋势预测任务上通常表现不足。
5、基于机器学习模型的证券价格趋势预测方法
6、近年来机器学习模型被广泛应用于证券价格趋势的预测,而随着算力的增强和数据的丰富,其中的深度学习模型成为了当前证券预测所依赖的主流模型。其中,由于证券数据的时序性,长短期记忆模型(long short-term memory,lstm)等序列模型的应用最为广泛相比于统计模型,深度学习模型对序列没有线性、平稳性的假设,从而能很好地拟合多维数据间非线性关系并抵抗数据中噪音的干扰,同时,深度学习模型的数据利用量更大且不依赖复杂的人工特征构造,能够覆盖多场景、多时间跨度。因此,深度学习模型具有更高的预测性能和更好的泛化能力。
7、机器学习模型一般将数据组织为向量来作为输入,而这种数据组织方式可能丢失了数据间的结构关系。在证券价格趋势预测中,h日的证券数据常被组织为形如的向量形式,其中是证券在t时刻的数据。由于lstm等时序模型按照序列顺序来处理数据,因而此类模型只能利用数据间的单向关系,即只考虑了t时刻数据对t+1时刻数据的影响。然而,现实场景下证券在不同时刻的数据可以相互影响,交易者完全可以依据t时刻的数据来在t+n时刻作出决策,从而影响t+n时刻的证券数据。因此,证券数据间的时序关系应当遵循一种复杂的图结构而非单向的向量结构,以图的形式组织数据可以更充分地保留证券数据中蕴涵的时序关系。然而,图数据的非欧几里得性使其不能被时序模型直接处理。因此,研究者需要通过引入图神经网络,基于图计算机制来处理证券数据,从而更好地实现价格趋势预测。
技术实现思路
1、本发明的目的在于提供一种基于图计算的证券价格趋势预测方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于图计算的证券价格趋势预测方法,其特征在于:包括以下步骤:
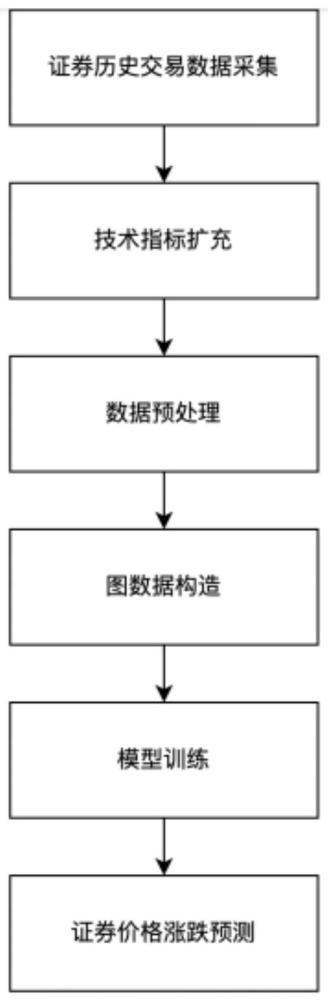
3、步骤1:获取证券数据集,该数据集包括待预测证券的历史交易数据。
4、步骤2:使用ta-lib基于历史交易数据中的证券收盘价为原始交易数据增加多种技术指标特征。
5、步骤3:对历史交易数据集进行标准化处理。
6、步骤4:将证券s在交易日t所对应样本的标签设置为:交易日t+1的收盘价相比于过去n日收盘价均值的涨跌情况。
7、步骤5:根据历史交易数据集生成图数据集。数据集中的元素代表证券s在交易日t下的交易图谱,其具体构造包括如下步骤:
8、步骤5-1:从交易日t开始,依次向前读取n-1个交易日的数据。当读取第t-i个交易日的数据时(0≤i≤n-1),在节点列表中增加元素i以表示图谱中的第i号节点,并将该日交易数据添加到节点特征列表node_feaure_list中。若该日数据不存在,则设置为零向量。
9、步骤5-2:遍历node_list中所有的元素组合(i,j),若元素i与元素j满足:|i-j|≤i,其中i为最大允许间隔,则在拓扑结构列表topo_list中增加元素[i,j]与[j,i],即表示i号节点与j号节点间存在双向边。同时,在边关系列表edge_list中增加元素[i,j,]与[j,i,],其中代表节点间的边类型,满足式(1)
10、
11、步骤5-3:在edge_list中增加自环,即[i,i,0](0≤i≤n-1)。
12、步骤5-4:使用dgl根据topo_list、node_feature_list与edge_list生成交易图谱。
13、步骤5-5:重复步骤5-1至5-4,直到将交易历史数据集转化为图数据集。
14、所述将图数据集中的各交易图谱的节点特征转换为tensor类型。
15、一种基于图计算的证券价格趋势预测方法构造模型训练数据,具体包括如下步骤:
16、s1、从图数据集中读取数据,使用dgl的batch方法将数据打包为多个批次,一个批次包含batch_size个交易图谱。
17、s2、将交易图谱边关系列表edge_list中元素的边类型映射到非负整数域,映射前后的边关系ei,j和e′i,j满足公式(2),其中i为步骤5-2中定义的最大允许间隔
18、e′i,j=ei,j+i#(2)
19、一种基于图计算的证券价格趋势预测方法,设置训练环境,具体包括如下步骤:
20、s1、设置损失函数。
21、s2、设置训练超参数与模型超参数。
22、s3、设置学习优化器。
23、一种基于图计算的证券价格趋势预测方法设置训练环境,构造并训练模型,具体包括如下步骤:
24、s1、构造模型,并从权利要求3中的训练数据中获取交易图谱作为输入数据。
25、s2、使用torch.nn.linear在模型中增加一个线性映射层,用于将各节点特征x映射至维度为embeded_dim的节点表示向量h。其中,embeded_dim由模型超参数决定,映射公式满足式(3),其中w与b为模型自动初始化的线性映射参数。
26、h=wx+b#(3)
27、s3、使用dgl.nn.pytorch.hgtconv增加hgt_num个异质图神经网络,用于多次融合交易图谱中各节点的表示向量,其中hgt_num由模型超参数决定。设每一次融合前后节点i的表示向量为与
28、一种基于图计算的证券价格趋势预测方法,具体融合过程如下:
29、1)依次计算节点i的各邻居节点j相对节点i的注意力分数满足式(4)。其中,为注意力矩阵,其初始值与边类型ej,i有关,wk,
30、bk,wq,bq为线性映射参数,上述参数均由模型自动初始化。
31、
32、2)将各邻居节点的注意力分数归一化到[0,1]区间,得到归一化注意力分数计算公式满足(5)。其中为邻居节点构成的集合。
33、
34、3)计算各邻居节点j的信息向量mj,公式满足(6)。其中,为信息传递矩阵,其初始值与边类型ej,i有关,wv,bv为线性映射参数,上述参数均由模型自动初始化
35、
36、4)计算各邻居节点信息向量的加权向量公式满足(7)。
37、
38、5)使用更新节点i的表示向量公式满足(8),其中w与为模型自动初始化的线性映射参数
39、
40、所述经hgt_num次融合,通过图聚合算法提取交易图谱的图表示向量g
41、s1、使用torch.nn.linear和nn.softmax增加一个线性映射层和归一化层,用于将图表示向量g映射为2维概率向量,得到预测结果其中,概率向量各维度分别对应跌与涨的概率,预测结果与图表示向量的关系满足式(9),其中w与b为模型自动初始化的线性映射参数。
42、
43、s2、将模型预测结果与真实结果比较,使用权利要求4中的损失函数计算模型训练损失。
44、s3、使用权利要求4中的优化器根据模型训练损失更新模型参数。
45、s4、不断重复权利要求5-7中步骤,直到模型的训练损失收敛,则模型构建完成。
46、s5、选取待预测数据,将经权利要求1-3得到的交易图谱输入已构建模型并得到预测结果。
47、与现有技术相比,本发明的有益效果是:
48、本发明通过将交易日抽象为点、将交易日间的时序关系抽象为边,能够将证券交易数据转化为带有时序结构信息的图数据,从而起到数据增强的效果。本发明在中国a股和美股数据上取得了良好的效果,具体而言。经3.2节技术过程处理csi300以及djia30所涉及的股票在2022年的日线交易数据后进行预测,本发明在csi300上取得了75.75%的准确率,超过了最好的基准模型gat(图注意力神经网络)(73.82%);在djia30上取得了75.91%的准确率,超过了最好的基准模型lstm(71.19%)。同时,本发明在交易回测中取得了0.1702的回报率,超过了最好的基准模型lstm(0.1264)并远超0.05的市场回报率(即始终持仓下的回报率)。
- 还没有人留言评论。精彩留言会获得点赞!