一种高效准确的歧义场景文字检测方法及系统
本发明属于图像文字识别领域,具体涉及一种高效准确的歧义场景文字检测方法及系统。
背景技术:
1、歧义文字的现象经常出现在自然场景,尤其是中文场景中。它往往包含两种情况,其一为行列文本并列排布以及字符呈大间距排列。以往常规的场景文本检测器由于缺少语义信息的引入,难以处理歧义问题。现有歧义场景文本检测器首先检测出所有有可能的候选框,然后将他们输入识别模块中进行识别,随后将识别的结果送入语言模型得到语义分数。最后该方法会根据语义分数和检测模块中输出的视觉分数得到合理的检测框。该方案通过引入语义信息来解决歧义问题,然而,在实际应用中需要将所有检测出的候选框全部识别并通过语言模型,这一过程需要耗费大量的时间。同时对于某些歧义稀疏的场景而言,这种方案也显得效率极低。
2、目前的歧义文字检测器需要依赖单词识别的结果去判断某个候选框是否有语义,这一过程使得整个模型效率下降,难以在实际中应用。在实际场景中,有很多歧义稀疏的情况,当前方案在这种常规场景下仍然需要对所有检测单词进行语义判别这一过程,这也会大大降低模型的效率。当前方案需要字符框的标注以实现相对高效的字符识别过程,然而在实际场景中字符级别的标注往往是非常昂贵且难以获得的。
技术实现思路
1、本发明的目的在于提出一种高效准确的歧义文字检测方法及系统,能够高效准确地检测歧义文字,并提高识别的准确率。
2、为实现上述目的,本发明采用以下技术方案:
3、一种高效准确的歧义场景文字检测方法,包括以下步骤:
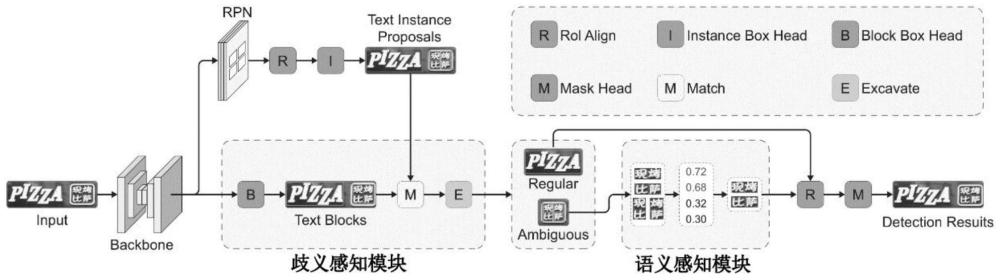
4、使用基于mask r-cnn结构的文本检测分支检测场景图像中的文本,生成文本候选框;
5、使用歧义感知模块检测场景图像的文本块,将文本块与文本候选框进行匹配及关联,分析文本块中所有文本候选框之间的连接情况,找出有歧义的文本块;
6、构建由图像编码器、文本编码器和跨模态编码器组成的语义感知模块,通过对比学习、匹配预测和掩码预测来训练该语义感知模块;
7、使用训练好的语义感知模块对有歧义的文本块进行场景文字检测。
8、进一步地,mask r-cnn结构包括:
9、区域候选网络rpn,用于生成文本候选框;
10、roialign,用于提取文本候选框;
11、instance box head,用于实例分类和边界框回归。
12、进一步地,使用歧义感知模块检测场景图像的文本块时,对于图像中任意两个文本实例框,如果满足该两文本实例框的iou值大于0.02,或者该两文本实例框的最小欧几里得距离小于两框最大宽度的最小值和最大高度的最小值,则合并到同一个文本块中。
13、进一步地,使用连通域分析方法分析文本块中所有文本候选框之间的连接情况,如果在一文本块内连接的像素区域数量少于匹配的文本候选框数量,其中至少两个文本候选框重叠,则判断为有歧义的文本块。
14、进一步地,所述图像编码器采用轻量级级联cnn-rnn架构,通过若干个浅层的卷积层和一个rnn层将图像特征转换为序列特征,并通过平均池化层计算图像的全局平均特征。
15、进一步地,所述文本编码器将文本样本分割为字词序列,使用wordpiece将每个子词标记成标记,将子词标记嵌入到嵌入向量中;所述文本编码器使用预训练的roberta权重来初始化。
16、进一步地,所述跨模态编码器由6个堆叠的transformer层组成,每个层包含一个多头注意力层和一个前馈网络。
17、进一步地,通过对比学习训练语义感知模块的步骤包括:
18、利用预设的图像-文本对的正例对和负例对,对语义感知模块进行对比学习训练,根据余弦相似度计算图像到文本的相似度和文本到图像的相似度;
19、根据正例对、负例对的概率与图像到文本和文本到图像的相似度的交叉熵,计算对比损失;通过最小化对比损失对齐图像特征和文本嵌入。
20、进一步地,通过匹配预测来训练语义感知模块的步骤包括:
21、对于每个图像-文本对,文本嵌入和图像嵌入通过逐元素求和进行融合,融合特征由线性二元分类器分类为正例和负例;
22、通过计算余弦相似度在上述正例和负例的小批次中采样负样本;
23、根据正例和负样本的图像与文本是否匹配的真实标签和预测标签来计算损失函数。
24、进一步地,通过掩码预测来训练该语义感知模块的步骤包括:
25、对于图像-文本对的正例对,随机遮蔽文本中的一个字符;
26、通过以文本嵌入作为查询,以视觉嵌入作为键和值,预测被遮蔽的字符,计算预测损失。
27、进一步地,使用训练好的语义感知模块对有歧义的文本块进行场景文字检测时,根据视觉置信度分数和语义置信度分数计算总的置信度分数,然后进行排行,选择分数最高的前若干项作为预测结果。
28、一种高效准确的歧义场景文字检测系统,包括:
29、文本检测分支,基于mask r-cnn结构,用于测场景图像中的文本,生成文本候选框;
30、歧义感知模块,用于检测场景图像的文本块,将文本块与文本候选框进行匹配及关联,分析文本块中所有文本候选框之间的连接情况,找出有歧义的文本块;
31、语义感知模块,由图像编码器、文本编码器和跨模态编码器组成,通过对比学习、匹配预测和掩码预测进行训练,训练完成后对有歧义的文本块进行场景文字检测。
32、与现有方法相比,本发明的优点如下:
33、1、本发明针对歧义文字检测提出了轻量级的语义感知模块,通过视觉语言联合表示学习,实现了图像特征和文本嵌入的相互对齐,可以不通过识别,直接通过候选框即图像模态感知语义,避免了将检测出的图像识别再进行语义判别这一繁琐过程,可以轻松地过滤掉缺乏逻辑语义的候选检测框,从而实现高效的消除歧义过程。此外,识别与检测解耦,任何复杂的识别方法都可以集成进来。
34、2、本发明通过歧义感知模块,通过文本块感知的方式预测图像中是否含有歧义区域,可以判别图像中哪些区域是含有歧义信息的,过滤掉大部分常规文本实例,避免复杂处理,从而对某些歧义区域稀疏的图像也能保持比较高的效率,因为只有判断为歧义的候选框才会被输入歧义模块中进行处理。
35、综上,该检测器在歧义和普通的场景上都能有较高性能的体现。
技术特征:
1.一种高效准确的歧义场景文字检测方法,其特征在于,包括以下步骤:
2.如权利要求1所述的方法,其特征在于,mask r-cnn结构包括:
3.如权利要求1所述的方法,其特征在于,使用歧义感知模块检测场景图像的文本块时,对于图像中任意两个文本实例框,如果满足该两文本实例框的iou值大于0.02,或者该两文本实例框的最小欧几里得距离小于两框最大宽度的最小值和最大高度的最小值,则合并到同一个文本块中。
4.如权利要求1所述的方法,其特征在于,使用连通域分析方法分析文本块中所有文本候选框之间的连接情况,如果在一文本块内连接的像素区域数量少于匹配的文本候选框数量,其中至少两个文本候选框重叠,则判断为有歧义的文本块。
5.如权利要求1所述的方法,其特征在于,所述图像编码器采用轻量级级联cnn-rnn架构,通过若干个浅层的卷积层和一个rnn层将图像特征转换为序列特征,并通过平均池化层计算图像的全局平均特征;
6.如权利要求1所述的方法,其特征在于,通过对比学习训练语义感知模块的步骤包括:
7.如权利要求1所述的方法,其特征在于,通过匹配预测来训练语义感知模块的步骤包括:
8.如权利要求1所述的方法,其特征在于,通过掩码预测来训练该语义感知模块的步骤包括:对于图像-文本对的正例对,随机遮蔽文本中的一个字符;
9.如权利要求1所述的方法,其特征在于,使用训练好的语义感知模块对有歧义的文本块进行场景文字检测时,根据视觉置信度分数和语义置信度分数计算总的置信度分数,然后进行排行,选择分数最高的前若干项作为预测结果。
10.一种高效准确的歧义场景文字检测系统,用于实现权利要求1-9任一项所述的方法,其特征在于,包括:
技术总结
本发明公开一种高效准确的歧义场景文字检测方法及系统,属于图像文字识别领域,使用基于Mask R‑CNN结构的文本检测分支检测场景图像中的文本,生成文本候选框;使用歧义感知模块检测场景图像的文本块,将文本块与文本候选框进行匹配及关联,分析文本块中所有文本候选框之间的连接情况,找出有歧义的文本块;构建由图像编码器、文本编码器和跨模态编码器组成的语义感知模块,通过对比学习、匹配预测和掩码预测来训练该语义感知模块;使用训练好的语义感知模块对有歧义的文本块进行场景文字检测。本发明能够高效准确地检测歧义文字,并提高识别的准确率。
技术研发人员:周宇,舒言,杨东宝,王伟平
受保护的技术使用者:中国科学院信息工程研究所
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!