一种基于记忆存储的持续对抗防御方法及系统
本发明属于持续学习,具体涉及一种基于记忆存储的持续对抗防御方法及系统。
背景技术:
1、为了适应现实生活中不断变化的数据,机器学习模型需要持续更新。持续学习模拟了人类学习和适应新知识的能力,使机器学习系统能够适应不断变化的环境和任务,提高资源利用效率,避免知识遗忘,减少人工干预,更接近通用人工智能,并应对稀缺数据等挑战,从而实现智能系统的长期适用性。现有的持续学习算法主要有三种流派:基于记忆存储的持续学习算法,基于正则的持续学习算法和基于动态架构的持续学习算法。其中基于记忆存储的持续学习算法在抗遗忘方面效果好,并且不需要额外增加模型规模,消耗少,因此本专利选择研究基于记忆存储的持续学习算法。
2、同时,机器学习模型面临着不断增加的对抗攻击威胁。这些攻击旨在利用模型的弱点,通过微小但精心设计的输入扰动来误导模型,导致它做出错误的预测或分类。对抗攻击可分为白盒攻击(攻击者了解模型结构)和黑盒攻击(攻击者不了解模型结构),并可用于各种应用,包括图像分类、自然语言处理和语音识别。这些威胁对于模型的鲁棒性和可信度构成了挑战,要求研究人员不断改进模型的防御机制,以确保其在真实世界中的可靠性和安全性。对抗攻击的研究也推动了深度学习和机器学习领域的发展,促使技术人员更深入地理解模型的工作原理和弱点。对抗攻击和知识过时都是机器学习模型在现实应用中面临的主要挑战,为了增强模型的通用性,研究如何同时增强模型持续更新和对抗鲁棒两大能力是非常合理且迫切的。
3、现有的对抗防御技术主要关注理想的实验设置,虽然也有工作考虑到现实世界中的数据通常具有长尾分布,或者将对抗性鲁棒性问题放在开放世界中。此外,一些研究表明,连续算法可以促进模型快速适应新的攻击方法。然而,它们中的大多数是为单任务学习场景设计的,现有防御技术在持续学习场景中的有效性在很大程度上仍未被探索。与以往的研究不同,发明人深入研究了如何在类和任务增量设置下提高模型的对抗鲁棒性。chen等人首先尝试增强持续学习的对抗鲁棒性,将lwf(learning without forgetting)算法与对抗训练相结合,并使用大量未标记数据来训练模型。
技术实现思路
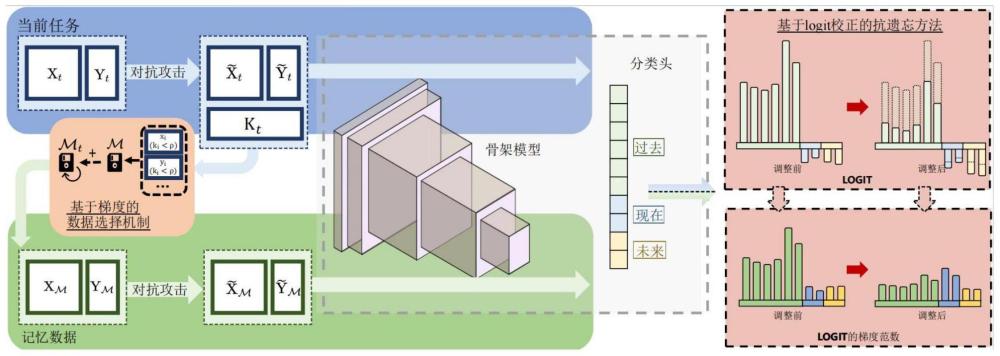
1、针对上述问题,发明人深入分析了在持续学习中实现对抗性鲁棒性的主要挑战,提出一种不需要额外数据的持续对抗防御方法,包括:获取持续学习模型的分类器的类别;对该持续学习模型的记忆训练数据和当前任务的当前训练数据生成对抗样本,将该对抗样本输入该持续学习模型,进行持续对抗训练;并在该持续对抗训练中,对该对抗样本的类别logit值以校正值进行校正;以完成训练后的持续学习模型执行该当前任务。
2、本发明所述的持续对抗防御方法,根据该当前任务的任务顺序将该分类器的类别为三类,包括:记忆类别p、当前类别c和未见类别u;获取该对抗样本的类别logit值表示的第i个类别对应的类别logit值,c为该分类器的总类别数,包括当前训练数据的对抗样本和过去数据的对抗样本则校正后的类别logit值vi为校正值,vi包括记忆训练数据校正值vp和当前训练数据校正值vc,且vp>vc≥0。
3、本发明所述的持续对抗防御方法,其中α为超参数,ni为该记忆训练数据和该当前训练数据中属于第i个类别的样本数。
4、本发明所述的持续对抗防御方法,还包括:获取该当前训练数据对应的对抗数据的困难因子k={k1,k2,...,ki,...,kn},ki为当前训练数据xi的困难系数,n为当前训练数据的样本数;对于任一xi,若ki<ρ,则将xi加入该持续学习模型的记忆数据集,ρ为筛选阈值。
5、本发明还提出一种基于记忆存储的持续对抗防御系统,包括:初始化模块,用于获取持续学习模型的分类器的类别;训练模块,用于对该持续学习模型的记忆训练数据和当前任务的当前训练数据生成对抗样本,将该对抗样本输入该持续学习模型,进行持续对抗训练;并在该持续对抗训练中,对该对抗样本的类别logit值以校正值进行校正;推理模块,用于以完成训练后的持续学习模型执行该当前任务。
6、本发明所述的持续对抗防御系统,其中该初始化模块根据该当前任务的任务顺序将该分类器的类别为三类,包括:记忆类别p、当前类别c和未见类别u;该训练模块包括logit值获取模块和校正模块,该logit值获取模块用于获取该对抗样本的类别logit值表示的第i个类别对应的类别logit值,c为该分类器的总类别数,包括当前训练数据的对抗样本和过去数据的对抗样本该校正模块用于对的类别logit值进行校正,校正后的类别logit值vi为校正值,vi包括记忆训练数据校正值vp和当前训练数据校正值vc,且vp>vc≥0。
7、本发明所述的持续对抗防御系统,其中α为超参数,ni为该记忆训练数据和该当前训练数据中属于第i个类别的样本数。
8、本发明所述的持续对抗防御系统,还包括记忆模块,用于选取当前训练数据加入该持续学习模型的记忆数据集;获取该当前训练数据对应的对抗数据的困难因子k={k1,k2,...,ki,...,kn},ki为当前训练数据xi的困难系数,n为当前训练数据的样本数;对于任一xi,若ki<ρ,则将xi加入该持续学习模型的记忆数据集,ρ为筛选阈值。
9、本发明还提出一种计算机可读存储介质,存储有计算机可执行指令,其特征在于,当该计算机可执行指令被执行时,实现如前所述的基于记忆存储的持续对抗防御方法。
10、本发明还提出一种数据处理装置,包括如前所述的计算机可读存储介质,当该数据处理装置的处理器调取并执行该计算机可读存储介质中的计算机可执行指令时,实现基于记忆存储的持续对抗防御。
技术特征:
1.一种基于记忆存储的持续对抗防御方法,其特征在于,包括:
2.如权利要求1所述的持续对抗防御方法,其特征在于,根据该当前任务的任务顺序将该分类器的类别为三类,包括:记忆类别p、当前类别c和未见类别u;
3.如权利要求2所述的持续对抗防御方法,其特征在于,
4.如权利要求1所述的持续对抗防御方法,其特征在于,还包括:
5.一种基于记忆存储的持续对抗防御系统,其特征在于,包括:
6.如权利要求5所述的持续对抗防御系统,其特征在于,该初始化模块根据该当前任务的任务顺序将该分类器的类别为三类,包括:记忆类别p、当前类别c和未见类别u;
7.如权利要求6所述的持续对抗防御系统,其特征在于,
8.如权利要求5所述的持续对抗防御系统,其特征在于,还包括记忆模块,用于选取当前训练数据加入该持续学习模型的记忆数据集;获取该当前训练数据对应的对抗数据的困难因子k={k1,k2,...,ki,...,kn},ki为当前训练数据xi的困难系数,n为当前训练数据的样本数;对于任一xi,若ki<ρ,则将xi加入该持续学习模型的记忆数据集,ρ为筛选阈值。
9.一种计算机可读存储介质,存储有计算机可执行指令,其特征在于,当该计算机可执行指令被执行时,实现如权利要求1~4任一项所述的基于记忆存储的持续对抗防御方法。
10.一种数据处理装置,包括如权利要求9所述的计算机可读存储介质,当该数据处理装置的处理器调取并执行该计算机可读存储介质中的计算机可执行指令时,实现基于记忆存储的持续对抗防御。
技术总结
本发明提出一种基于记忆存储的持续对抗防御方法,包括:获取持续学习模型的分类器的类别;对该持续学习模型的记忆训练数据和当前任务的当前训练数据生成对抗样本,将该对抗样本输入该持续学习模型,进行持续对抗训练;并在该持续对抗训练中,对该对抗样本的类别logit值以校正值进行校正;以完成训练后的持续学习模型执行该当前任务。本发明还提出一种基于记忆存储的持续对抗防御系统,以及一种用于实现基于记忆存储的持续对抗防御的数据处理装置。
技术研发人员:曹娟,弭晓月,唐帆,汪旦丁,唐胜
受保护的技术使用者:中国科学院计算技术研究所
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!