一种确定地下水污染范围的调查布点方法与流程
本发明涉及水污染检测领域,尤其涉及一种确定地下水污染范围的调查布点方法。
背景技术:
1、地下水是地下岩石中存储的一种宝贵自然资源,为城市供水、农业灌溉和生态系统提供了必不可少的支持。然而,由于人类活动和自然因素的影响,地下水质量逐渐受到破坏。地下水污染已成为当今环境保护领域的一个紧迫问题,对人类健康和生态系统构成了巨大威胁。传统的地下水污染调查方法通常依赖于有限的监测井点和采样频率,这导致了调查范围的不足和污染源的遗漏。而且,传统方法需要大量的人力和时间,成本高昂,常常无法在实时或接近实时的基础上提供必要的数据来支持紧急决策。因此,需要一种智能化创新的地下水污染调查布点方法,能够提高调查的准确性和效率,从而更好地保护地下水资源和生态环境。
2、现有的确定地下水污染范围的调查布点方法无法应用于各种类型的数据,且处理高维数据效率低下,无法快速识别潜在的污染源区域;此外,现有的确定地下水污染范围的调查布点方法数据安全性与可信度低,数据处理效率低下;为此,我们提出一种确定地下水污染范围的调查布点方法。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的一种确定地下水污染范围的调查布点方法。
2、为了实现上述目的,本发明采用了如下技术方案:
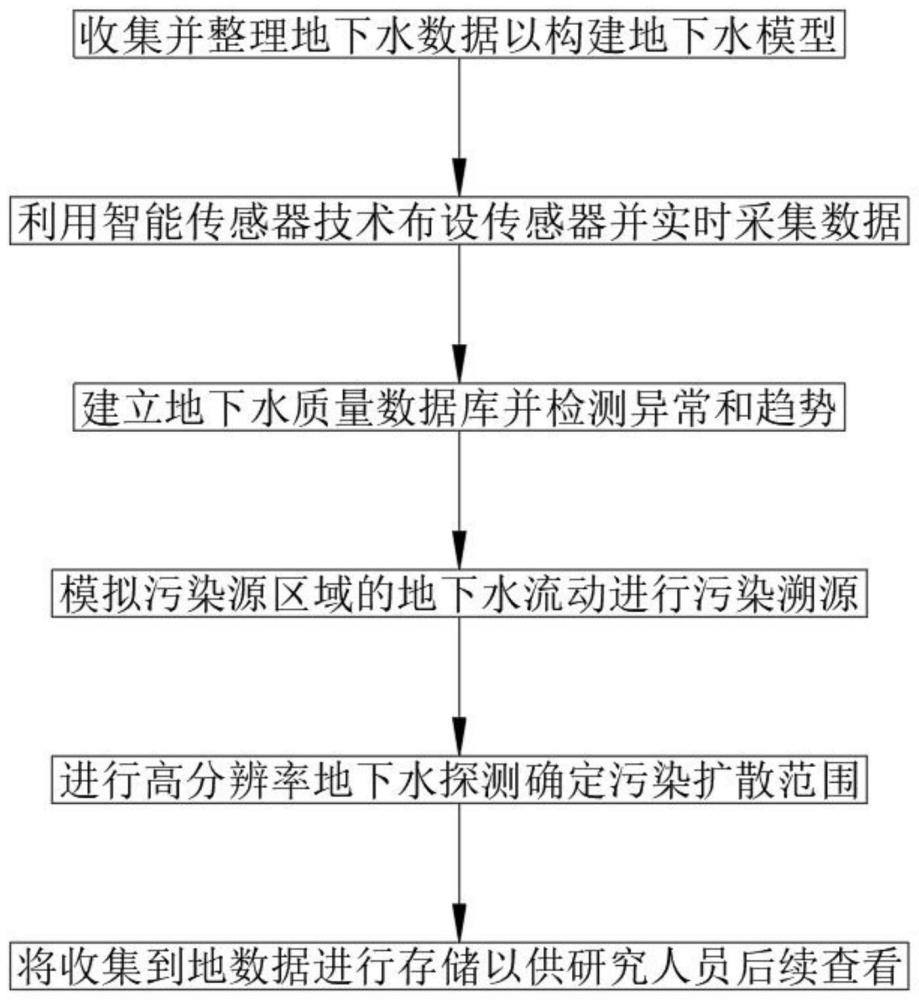
3、一种确定地下水污染范围的调查布点方法,该调查布点方法具体步骤如下:
4、(1)收集并整理地下水数据以构建地下水模型;
5、(2)利用智能传感器技术布设传感器并实时采集数据;
6、(3)建立地下水质量数据库并检测异常和趋势;
7、(4)模拟污染源区域的地下水流动进行污染溯源;
8、(5)进行高分辨率地下水探测确定污染扩散范围;
9、(6)将收集到地数据进行存储以供研究人员后续查看。
10、作为本发明的进一步方案,步骤(1)中所述地下水数据收集整理具体步骤如下:
11、步骤一:通过高斯滤波去除各组地下水数据中的噪声并平滑数据,之后计算地下水数据的标准偏差,之后依据计算出的标准偏差分别对异常数据进行检测并筛除,并统一数据格式,再检测是否存在重复的数据记录,若存在重复数据,则将其删除;
12、步骤二:检测各组数据中存在的缺失值,并标记各缺失值在对应数据中的所在位置,对各组数据中存在的缺失值进行统计和可视化分析以获取缺失值的分布情况和影响范围,并通过knn算法找到的相应的k组数据点的平均值或中位数来替代异常值或缺失值。
13、作为本发明的进一步方案,步骤(1)中所述地下水模型构建具体步骤如下:
14、步骤1:根据采集地下水流动数据,获取地下水流速和方向的信息,并通过达西定律描述地下水流动,之后利用污染物质质量守恒原理建立质量传输方程;
15、步骤2:通过实验室试验或文献数据获得扩散系数,再通过水井数据或地下水位监测获得水头差,根据污染源的性质和强度进行获取源项,之后利用有限差分法或有限元法将质量传输方程数值化;
16、步骤3:在计算机模型中模拟不同时间步骤的地下水流动和污染物传输过程以获取地下水模型,并根据获取的扩散系数、水头差、源项和边界条件预测地下水中的污染物浓度随时间和空间的分布,比较模型预测值与地下水监测数据,通过统计分析方法来评估模型性能,根据比较的结果,调整模型扩散系数、水头差以及源项。
17、作为本发明的进一步方案,步骤1中所述达西定律具体计算公式如下:
18、v=dh/dl (1)
19、式中,v代表地下水流速度;dh代表水头差;dl代表流体通过地下水层的距离;
20、步骤1中所述质量传输方程具体计算公式如下:
21、
22、式中,c代表污染物浓度;t代表时间;d代表扩散系数;代表拉普拉斯算子;s代表源项。
23、作为本发明的进一步方案,步骤(2)中所述传感器布设具体步骤如下:
24、步骤ⅰ:确定需要监测的参数根据监测需求选择传感器,之后根据地下水模型确定传感器安装位置,对各组传感器进行采集校准,再调整传感器采样间隔和数据传输频率;
25、步骤ⅱ:通过井口或钻孔将传感器放置在地下水中确定的安装位置,之后传感器根据预定的采样间隔定期记录地下水质量数据,并通过自动化算法来处理传感器数据,生成实时监测报告。
26、作为本发明的进一步方案,步骤(3)中所述异常趋势检测具体步骤如下:
27、步骤①:从地下水质量数据库中提取过往地下水数据,将各组数据整合归纳成样本数据集,之后按照预设阈值将样本数据集划分为两组特征子集,随机选择一组特征子集,重复进行特征选择和数据集分割,直至决策树的深度达到预定值,将叶子节点的标签确定为该节点中样本数量最多的类别;
28、步骤②:通过递归分裂和叶子节点标签确定,构建出一个完整的决策树,将生成的多组决策树组成随机森林模型,对于每一组数据,选取任意一个子集作为测试集,其余子集作为训练集以训练随机森林模型,并通过测试集对训练后的随机森林模型进行检测;
29、步骤③:统计检测结果的损失值,再将测试集更换为另一子集,再取剩余子集作为训练集,再次计算损失值,直至对所有数据都进行一次预测,通过选取损失值最小时对应的组合参数作为数据区间内最优的参数并替换随机森林模型原有参数;
30、步骤④:该随机森林模型接收定期接收传感器采集的各组地下水数据,并从随机森林模型的根节点开始,根据各组地下水数据的特征条件逐步遍历树的分支,直到达到叶子节点,并将该叶子节点的标签作为检测结果并输出。
31、作为本发明的进一步方案,步骤(6)中所述数据存储具体步骤如下
32、第一步:按照预设的时间区间对各组地下水数据、检测数据以及溯源数据进行分割,以获形成多组数据块,之后通过哈希算法生成各组数据块的标识,收集各组区块链节点信息,并获取各组节点负载情况;
33、第二步:通过负载均衡算法选择对应的区块链节点来存储每组数据块,数据块存储完成后,根据系统的要求和可用资源进行配置复制规定数量的数据块到多组区块链节点上,当节点存储的数据发生变化时,通过数据同步算法将数据更新从一个节点传播到其他节点;
34、第三步:当构造一组新的数据块后,将其广播到区块链网络中,并传播给多组区块链节点,各组区块链节点进行共识验证,确认该数据块的有效性和合法性并添加如区块链网络中存储。
35、相比于现有技术,本发明的有益效果在于:
36、1、该确定地下水污染范围的调查布点方法通过从地下水质量数据库中提取过往地下水数据,将各组数据整合归纳成样本数据集,之后按照预设阈值将样本数据集划分为两组特征子集,随机选择一组特征子集,重复进行特征选择和数据集分割,直至决策树的深度达到预定值,将叶子节点的标签确定为该节点中样本数量最多的类别,通过递归分裂和叶子节点标签确定,构建出一个完整的决策树,将生成的多组决策树组成随机森林模型,该随机森林模型接收定期接收传感器采集的各组地下水数据,并从随机森林模型的根节点开始,根据各组地下水数据的特征条件逐步遍历树的分支,直到达到叶子节点,并将该叶子节点的标签作为检测结果并输出,能够提供更准确的结果,同时可以应用于各种类型的数据,能够有效地处理高维数据,同时有利于快速识别潜在的污染源区域。
37、2、该确定地下水污染范围的调查布点方法按照预设的时间区间对各组地下水数据、检测数据以及溯源数据进行分割,以获形成多组数据块,之后通过哈希算法生成各组数据块的标识,收集各组区块链节点信息,并获取各组节点负载情况,通过负载均衡算法选择对应的区块链节点来存储每组数据块,数据块存储完成后,根据系统的要求和可用资源进行配置复制规定数量的数据块到多组区块链节点上,当节点存储的数据发生变化时,通过数据同步算法将数据更新从一个节点传播到其他节点,当构造一组新的数据块后,将其广播到区块链网络中,并传播给多组区块链节点,各组区块链节点进行共识验证,确认该数据块的有效性和合法性并添加如区块链网络中存储,提高数据安全性与可信度,能够自动化数据处理流程,提高效率并减少人为错误。
- 还没有人留言评论。精彩留言会获得点赞!