一种基于视频动作的多模型集成多相位MRI肿瘤分类方法
本发明属于图像处理与人工智能,特别是涉及一种基于视频动作分类的多模型集成的多相位mri肿瘤分类方法。
背景技术:
1、肝脏的肿瘤分类任务一直是人们研究的热点,正确区分良性和恶性肝脏病变可以有效的避免不必要的肝活检,从而避免肝活检所引起的出血,疼痛,感染以及其他器官损伤等。同时,及早发现和准确分类局灶性肝脏病变对于后续的有效治疗极为重要。
2、以往的相关研究主要集中于ct成像,然而随着影像学技术的不断发展,mri以其无辐射,软组织对比度高,适用于各类人群的优异特点渐渐开始引起人们的关注,尽管如此,由于mri上病变的表现范围很广,需要临床经验丰富的医师对病人的mri影像进行人工分析标注,导致诊断病变类型的效率低、分析过程漫长;因此,自动诊断分类系统可以帮助放射科医生较好的完成这项任务,目前常被用于研究的是t1,t2加权磁共振图像,而随着更多不同相位的图像的出现,仅仅研究单一相位的mri图像往往会丢失许多重要的信息,从而限制了肝脏病变分类的性能。
3、传统的机器学习算法需要预先定义特征,将预定义的特征以各种组合的方式应用于有效的诊断,但这些组合通常不全面,导致信息的丢失从而影响准确率,如今基于深度学习的算法由于其自动特征生成和图像分类的能力而被广泛应用,对于mri,其可以生成多平面成像,因此可以呈现出三维的解剖结构信息,然而以往的一些研究在每个mri切片上使用二维cnn建模,这忽略了切片之间的空间关联性,导致诊断错误,因此三维方法可能更有利。
4、综上所述,传统的方法往往只处理单一相位的mri数据,无法适应当今的多相位mri数据,同时传统方法仍对每张mri切片做2d建模,忽略了切片之间的关联性,因此,迫切需要一种3d建模的、鲁棒性强的、能够通过多相位mri数据正确诊断肝脏病变的方法来进行自动诊断。
技术实现思路
1、(1)要解决的技术问题
2、本发明公开了一种基于视频动作的多模型集成多相位mri肿瘤分类方法,旨在解决mri数据病变范围广,导致人工分析标注效率低、分析时间长的问题,同时针对单一相位的mri数据只进行2d建模,忽略了切片之间的关联性的问题也有进一步的优化。
3、(2)技术方案
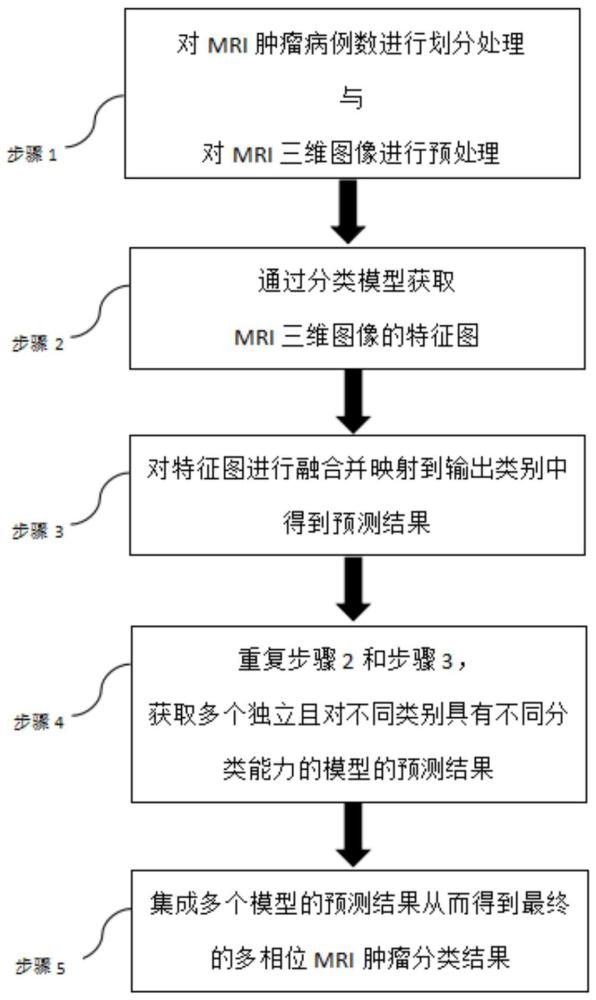
4、本发明公开了一种基于视频动作的多模型集成多相位mri肿瘤分类方法,其特征在于,包括以下步骤:
5、步骤1,对mri肿瘤病例数进行划分处理与对mri三维图像进行预处理;
6、步骤2,通过分类模型获取mri三维图像的特征图;
7、步骤3,对特征图进行融合并映射到输出类别中得到预测结果;
8、步骤4,重复步骤2和步骤3,获取多个独立且对不同类别具有不同分类能力的模型的预测结果;
9、步骤5,集成多个模型的预测结果从而得到最终的多相位mri肿瘤分类结果。
10、进一步地,步骤1具体方法如下:
11、先采用五倍交叉验证法将mri肿瘤病例数划分成五份独立的训练验证集,再通过预处理将肿瘤的三维图像感兴趣区域提取出来并缩放至同一尺寸,得到形如n,t,z,h,w的输入数据,其中,z代表深度,h代表高度,w代表宽度,共有t个模态,训练的batch为n。
12、进一步地,五倍交叉验证法如下:
13、(train,val)i=cv(k)
14、其中,k为划分的次数,k=5,i=1,2,...,k,train为训练集,val为验证集,cv为交叉验证分组情况;
15、将数据集划分为k个大小相等的子集,轮流选取k-1个子集用作训练数据,剩下的1个子集用作验证数据,这个过程重复k次,得到k份训练验证数据。
16、进一步地,缩放方法具体如下:
17、采用pytorch中的torch.nn.functional.interpolate()实现,即使用三次线性插值,公式如下:
18、x=concat(interpolate(y1);interpolate(y2)...;interpolate(yt))
19、其中,x为缩放结果即所述步骤2的输入数据,y∈rt*z*h*w,t为模态数量,yt为第t个模态的图像数据,z为三维立方体的深度,h为三维立方体的高度,w为三维立方体的宽度,interpolate为缩放方法,concat为连接两个或多个数组的方法。
20、进一步地,步骤2具体方法如下:
21、将输入数据送入对应的视频动作分类模型中,通过局部多头关系聚合器进行下采样得到浅层特征图。
22、进一步地,局部多头关系聚合器包括一个由三维卷积实现的位置编码和一个由三维卷积实现的上下文聚合器,通过局部多头关系聚合器进行下采样,包括以下步骤:
23、通过一个三维分组卷积实现的位置编码来捕获体素之间的位置关系:
24、xp=p(x)+x
25、其中,xp为整合了位置编码的输入特征,p(x)=concat(g1(x);g2(x)...;gn(x))u,其中,x为所述输入数据,gn(x)为n个三维分组卷积,u为聚合n个分组卷积的可学习矩阵,u∈rc*c、r为实数集、c为复数集;
26、进而通过一个可学习的参数矩阵实现的局部关系聚合器lra,并使用残差连接得到输出特征:
27、xlp=lra(xp)+xp
28、lra(xp)=conv1(conv2(conv3(norm(xp))))
29、其中conv1,conv3为1x1的三维卷积核,conv2为5x5且padding=2的三维卷积核,norm为pytorch中的nn.layernorm层;
30、最后输出特征通过一个前馈层得到最终的浅层特征图。
31、进一步地,前馈层为多层感知机:
32、x′lp=dropout(linear1(gelu(linear2(xlp)))
33、其中linear1,linear2为pytorch中的nn.linear方法,gelu为非线性激活,dropout为向前传递的过程层,x′lp为浅层特征图。
34、进一步地,步骤3具体方法如下:
35、将浅层特征图送入深层全局多头关系聚合器进行特征融合得到融合特征,最终通过全连接层将融合特征映射到输出类别中得到预测结果。
36、进一步地,全局多头关系聚合器包括一个由三维卷积实现的位置编码和一个自注意力模块,所述特征融合,包括以下步骤:
37、首先通过一个三维分组卷积实现的位置编码来捕获体素之间的位置关系:
38、xlpp=p(x′lp)+x′lp
39、其中,xlpp为整合了位置编码的浅层特征图,p(x)=concat(g1(x);g2(x)...;gn(x))u,其中,x′lp为浅层特征图,gn(x)为n个三维分组卷积,u为聚合n个分组卷积的可学习矩阵,u∈rc*c、r为实数集、c为复数集;
40、然后将整合了位置编码的浅层特征图xlpp∈rc*z*h*w重塑为xlpp∈rc*l,l=z*h*w,全局多头关系聚合器gra可以表示为:
41、xgpp=gra(xlpp)
42、gra(xlpp)=concat(h1(xlpp);h2(xlpp);...;hn(xlpp))u
43、hn(xlpp)=an(xlpp)vn(xlpp)
44、其中,xgpp为融合特征,hn(x)表示为多头注意力机制中的第n个头,u表示一个可学习的参数矩阵用于聚合n个头的信息,u∈rc*c,an(x)代表一个相似性函数,an∈rl*l,vn(x)是由一个线性变换得到的上下文标记,
45、进一步地,相似性函数是由自注意力机制实现的,表示为:
46、
47、其中,xi,xj为任意2个体素点,i不等tj,xi∈z*h*w,xj∈z*h*w,qn(·),kn(·)为2个独立的线性变换。
48、进一步地,全连接层计算过程如下:
49、1.将上一层的所有神经元的输出作为输入,每个输入都与对应的权重相乘;
50、2.将所有乘积结果进行加权求和,并加上对应的偏置项;
51、3.对求和结果应用激活函数如relu,以产生该层的输出。
52、进一步地,步骤4具体方法如下:
53、对五份独立的训练验证集分别进行训练验证,得到独立的多个对不同类别具有不同分类能力的模型的预测结果。
54、进一步地,得到多个对不同类别具有不同分类能力的模型的预测结果,具体方法如下:
55、pi=model((train,val)i)
56、其中,p为预测结果,所述pi在实际应用中表达为概率值如99.99%,(train,val)i表示第i份训练验证数据,共有5份,model为视频动作分类领域中的任意模型,通过以f1-score,kappa的平均值作为筛选条件,筛选出model的最佳视频动作分类模型。
57、进一步地,以f1-score,kappa的平均值作为筛选条件,筛选出model的最佳视频动作分类模型包括以下步骤:
58、f1-score是精确率和召回率的调和平均值,在以下公式中定义为f1:
59、
60、
61、
62、kappa是用于评估分类模型性能一致性的度量:
63、
64、
65、
66、其中,precision为精确率是预测为正例的项中实际为正例的比例,recall为召回率是实际正例中被正确预测为正例的比例;areal,breal表示实际为a,b的样本数量;apred,bpred表示预测为a,b的样本数量;n为总样本数;true positives表示模型正确预测为正例的样本数量,false positives表示模型错误预测为正例的样本数量,false negatives表示模型错误预测为负例的样本数量;po表示为实际协调率,pe预期协调率;
67、模型挑选的规则为:
68、
69、其中,argmax为从目标函数中找到给出最大值的参数的操作。
70、进一步地,视频动作分类模型model为uniformer的各种变体,包括uniformer-small、uniformer-base,对于每个模型均使用了迁移学习的策略,以对应模型在k-400数据集上预训练的权重作为初始化,训练过程中以f1-score和kappa的平均值作为评判标准挑选最优模型。
71、进一步地,步骤5具体方法如下:
72、将多个模型对所述输入数据的预测结果取平均值得到最终的多相位mri肿瘤分类结果。
73、进一步地,多个模型对输入数据的预测结果取平均值方法如下:
74、
75、其中mk表示第k个模型的预测结果,x为输入数据,共有n个模型,pf表示最终的输出概率;
76、通过获取最终的输出概率pf作为最终的多相位mri肿瘤分类概率,即可获得对多相位mri肿瘤分类结果。
77、与现有技术相比,本发明的有益效果在于:
78、本发明将视频动作分类模型的建模方式应用于多相位mri肿瘤分类任务中,利用视频动作分类模型3d建模方式,增强了多相位mri肿瘤分类切片之间的联系,更好地捕获切片之间的上下文关系,从而提高了预测的准确性;同时采用交叉验证划分数据集的方法得到多个独立的训练验证集,并对不同的训练验证集以f1,kappa的平均值作为指标挑选出最佳的视频动作分类模型进行集成,得到更具鲁棒性和更精准的预测结果,使自动诊断多相位mri肿瘤分类结果的精准度进一步提高,有效的缓解了医疗数据集中、数据量少、数据集不平衡的问题。
- 还没有人留言评论。精彩留言会获得点赞!