一种基于深度学习的陀螺实时数据估计预测的方法与流程
本发明属于陀螺,涉及一种基于深度学习的陀螺实时数据估计预测的方法。
背景技术:
1、陀螺数据通常会受到各种噪声和干扰的影响,如电路、振动、温度变化等。传统实时数据估计预测方法可以通过建立准确的模型和对噪声进行滤波,降低噪声对陀螺数据的影响,提高数据的质量和准确性。然而,现有的预测方法普遍存在效果不理想、适用场景局限等问题。传统的卡尔曼滤波器和它的变种,如扩展卡尔曼滤波器(ekf)和无迹卡尔曼滤波器(ukf),被广泛应用于陀螺数据的预测估计。这些方法的一个重要假设是系统是线性的,并且噪声是高斯的。然而,陀螺系统是非线性的,噪声也可能不符合高斯分布,这使得传统的卡尔曼滤波器在这些情况下效果可能并不理想。另外,这些方法对陀螺数据的降噪效果也有限。虽然ekf和ukf可以处理非线性问题,但处理能力有限,计算复杂性较高,对陀螺降噪效果不明显。此外,卡尔曼滤波及其变体在处理噪声和不确定性方面的表现依赖于其初始估计。如果初始估计出现偏差,可能需要较长的时间才能收敛到正确的值,这可能会影响到系统的实时性能。
2、因此,如何提供一种新的陀螺实时数据估计预测方法,不仅能更准确地预测数据,同时还能有效地降低噪声,解决以上问题,是目前急需解决的问题。特别是基于深度学习的预测方法,有潜力在降噪和预测准确性上显著超越传统方法。
技术实现思路
1、本发明的目的在于提供一种基于深度学习的陀螺实时数据估计预测的方法,以解决传统的卡尔曼滤波器在有些情况下效果并不理想。另外,这些方法对陀螺数据的降噪效果也有限的问题。
2、为了解决上述技术问题,本发明提供了一种基于深度学习的陀螺实时数据估计预测的方法,该方法分为两个部分,第一部分包括模型的训练,第二部分包括模型的硬件部署:
3、第一部分模型的训练包括以下步骤:
4、s11、陀螺真实场景的数据收集
5、从陀螺仪传感器中读取单轴或多轴上的角速度;
6、s12、陀螺数据的特征化处理
7、陀螺仪数据的特征化处理包括:数据预处理、陀螺仪特征提取、加速度计特征提取和训练数据生成;
8、s13、模型选择和训练
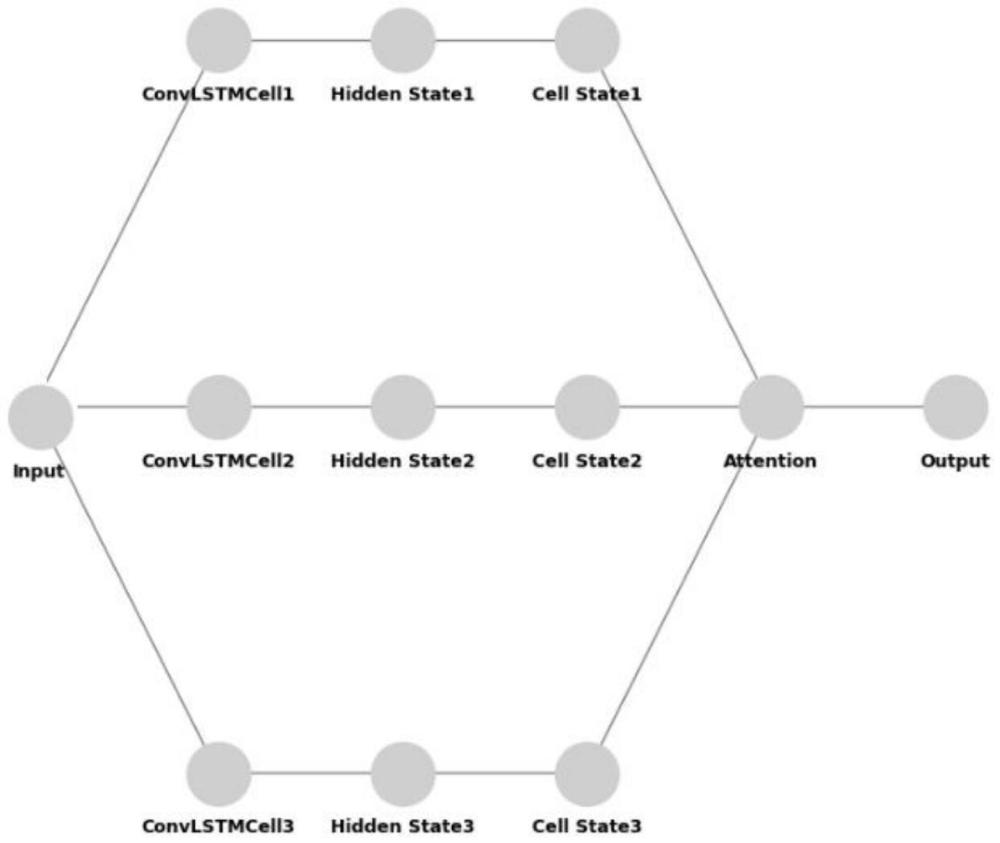
9、模型主体采用卷积长短期记忆网络convlstm,同时使用注意力机制;convlstm是卷积长短时记忆网络层,convlstm层有三个子单元:convlstmcell1、convlstmcell2和convlstmcell3,这些子单元表示convlstm层内部的单元,每个convlstmcell处理输入数据,并生成隐藏状态hidden state;convlstmcell1、convlstmcell2和convlstmcell3各连接一个隐藏状态节点,分别为hidden state1,hidden state2和hidden state3;这些隐藏状态节点表示每个convlstm单元的隐藏状态,隐藏状态包含了过去时间步的信息;每个隐藏状态节点连接到一个单独的细胞状态节点cell state,这些细胞状态节点表示convlstm单元的细胞状态,是lstm网络中的另一种状态,用于存储长期信息;在此架构中,cellstate1、cell state2和cell state3都连接到注意力模块,注意力模块接收来自三个细胞状态的输入,并将加权输出传递到输出层;
10、s14、模型的评估
11、对模型进行训练,训练好后模型,根据评估方法,不断调整参数直到满足需求;评估方法包括:对模型的泛化能力、稳定性、响应时间进行评估;
12、第二部分模型的硬件部署包括:
13、训练好模型后,在陀螺硬件上部署,首先安装硬件需要的软件环境,然后将利用库文件写成的模型,转换为通用格式,再将通用格式转换成软件中的格式,然后利用软件编译和优化模型,最后将模型程序下载到硬件中,最后实现陀螺实时数据的估计和预测。
14、本发明提供一种基于深度学习的陀螺实时数据估计预测的方法,本发明的方法的相较于传统方法的显著优点:
15、1、与传统的卡尔曼滤波器和其变种方法相比,基于深度学习的模型能够更好地捕捉陀螺数据中的复杂非线性关系。深度学习模型通过多层神经网络的连接和非线性激活函数的引入,能够更好地拟合非线性关系,从而提高预测的准确性。
16、2、基于深度学习的方法在处理多轴数据方面具有优势。传统方法在处理多轴数据时可能需要引入更复杂的数学模型或进行轴间相关性的处理。而本发明的方法可以直接将多轴数据作为输入,并通过神经网络的并行计算能力有效地处理多轴数据。
17、3、基于深度学习的方法还能够更好地适应不同噪声分布。传统方法通常假设噪声服从高斯分布,但在实际应用中,陀螺数据可能受到各种噪声和干扰的影响,其噪声分布可能不符合高斯假设。本发明的方法不对噪声分布作出明确假设,而是通过大量的训练数据和神经网络的非线性映射能力来适应不同噪声分布,从而提高对陀螺数据的估计和预测性能。
18、4、本发明一系列的特征工程和模型设计,提高了陀螺实时数据的估计预测准确性、时效性。同时可以硬件部署。即使动态下也可以良好的估计预测,还起到很好的降噪作用。
技术特征:
1.一种基于深度学习的陀螺实时数据估计预测的方法,其特征在于,该方法分为两个部分,第一部分包括模型的训练,第二部分包括模型的硬件部署:
2.如权利要求1所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,所述s11中,数据的收集过程需要通过硬件接口与上位机进行交互,或者直接存在陀螺的flash硬件中。
3.如权利要求1所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,所述步骤s12具体包括:
4.如权利要求3所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,时域特征包括:滑动窗口内的最大值、最小值和均值;频域特征包括:通过傅里叶变换获取的频谱特征。
5.如权利要求1-4任一项所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,
6.如权利要求5所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,在开始训练之前,首先使用xavier或he权重初始化方法初始化模型的权重,然后,根据实验结果和具体的应用需求,选择合适的学习率、优化器;优化器包括:sgd、adam和rmsprop。
7.如权利要求5所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,在进行模型训练的过程中,将采用数据集的划分方法:将原始的数据集划分为训练集和验证集,在每一轮训练结束后,将使用验证集数据来检验模型的性能,如果模型在训练集上的表现良好,但在验证集上的表现较差,那就说明模型可能发生了过拟合,这时调整模型的结构或者训练策略来改善模型的泛化能力。
8.如权利要求7所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,在进行模型训练的过程中,使用早停策略(early stopping)和正则化(regularization);早停的主要思想是:在每一个训练周期epoch结束时,都会使用验证集来评估模型的性能,如果在一定数量的连续周期中,验证集的性能没有明显提高,就会停止训练;正则化是通过在模型的损失函数中引入额外的惩罚项,限制模型的复杂度。
9.如权利要求8所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,模型泛化能力的评估是指:在面对这些未见过的情况时,预测性能是否依然稳定,如果模型在测试集上的性能与在训练集上的性能相近,那么就认为模型具有良好的泛化能力;模型稳定性的评估是指:在输入存在噪声或扰动的情况下,也能给出相对稳定的输出结果;模型响应时间评估是指:模型从接收到输入数据到产生预测结果所需要的时间。
10.如权利要求1所述的基于深度学习的陀螺实时数据估计预测的方法,其特征在于,陀螺为光纤陀螺、mems陀螺或激光陀螺。
技术总结
本发明涉及一种基于深度学习的陀螺实时数据估计预测的方法,属于陀螺技术领域。本发明的方法分为两个部分,第一部分包括模型的训练,第二部分包括模型的硬件部署。本发明的深度学习模型通过多层神经网络的连接和非线性激活函数的引入,能够更好地拟合非线性关系,从而提高预测的准确性。本发明的直接将多轴数据作为输入,并通过神经网络的并行计算能力有效地处理多轴数据,通过大量的训练数据和神经网络的非线性映射能力来适应不同噪声分布,从而提高对陀螺数据的估计和预测性能。本发明即使动态下也可以良好的估计预测,还起到很好的降噪作用。
技术研发人员:施洋,王逸伦,张戈辉,罗雪峰,甘雄,张超,肖新东,石立超,于全福,范顺飞,马红卫,张辰,吴青昀,杨添舒,李志刚,李磊,高宝玮,杨富中,陈宇杰,张淇,何玉铭,陈琛,吴穹,杨光
受保护的技术使用者:中国兵器工业导航与控制技术研究所
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!