数据处理方法、文图生成方法及相关装置与流程
本技术涉及人工智能,尤其涉及数据处理方法、文图生成方法及相关装置。
背景技术:
1、随着人工智能技术(artificial intelligence,ai)的发展,文图生成模型在生成式ai领域取得了显著的进展和关注。但在应用于简单文本转换为图像的任务上,文图生成模型仍有一定的挑战。具体而言,当涉及从文本生成图像,要求输入文本内容要丰富和详细,比如包括背景、物体、风格等多方面的信息。然而,实际用户的输入往往相对简短,这就导致了文图生成模型难以准确捕获细节和场景要素进行图像生成。
技术实现思路
1、为了解决上述的问题,本技术的实施例中提供了数据处理方法、文图生成方法及相关装置,将用户输入的简短文本进行扩充后得到丰富的描述细节的提示文本,根据扩充后的提示文本,文图生成模型可以准确捕获细节和场景要素进行图像生成。
2、为此,本技术的实施例中采用如下技术方案:
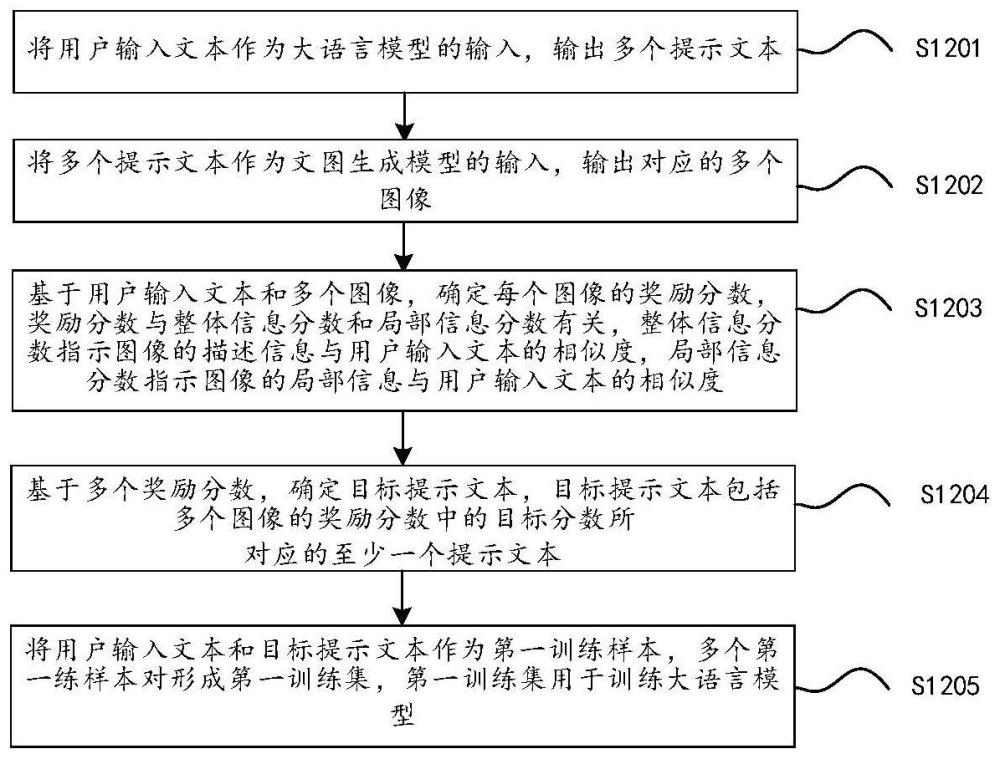
3、第一方面,本技术实施例提供了一种数据处理方法,包括:将用户输入文本作为大语言模型的输入,输出多个提示文本;将多个提示文本作为文图生成模型的输入,输出对应的多个图像。对用户输入文本和多个图像进行处理,得到每个图像的奖励分数,奖励分数与整体信息分数和局部信息分数有关,整体信息分数指示图像的描述信息与用户输入文本的相似度,局部信息分数指示图像的局部信息与用户输入文本的相似度。确定包括奖励分数为目标分数的至少一个提示文本为目标提示文本。将用户输入文本和目标提示文本作为第一训练样本对,多个第一练样本对形成第一训练集。使用第一训练集训练大语言模型。
4、也就是说,本技术实施例提供了一种数据处理方法,用来训练大语言模型,使得大语言模型可以对用户输入文本进行扩充得到提示文本。进而,由于提示文本包括了丰富的细节和场景信息,因此文图生成模型可以生成包含丰富信息的图像。一般地,用户输入的文本难以具有丰富的细节信息,往往较为简短。本技术实施例中,大语言模型的微调训练与奖励分数有关。由于奖励分数表征了用户输入文本与图像的相似度,进而奖励分数表征了用户输入文本与提示文本的相似度。进而在推理阶段,大语言模型生成的提示文本与用户输入文本有很高的相似度,使得文图生成模型可以生成与用户输入文本更匹配的图像。也就是说,文图生成模型可以生成更加符合用户期望的图像。
5、进一步地,微调训练之前,大语言模型对用户输入文本的扩充过程没有目的,因此扩充的提示文本质量参差不齐。在本技术实施例中,大语言模型对用户输入文本进行扩充。将大语言模型扩充后的多个提示文本分别输入文图生成模型,生成对应的多个图像,基于生成的图像与用户输入文本的一致性,通过奖励分数的方法对每个图像进行打分。奖励分数越高,说明图像的质量越高,也就是图像与用户输入文本的一致性越高,进而对应的提示文本与用户意图的匹配度越高。因此,可以基于奖励分数筛选出高质量的图像,进而得到对应的高质量提示文本。将用户输入文本和高质量的提示文本作为训练样本,形成训练集,对大语言模型微调,使得微调后的大语言模型可以将用户输入的简短文本扩充为高质量提示文本,高质量提示文本符合文图生成模型输入要求的,进而文图生成模型可以生成高质量的图像。其中,图像的高质量是指图像与用户输入文本的一致性高,与用户意图的匹配度越高,更符合用户的期望。
6、进一步地,本技术实施例中,大语言模型的微调训练过程中,以文图生成模型输出的图像的奖励分数为训练样本的选择依据,目的是寻找大语言模型对用户输入文本的扩充效果较好的提示文本,以对大语言模型进行微调。大语言模型和文图生成模型是一个整体性的系统,不能分割来看。也就是说,不同的文图生成模型具有不同的算法,因此基于提示文本生成图像的细节捕捉等能力也不同,大语言模型微调后可以与对应的文图生成模型匹配,扩充得到适合该文图模型的提示文本。
7、进一步地,本技术实施例提供了一种奖励分数生成方法。奖励分数指示了图像和用户输入文本的一致性程度。本技术实施例奖励分数细化为整体信息分数和局部信息分数。整体信息分数与图像的描述信息和用户输入文本的相似度有关,因此整体信息分数表征了图像和用户输入文本在整体角度上的一致性程度。局部信息分数与图像的局部信息与用户输入文本的相似度有关,因此局部信息分数表征了图像和用户输入文本在局部细节角度上的一致性程度。因此,本技术实施例的奖励分数包括整体和细节两种细粒度的衡量,可以更好地对齐图像和用户输入文本间的细粒度语义,避免了输出的图像出现用户输入文本的语义丢失及错乱的情况。
8、在一种可能的实现方式中,基于用户输入文本和多个图像,确定每个图像的奖励分数,包括:基于多个图像的描述信息与用户输入文本的相似度,确定每个图像的整体信息分数;基于多个图像的局部信息与用户输入文本的相似度,确定每个图像的局部信息分数;对每个图像的整体信息分数和局部信息分数加权,得到每个图像的奖励分数。
9、在该实现方式中,本技术实施例提供了一种奖励分数的计算方法。可以基于具体的应用场景,通过对整体和细节两种细粒度的不同衡量,对整体信息分数、局部信息分数分别赋予不同的权重,提高了奖励分数的适用范围。
10、在另一种可能的实现方式中,基于多个图像的描述信息与用户输入文本的相似度,确定每个图像的整体信息分数,包括:确定图像的描述文本;对描述文本进行特征提取,得到描述文本的特征向量;对用户输入文本进行特征提取,得到用户输入文本的特征向量;基于描述文本的特征向量和用户输入文本的特征向量的相似度,得到整体信息分数。
11、在该实现方式中,本技术实施例提供了一种整体信息分数的实施方法。基于图像,得到图像的描述文本,再将描述文本转换为描述文本特征,以便于进行相似度的计算。将用户输入的简短文本转换为输入文本特征,以便于进行相似度的计算。通过计算输入文本特征和描述文本特征的相似度,得到整体信息分数。在该实现方式中,将图像的描述信息具体为图像的描述文本,由于图像的描述文本是从整体上对图像进行描述,因此描述文本可以从整体的角度表征图像的描述信息。
12、在另一种可能的实现方式中,确定图像的描述文本,包括:将图像作为图像描述生成模型的输入,输出图像的描述文本。
13、在该实现方式中,本技术实施例提供了图像的描述文本的实现方式。图像描述生成模型可以是任何一种基于图像生成图像标注的神经网络模型,技术手段成熟,开发成本低。
14、在另一种可能的实现方式中,基于多个图像的局部信息与用户输入文本的相似度,确定每个图像的局部信息分数,包括:确定图像中各个图像区域的类别;基于图像和各个图像区域的类别,确定比例信息,比例信息指示各个类别的图像区域在图像中的所占比例;基于用户输入文本和各个图像区域的类别、比例信息,确定局部信息分数。
15、在该实现方式中,本技术实施例提供了一种局部信息分数的实施方式。基于图像,计算图像的类别标签。基于类别标签去关注每个类别在图像中的比例信息。可以进一步理解的是,某个类别的比例越高,说明图像对该类别的关注度越高,图像对该类别的重视度越高。同时,如果高比例的类别与用户输入文本的相似度低,或者低比例的类别与用户输入文本的相似度高,也就是说没有重视该重视的或者重视了不该重视的,说明该图像是一个质量低的图像,因此不符合用户的期望。只有,高比例的类别与用户输入文本的相似度也高,说明该图像的特点为重视了应该重视的类别,说明该图像是一个质量高的图像,因此符合用户的期望。因此,局部信息分数可以反映图像的局部细节的正确性,使得局部细节质量高的图像得到较高的局部信息分数,提高了奖励分数对图像细节的表征,使得奖励分数对图像的评分更具客观性。
16、在另一种可能的实现方式中,基于用户输入文本和各个图像区域的类别、比例信息,确定局部信息分数,包括:基于比例信息,对用户输入文本和各个图像区域的类别的相似度进行加权,得到局部信息分数。
17、在该实现方式中,本技术实施例提供了一种局部信息分数的计算方式。也就是说,可以使用线性或者非线性的组合方式对比例信息、用户输入文本和类别标签的相似度进行组合,得到局部信息分数。而基于比例信息,对用户输入文本和类别标签的相似度进行加权,是一种易于实现的线性组合方法,方法简单,使得局部信息分数同时考虑了比例信息、用户输入文本和类别标签的相似度两种因素。
18、在另一种可能的实现方式中,确定图像中各个图像区域的类别;基于图像和各个图像区域的类别,确定比例信息;基于用户输入文本和各个图像区域的类别、比例信息,确定局部信息分数包括:将图像作为图像标注模型的输入,图像标注模型对图像中的各个图像区域进行类别标注,输出图像中各个图像区域的类别;和/或将图像和各个图像区域的类别作为图像分割模型的输入,图像分割模型基于各个图像区域的类别对图像进行分割,输出比例信息;和/或将用户输入文本、各个图像区域的类别和比例信息输入预训练模型,预训练模型基于比例信息对用户输入文本和各个图像区域的类别的相似度进行加权,输出局部信息分数。
19、在该实现方式中,本技术实施例提供了一种类别信息、比例信息和局部信息分数的计算方式。通过图像标注模型得到图像中目标的类别信息,通过图像分割模型得到每个类别在图像中的所占比例,通过预训练模型。该实施方法简单,易于实现,研发成本低。
20、在另一种可能的实现方式中,奖励分数还与图像的美学分数有关。美学分数指示图像与美学相关标准的一致性。
21、在该实现方式中,本技术实施例提供了一种与美学分数有关的奖励分数。也就是说,奖励分数还表征了图像在美学方面的质量评价,丰富了图像的评价指标,使得基于奖励分数得到的图像或者提示文本质量更高,大语言模型生成的扩充后的提示文本、文图生成模型输出的图像都更加符合用户的期望。
22、在另一种可能的实现方式中,将用户输入文本作为大语言模型的输入,输出多个提示文本,包括:将用户输入文本作为提示生成器的输入,输出用户输入提示文本;将用户输入提示文本,作为大语言模型的输入,输出提示文本。
23、在该实现方式中,本技术实施例提供了一种用户输入文本的处理方法。也就是说,在将用户输入文本输入大语言模型之前,可以向对用户输入文本进行初步扩充或者改写,增加一些扩充文本的要求或者提示,使得大语言模型的文本扩充效果更佳。比如用户的输入文本为x,可以进行初步扩充,比如扩充为“根据以下文本:x,扩写相关背景语义及风格描述”,从而提示或者指导大语言模型进行文本扩充,使得大语言模型在相关背景语义及风格描述方面进行扩充,进而生成的提示文本可以具有更丰富的细节信息,从而符合文图生成模型的输入要求。
24、在另一种可能的实现方式中,奖励分数还用于指示提示文本和图像的相似度,以使文图生成模型基于奖励分数确定微调训练的训练集;其中,整体信息分数还用于指示图像的描述信息与提示文本的相似度,局部信息分数还用于指示图像的局部信息与提示文本的相似度。
25、在该实现方式中,本技术实施例提供了奖励分数的另一种用途:微调训练文图生成模型。将提示文本作为文图生成模型的输入,输出多个图像;奖励分数还用于指示该多个图像与该提示文本的一致性。通过对文图生成模型生成的多个图像进行质量评估,得到每个图像的奖励分数。将奖励分数最高的一个或者多个图像作为训练样本,并与输入的提示文本形成训练样本对,多个训练样本对形成训练数据集,进而对文图生成模型进行微调训练,以通过文图生成模型基于文本生成图像的图像质量。在奖励分数的作用下,文图生成模型可以基于质量更高的训练样本进行学习,从而微调训练后的文图生成模型可以捕捉更多的细节信息,可以生成质量更高的图像。
26、第二方面,本技术实施例提供了一种文图生成方法,包括:获取用户输入文本;将用户输入文本作为大语言模型的输入,输出多个提示文本;将多个提示文本作为文图生成模型的输入,输出对应的多个图像;基于用户输入文本和多个图像,确定每个图像的奖励分数,奖励分数与整体信息分数和局部信息分数有关,整体信息分数指示图像的描述信息与用户输入文本的相似度,局部信息分数指示图像的局部信息与用户输入文本的相似度;基于多个图像的奖励分数,确定目标图像,目标图像包括奖励分数为目标图像分数的至少一个图像。
27、也就是说,在推理阶段,通过计算文图生成模型的多个图像的奖励分数,可以将奖励分数为目标分数的目标图像输出给用户。因此,进一步使得目标图像更加符合用户意图,即最终输出的目标图像与用户输入文本的一致性更高。
28、第三方面,本技术实施例提供了一种数据处理装置,应用于大语言模型,包括:获取模块,用于获取用户输入文本;文本扩充模块,用于将用户输入文本作为大语言模型的输入,输出多个提示文本;文图生成模块,用于将多个提示文本作为文图生成模型的输入,输出对应的多个图像;奖励分数生成模块,用于基于用户输入文本和多个图像,确定每个图像的奖励分数,奖励分数与整体信息分数和局部信息分数有关,整体信息分数指示图像的描述信息与用户输入文本的相似度,局部信息分数指示图像的局部信息与用户输入文本的相似度;训练模块,用于基于多个奖励分数,确定目标提示文本,目标提示文本包括奖励分数为目标分数时对应的至少一个提示文本;以及将用户输入文本和目标提示文本作为第一训练样本,多个第一练样本对形成第一训练集,第一训练集用于训练大语言模型。
29、在一种可能的实现方式中,奖励分数生成模块,具体用于:基于多个图像的描述信息与用户输入文本的相似度,确定每个图像的整体信息分数;基于多个图像的局部信息与用户输入文本的相似度,确定每个图像的局部信息分数;对每个图像的整体信息分数和局部信息分数加权,得到每个图像的奖励分数。
30、在另一种可能的实现方式中,奖励分数生成模块,具体用于:确定图像的描述文本;对描述文本进行特征提取,得到描述文本的特征向量;对用户输入文本进行特征提取,得到用户输入文本的特征向量;基于描述文本的特征向量和用户输入文本的特征向量的相似度,得到整体信息分数。
31、在另一种可能的实现方式中,奖励分数生成模块,具体用于:将图像作为图像描述生成模型的输入,输出图像的描述文本。
32、在另一种可能的实现方式中,奖励分数生成模块,具体用于:确定图像中各个图像区域的类别;基于图像和各个图像区域的类别,确定比例信息,比例信息指示各个类别的图像区域在图像中的所占比例;基于用户输入文本和各个图像区域的类别、比例信息,确定局部信息分数。
33、在另一种可能的实现方式中,奖励分数生成模块,具体用于:基于比例信息,对用户输入文本和各个图像区域的类别的相似度进行加权,得到局部信息分数。
34、在另一种可能的实现方式中,奖励分数生成模块,具体用于:将图像作为图像标注模型的输入,图像标注模型对图像中的各个图像区域进行类别标注,输出图像中各个图像区域的类别;和/或将图像和各个图像区域的类别作为图像分割模型的输入,图像分割模型基于各个图像区域的类别对图像进行分割,输出比例信息;和/或将用户输入文本、各个图像区域的类别和比例信息输入预训练模型,预训练模型基于比例信息对用户输入文本和各个图像区域的类别的相似度进行加权,输出局部信息分数。
35、在另一种可能的实现方式中,奖励分数还与美学分数有关,美学分数指示图像与美学相关标准的一致性。
36、在另一种可能的实现方式中,文本扩充模块,具体用于:将用户输入文本作为提示生成器的输入,输出用户输入提示文本;将用户输入提示文本,作为大语言模型的输入,输出提示文本。
37、在另一种可能的实现方式中,奖励分数还用于指示提示文本和图像的相似度,以使文图生成模型基于奖励分数确定微调训练的训练集;其中,整体信息分数还用于指示图像的描述信息与提示文本的相似度,局部信息分数还用于指示图像的局部信息与提示文本的相似度。
38、第四方面,本技术实施例提供了一种文图生成装置,包括:获取模块,用于获取用户输入文本;文本扩充模块,用于将用户输入文本作为大语言模型的输入,输出多个提示文本;文图生成模块,用于将多个提示文本作为文图生成模型的输入,输出对应的多个图像;奖励分数生成模块,用于基于用户输入文本和多个图像,确定每个图像的奖励分数,奖励分数与整体信息分数和局部信息分数有关,整体信息分数指示图像的描述信息与用户输入文本的相似度,局部信息分数指示图像的局部信息与用户输入文本的相似度;以及基于多个图像的奖励分数,确定目标图像,目标图像包括奖励分数为目标图像分数的至少一个图像。
39、第五方面,本技术提供了一种云管理平台,包括:至少一个计算节点,该计算节点上部署有大语言模型和/或文图生成模型,该云管理平台用于实现上述方法。
40、第六方面,本技术提供了一种计算设备,包括存储器和处理器。存储器中存储有指令,当指令被处理器执行时,使得上述方法被实现。
41、第七方面,本技术提供了一种计算机可读存储介质,其上存储有计算机程序。当计算机程序在被处理器执行时,使得上述方法被实现。
42、第八方面,本技术提供了一种计算机程序产品,其包括有程序指令,程序指令当被计算机执行时使得计算机执行方法。
- 还没有人留言评论。精彩留言会获得点赞!