一种基于场景图的多模态医疗命名实体识别方法
本发明涉及命名实体识别,具体涉及一种基于场景图的多模态医疗命名实体识别方法。
背景技术:
1、信息提取(information extraction,ie)是自然语言处理(nlp)中的一项经典任务,涉及从非结构化文本数据中自动提取结构化信息。ie的目标是以结构化格式(如数据库或电子表格)提取和表示相关信息,以便进一步分析和使用。这项任务对各种应用至关重要,如信息检索、问题回答和文本分类。ie通常由两个子任务组成。命名实体识别(namedentity recognition,ner)和关系提取(re)。命名实体识别作为信息抽取任务的关键技术,旨在识别句子中存在的命名实体并预测其属于预定义实体类型的哪一种,如人(per)、位置(loc)和组织(org)。通过准确地提取和标记这些命名实体,以便它们可以被用于各种下游nlp应用,如信息检索、情感分析、机器翻译等等。随着社交媒体所包含的模态越来越多,研究人员想要利用图片信息来帮助ner模型更加准确的识别实体,因此采用多模态学习进行医疗命名实体识别的方法应运而生。
2、多模态命名实体识别(multi-model named entity recognition,mner)任务主要结合视觉和文本信息来识别和分类给定文本中的命名实体,它的主要目标就是识别{文本,图像}对中文本中所包含的命名实体并检测其实体类型,以提高nlp应用的准确性和效率。多模式医疗命名实体识别已经成为从异质文本和视觉数据中提取命名实体的研究热点。现有方法的典型方式是利用注意力机制从图像中捕捉视觉线索来提升文本表征,而不管文本和图像是否相关,这就存在着语义差距的问题,即文本语义特征和视觉背景特征之间的差距。如果文本和图像的特征是不相关的,这个问题将更具挑战性。事实上,与文本无关的视觉线索可能会给命名实体识别带来不确定甚至是负面的影响。
3、虽然目前已经有很多令人瞩目的成果,但是大多数方法只是从图片中简单的筛选有用的部分,并没有注意到句子和图像之间的局部细节,这种粗糙的处理方式在复杂的场景下是不能令人满意的。因为图片中不仅包含多个物体,还体现了不同物体之间的关系,而关系对于命名实体识别同样重要。因此,我们认为mner任务还存在以下挑战:一方面,图片可能不包含任何有用信息,因此很难来帮助文本找到有用的信息。一个好的方法应该帮助模型来识别图片中包含的视觉信息对文本的贡献有多大。而且在某些情况下,为了准确地识别和分类命名实体,可能需要图像或文本的上下文。例如,在包括一个人的图像中,可能需要知道这个人的位置或正在进行的活动,以准确地将其归类为一个命名实体。另一方面,想要将文本和图片中包含的信息融合到同一模态是一项很大的挑战。虽然许多将图片融合到文本中的神经网络模型以及被提出,但是我们对于多模态神经网络内部是如何交互以及该模型起作用的原因知之甚少。此外,文本和视觉信息可能非常不同,这使得有效地结合它们具有挑战性。例如,图像可能包含多个命名实体,其中一些可能不存在于附带的文本中。
技术实现思路
1、现有方法的流行方式是首先通过预训练好的目标检测器来识别区域性的视觉信息,之后通过一种融合方法来对文本和图像进行交互,这往往会受到模态不统一问题以及文本和图像之间的相关性问题的困扰。也就是说,文本和图像分别在各自的模态数据上进行训练的,因此很难将不同模态的信息进行统一的建模。此外,由于文本和图象不一定是相关的,因此如何评估图片的可用性是其中的关键。针对现有技术存在的问题,本发明提供一种基于场景图的多模态医疗命名实体识别方法,旨在利用场景图来从细粒度的方面对文本和图像的相似性进行评估并筛选图像中有效的信息用于之后的信息融合,最终提高模型的性能。
2、本发明提供的一种基于场景图的多模态医疗命名实体识别方法,包括以下步骤:
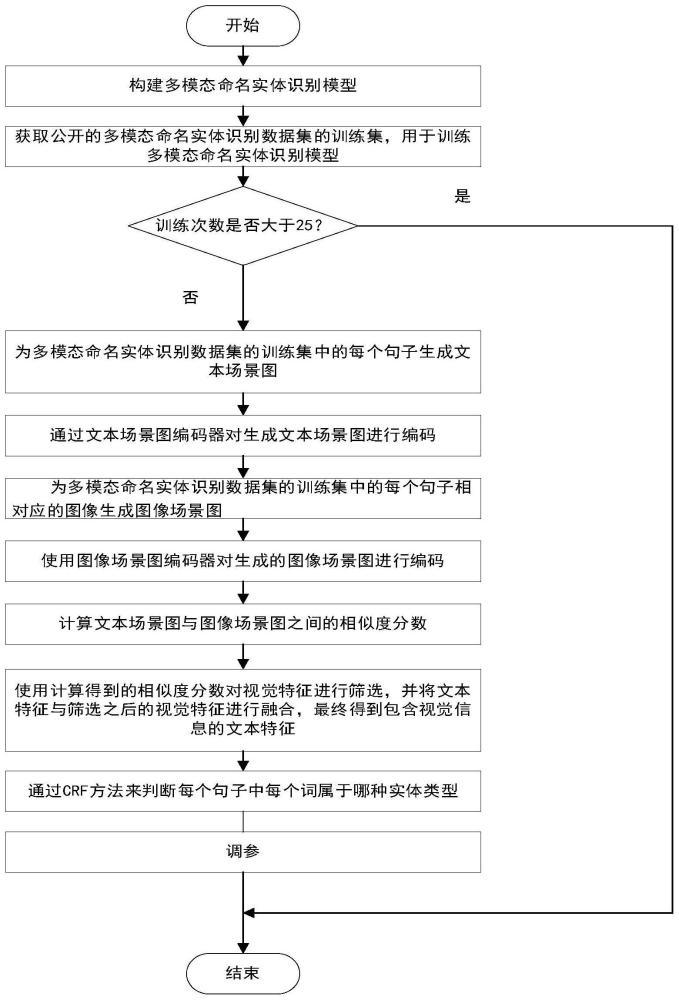
3、步骤1:基于神经网络构建多模态命名实体识别模型;
4、所述多模态命名实体识别模型,包含嵌入层、bi-gru编码器、faster rcnn、bilstm、图卷积网络、多头注意力机制、全连接层;所述多模态命名实体识别模型的输入为句子和句子所对应的图像,输出为句子中每个单词所属的实体类型;
5、步骤2:获取训练多模态命名实体识别模型的数据集,利用训练集来训练所述的多模态命名实体识别模型;具体表述为:
6、步骤2.1:为所述多模态命名实体识别数据集的训练集中的每个句子生成文本场景图;包括:
7、步骤2.1.1:对每个句子x={x1,...,xn}进行分词,并在开始位置加入句头开始标记[start],在结束位置加入句尾标记[end],得到的文本序列为其中,wi代表分词后句子中的第i个单词,no是分词序列的最大长度;
8、步骤2.1.2:通过依赖解析器将文本序列解析成句法依赖树;
9、步骤2.1.3:根据语言规则提取依赖树中的对象o1和关系r1,并将其映射成三元组来构成文本场景图g1,生成公式如下:
10、o1={oi|i∈[1,no]} (1)
11、r1={rij=[oi,oj]|i∈[1,no],j∈[1,no]} (2)
12、g1=(o1,r1) (3)
13、式中,oi表示文本序列中的第i个单词,oj表示文本序列中的第j个单词,rij表示oi和oj之间的关系,rij∈[1,nr],no表示文本序列的长度,nr表示关系的个数同时也是三元组的个数;
14、步骤2.2:通过文本场景图编码器对步骤2.1中生成文本场景图进行编码,所述文本场景图编码器包括一个嵌入层和两个bi-gru编码器;具体表述为:
15、步骤2.2.1:将步骤2.1.3中文本序列中的单词oi通过嵌入层编码成文本向量其中将oi转换为one-hot vector,表示单词oi的one-hot向量,wt表示嵌入层的参数矩阵;
16、步骤2.2.2:将步骤2.2.1中生成的文本向量通过一个bi-gru编码器进行编码,该编码器根据单词在句子中的位置来学习每个单词的特征,从而使得每个词都包含上下文的语义;具体过程如下:
17、
18、
19、其中,和分别表示两个方向的隐藏状态,no表示文本序列的长度;因此,路径上的每个单词节点都被编码为即场景图中的对象节点o1,hi表示第i个单词的特征,表示一个正向的gru模型,表示反向的gru模型;
20、步骤2.2.3:使用另一个bi-gru编码器将步骤2.1.3中生成的文本场景图中包含的nr个三元组编码成向量,并取每个关系三元组中最后一个隐藏状态作为该三元组的特征;具体过程如下:
21、
22、式中,rk表示第k个三元组;
23、步骤2.3:为训练集中的每个句子相对应的图像生成图像场景图;包括:
24、步骤2.3.1:使用faster rcnn预测图像中包含的对象的边界区域b={b1,...,bi,...,bt},bi表示第i个对象的信息,其中bi包含一个对象的图像特征向量fi和一个对象标签概率ii,t表示预设的每张图像被识别的对象数;
25、步骤2.3.2:使用bilstm为每个对象获取它的上下文表示,公式如下:
26、c=bilstm([fi;w1ii]i=1,...,t) (7)
27、其中,c=[c1,...,ci,...,ct],ci为第i个对象的隐藏状态,c为所有对象的上下文表示的集合,bilstm()表示一个bidirectional lstm模型,w1为一个参数矩阵;
28、步骤2.3.3:使用一个lstm和一个全连接层生成每个对象的预测标签,过程如公式所示:
29、
30、
31、其中,hi是lstm输出的隐藏状态,为第i个对象的预测标签,是上一个对象的预测标签,wo是一个二参数矩阵,argmax()表示取最大值;
32、步骤2.3.4:强化每个对象的上下文表示,公式如下;
33、
34、其中,d=[d1,...,di,...,dt],di为第i个对象的隐藏状态,w2是一个参数矩阵;
35、步骤2.3.5:预测每两个对象之间可能存在的关系pr;
36、
37、
38、其中,wh、wt和wr为参数矩阵,di、dj分别为第i个对象的隐藏状态、第j个对象的隐藏状态,fi,j为第i个对象和第j个对象的合并区域的图像特征向量,为拼接操作,是特定于头部和尾部标签的偏置向量,softmax()表示取最大值;
39、步骤2.3.6:将步骤2.3.3中预测得到的对象节点和步骤2.3.5中预测到的关系pr共同组成视觉场景图g2=(o2,r2),其中o2为对象节点的集合,r2为关系的集合;
40、步骤2.4:使用图像场景图编码器对步骤2.3中生成的图像场景图g2进行编码;该图像场景图编码器包含一个faster rcnn、三个嵌入层embedding layer和一个图卷积网络gcn,包括步骤如下:
41、步骤2.4.1:使用faster rcnn将图像场景图中的每个节点都编码为视觉特征向量,其中第a个对象节点的视觉特征向量用表示,第a个对象节点和第b个对象节点之间的关系节点的视觉特征向量用表示;
42、步骤2.4.2:使用两个嵌入层,分别将第a个对象节点的单词标签第a个对象节点和第b个对象节点之间的关系的单词标签编码为特征向量和公式如下:
43、
44、
45、其中,wo和wr表示嵌入层的参数矩阵;
46、步骤2.4.3:使用一个嵌入层统一视觉向量和单词标签向量的模态,该过程可以用如下公式表示:
47、
48、
49、其中,为嵌入层要训练的超参数,为新的对象节点的表示,为新的关系的表示;
50、步骤2.4.4:选择一个m层的图卷积网络gcn,将输入特征和编码成最终的视觉对象特征和视觉关系特征其中,每个对象节点的向量通过自身来增强,而关系的向量通过它相邻的对象节点来更新;
51、
52、
53、其中,go和gr表示全连接层,初始隐藏状态被视为融合特征,即和然后,gcn输出视觉特征图的编码,其中包含两种类型的顶点,即和q-1表示上一个隐藏状态;
54、步骤2.5:计算文本场景图与图像场景图之间的相似度分数;具体表述为:
55、步骤2.5.1:计算no个文本对象与nv个视觉对象之间的相似度;具体过程如下:
56、
57、其中,hi中i的取值范围为[1,no],中a的取值范围为[1,nv],po表示文本场景图和图像场景图中对象之间相似度;
58、步骤2.5.2:计算nr个文本关系与nm个视觉关系之间的相似度;具体过程如下:
59、
60、其中,k为文本场景图中的关系数(即),范围为[1,nr],u为视觉场景图中的关系数,范围为[1,nm],pr表示文本场景图和图像场景图中关系之间相似度;
61、步骤2.5.3:计算文本与图像之间的相似度分数p,其中p=po+pr;
62、步骤2.6:使用步骤2.5.3中计算得到的相似度分数p对步骤2.4.1中的视觉特征向量进行筛选,并将文本特征与筛选之后的视觉特征进行融合,最终得到包含视觉信息的文本特征he;具体表述为:
63、步骤2.6.1:将文本序列作为bert的输入,得到文本的特征向量te,其中e∈[1,no];
64、步骤2.6.2:将相似度分数p乘到36个视觉特征向量上,得到新的视觉特征向量然后通过如下公式来将文本特征与视觉特征进行融合,得到更新后的文本的特征te表示:
65、
66、其中,表示按元素相加,te为bert的输出,att(·)表示多头注意机制(multi-head attention);
67、步骤2.6.3:通过全连接层得到最终的文本特征he,如以下公式所示;
68、he=wete+be (22)
69、其中,we和be是可训练的参数矩阵;
70、步骤2.7:通过crf方法来判断每个句子中每个词的实体类型,其中标签序列的预测定义如下所示:
71、
72、其中,x是文本所对应的单词序列,y是每个词所对应的正确的标签,f(x,y)通过转换和发射来实现,是句子中每个单词可能的标签所组成的序列,是句子中每个单词可能的标签所组成的序列中的一种,p(y|x)是预测正确的概率;
73、步骤2.8:对模型参数进行调整,使用交叉熵损失函数来计算损失值,然后将损失值反向传递给模型,模型利用损失值结合机器学习方法进行参数调整;
74、步骤2.9:按照预设的模型训练次数,重复执行步骤2.1至步骤2.8,直至达到预设的模型训练次数,完成多模态命名实体识别模型的训练;
75、步骤3:针对待预测的文本、图像对数据,利用训练后的多模态命名实体识别模型输出实体类型的预测结果。
76、本发明的有益效果是:
77、首先,图像中的信息不一定是有用的。为了缓解此问题,本发明分别为文本和图像生成场景图,然后计算两个场景图之间的相似程度,并将计算得到的相似度用于筛选图像中检测出来的实体,可以有效过滤掉图像中那些没用的信息,以便于之后更好的利用那些有用的信息。
78、其次,文本和图像的融合也是mner任务的一大难点。为此,本发明使用多头注意力机制将文本和图像进行融合,旨在通过被筛选过的视觉信息来作为文本的提示、降低模型对图像中不相关对象的理解偏差。
79、采用本发明提出的基于场景图的多模态医疗命名实体识别方法,可以从更细粒度的层次衡量文本和图像之间的相似程度并且可以有效的筛选图片中有用的图像信息,应用在多模态医疗系统上可以更好的利用图像信息,从而更准确地识别文本中的实体。
- 还没有人留言评论。精彩留言会获得点赞!