一种MSWI过程CO排放浓度异构集成预测模型构建方法
本发明涉及城市固废焚烧,特别是涉及一种mswi过程co排放浓度异构集成预测模型构建方法。
背景技术:
1、能够表征mswi过程的燃烧状态的有毒污染物一氧化碳(co)可作为城市固废焚烧(mswi)过程的副产品而产生。研究表明,co与到目前为止仍然难以实时检测的“世纪之毒”二噁英(dxn)直接相关。显然,作为mswi过程中的需要重点关注的运行指标,对co排放浓度进行有效预测对实现污染减排的优化控制非常必要。工业大数据的涌现使得机器学习和深度学习建模方法得到飞速发展。因此,使用人工智能建模技术预测mswi过程的co排放浓度已成为切实可行的解决方案。这些数据驱动模型(dd模型)是通过历史数据集建立自变量(输入特征)和因变量(目标变量或输出)之间的映射关系。通常,dd模型需要大量的数据样本,然而由于实际数据集往往存在各种问题,如样本不足、覆盖范围不完整等,模型性能易受到影响。机理驱动模型(md模型),也被称为白盒模型,依赖于工业过程内部机理的知识,并使用动量、热量、质量和反应动力学等原理。然而,由于复杂工业过程反应机理的复杂性和不确定性,建立合适的md模型是一项具有挑战性的任务。因此,设计一种mswi过程co排放浓度异构集成预测模型构建方法是十分有必要的。
技术实现思路
1、本发明的目的是提供一种mswi过程co排放浓度异构集成预测模型构建方法,能够实现mswi过程co排放浓度异构集成预测模型的构建,实现了co排放浓度的预测,便于使用。
2、为实现上述目的,本发明提供了如下方案:
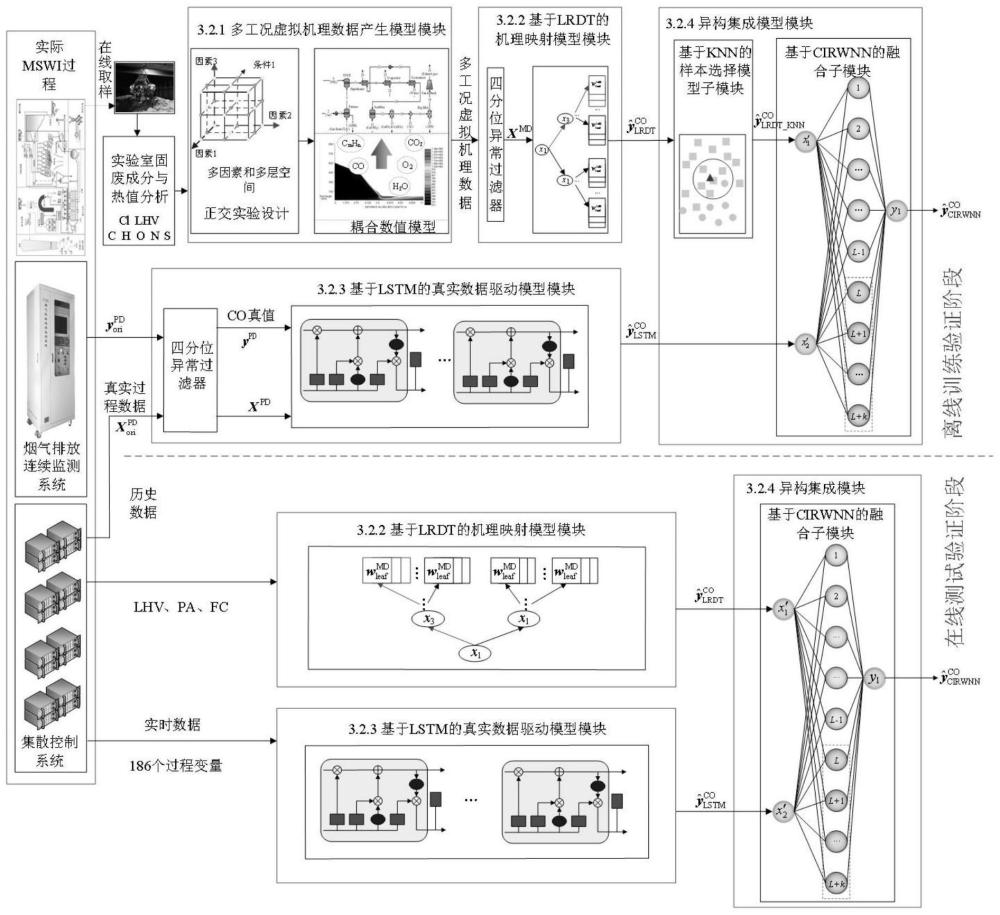
3、一种mswi过程co排放浓度异构集成预测模型构建方法,包括如下步骤:
4、步骤1:进行离线训练验证;
5、步骤2:进行在线测试验证。
6、可选的,步骤1中,进行离线训练验证,具体包括如下步骤:
7、步骤101:通过耦合flic和aspen plus的数值仿真构建多工况机理模型,获取虚拟机理数据;
8、步骤102:基于虚拟机理数据,通过lrdt算法构建得到机理映射模型;
9、步骤103:基于lstm算法构建真实历史数据驱动模型;
10、步骤104:构建基于knn的样本选择子模型及基于cirwnn的融合子模型,将机理映射模型的输出输入基于knn的样本选择子模型,将真实历史数据驱动模型的输出及基于knn的样本选择子模型的输出输入基于cirwnn的融合子模型。
11、可选的,步骤101中,通过耦合flic和aspen plus的数值仿真构建多工况机理模型,获取虚拟机理数据,具体为:
12、通过flic模拟mswi中的固相燃烧,通过aspen plus模拟mswi中的气相燃烧,构建msw燃烧模型,由包含质量连续性方程、动量方程和能量方程的基本守恒方程和包含水分蒸发、挥发物释放、挥发物燃烧和焦炭燃烧四个过程的msw燃烧速率方程两部分组成;
13、其中,msw燃烧的质量连续性方程表示为:
14、
15、
16、式中,ρg为气体的密度,φ为床层空隙率,vg和vs为气体速度和固体颗粒速度,vb为移动边界处的速度,ss,g为固体转化为气体的速率,ρsb为多孔介质的密度,ss为质量源项,多孔介质密度ρsb为:
17、ρsb=ρs(1-φ) (3)
18、式中,ρs为msw的固体密度;
19、燃烧时的动量方程为:
20、
21、
22、式中,pg为气体压力,f(v)为多孔介质中固体对流体流动的阻力,σ和τ分别为床层中的法向应力张量和切向应力张量,a为随机扰动;
23、能量方程为:
24、
25、
26、式中,hg和hs分别为气体焓和固体焓,λg为热扩散系数,tg和ts分别为气体温度和固体温度,sa为颗粒表面积,hs'为对流换热系数,qh表示气体的热损益,λs为有效导热系数,由材料的导热系数λs0与粒子随机运动引起的热传递λsm相加得到,qr为辐射热流密度,qsh为固相热源项,λg计算公式为:
27、λg=λ0+0.5dpvgρgcpg (8)
28、式中,λ0为有效热扩散系数,dp为颗粒直径,cpg为混合气体的热容;
29、水分蒸发速率表示为:
30、
31、式中,revp为水分蒸发反应速率,hs为对流传质系数,cw,s和cw,g为固相和气相水浓度,hevp为固体水分蒸发热,qcr为对流和辐射传热固体吸收的热量,表示为:
32、
33、式中,sa为粒子表面积,εs为固体发射率/系统发射率,σb为玻尔兹曼辐射常数,为环境温度;
34、燃烧炉排上包括挥发物的释放和燃烧两个过程,假设释放的气态产物由碳氢化合物、co、co2、h2o和炭组成,为:
35、msw→volatile(cmhn,co,co2,h2o)+char (11)
36、msw中的挥发物与周围空气混合后迅速燃烧,燃烧反应为:
37、
38、msw颗粒挥发释放后形成焦炭,焦炭气化的主要产物为co和co2,表示为:
39、c(s)+αo2→2(1-α)co+(2α-1)co2 (13)
40、式中,α是0.5-1范围内的正常数;
41、得到msw床上方的烟气组分为碳氢化合物、co、co2、o2、h2、h2o和n2;
42、将碳氢化合物假定为ch4,将flic固相燃烧产生的气体和预热过的二次空气引入炉膛,进行气相燃烧反应,反应温度范围850-1150℃,反应过程为:
43、
44、在炉膛出口,采用选择性非催化还原处理烟气,反应过程为:
45、
46、换热阶段,烟气经过过热器、蒸发器、省煤器,温度降至200℃,烟气进入脱硫装置,脱除酸性化合物,具体反应过程为:
47、
48、将活性炭喷入烟气管道中吸附重金属和dxn,烟气进入袋式除尘器,净化后的烟气通过烟囱排放到大气中;
49、基于msw燃烧模型,采用正交实验设计,获取能够表征多运行工况的虚拟机理数据dmd,选取10个因素,包括fc、炉排转速、一次气流、二次气流、三次气流、四次气流、含水率、cho元素比、粒度、颗粒混合系数,每个因素设为5个水平,即10因素5水平的正交试验设计,得到49种工况,在49种工况的基础上,再进行6因素5水平的正交试验设计,共42种工况,共得到2058种工况。
50、可选的,步骤102中,基于虚拟机理数据,通过lrdt算法构建得到机理映射模型,具体为:
51、将原始多工况虚拟机理数据记为此处选择lhv、pa和fc作为co机理映射模型的输入,并将建模数据表示为dmd∈2058×(3×1);
52、采用移动窗口qaf法去除异常数据点,数据的长度为固定采样时间窗设为twind,对于时间窗口twind内的数据,采用四分位数法去除异常值的规则为:
53、
54、式中,xab表示异常数据点,xub和xdb表示上下边界,q1/4(·)和q3/4(·)是x的第1个和第3个四分位数,若时间窗口内的数据点大于xub或小于xub,则认为该数据点为异常点,则将其删除;
55、将通过qaf处理后得到的数据记为采用多输入单输出的lrdt算法构建机理映射模型;
56、机理映射模型由特征选择和线性回归两部分组成,和表示第1、2和3个非叶节点,和是第1和第(t/2)个多输出叶节点,为(t/2)路由节点的特征集,将虚拟机理数据改写为其中,建模过程为:
57、根据特征每个非叶节点将数据集分成两个子节点,即左节点和右节点表示为:
58、
59、式中,和分别表示和中的样本个数,为第i个特征向量,为向量的值;
60、将mse的单次输出表示为:
61、
62、式中,表示mse的损失函数值,(n,i)表示第u次迭代的虚拟机理数据集第n个样本的第i个特征值;
63、将机理映射模型的第t个叶节点的输入数据记为第t个叶节点的线性回归表示为:
64、
65、将权重wlrdt赋值给lrdt模型以提高模型的性能,该权重表示为:
66、
67、式中,flrdt(·)为机理映射模型,wlrdt表示flrdt(·)的权重;
68、基于迭代tikhonov正则化对模型求解,得到:
69、
70、式中,为权向量,b为残差向量,得到:
71、
72、得到机理映射模型为:
73、
74、可选的,步骤103中,基于lstm算法构建真实历史数据驱动模型,具体为:
75、基于lstm算法构建真实历史数据驱动模型,其中,表示第n个样本输入,hn-1和cn-1分别表示第n-1个样本lstm隐含层输出和状态信息并作为下一个样本的输入,hn和cn分别表示第n个样本lstm输出和状态信息,在初始样本计算时,设置n=1,hn-1=0,建模过程为:
76、设定空集cn为记忆单元,遗忘门fn决定记忆单元cn上一个样本输出值被输出到本次输入的比例,遗忘门输出fn计算为:
77、
78、fn=fn cn (26)
79、式中,uf和wf分别对应hn-1和的权重,bf为偏置,σ(·)表示sigmoid激活函数,表示hadamard积;
80、计算当前输入状态的候选值为:
81、
82、式中,uc和wc分别对应hn-1、的权重,bc为偏置,tanh(·)表示tanh激活函数;
83、计算输入门in,用于控制第n个样本输入存储到记忆单元cn的比例,输入门输出in如下:
84、
85、
86、式中,ui和wi分别对应hn-1和的权重,bi为偏置;
87、将所得值储存到记忆单元cn,为:
88、cn=fn+in (30)
89、此处第一个样本输出cn的值为in,即cn=in,fn=0;
90、计算第n个样本的隐含层输出hn,计算输出门on控制记忆单元cn中存储的值可被输出比例,为:
91、
92、hn=on tanh(cn) (32)
93、式中,uo和wo分别对应hn-1和的权重,bo为偏置;
94、计算第n个样本的输出值为:
95、
96、式中,wout为隐含层对应的权重;
97、剩余样本输入时,循环上述过程,输出为为:
98、
99、可选的,步骤104中,构建基于knn的样本选择子模型及基于cirwnn的融合子模型,将机理映射模型的输出输入基于knn的样本选择子模型,将真实历史数据驱动模型的输出及基于knn的样本选择子模型的输出输入基于cirwnn的融合子模型,具体为:
100、构建基于knn的样本选择子模型,随机选择i个集群作为初始质心
101、根据样本与质心之间的加权欧氏距离得到:
102、
103、式中,ci表示第i个质心,代表的第n个样本;
104、利用类间样本的均值修正ci的质心,得到:
105、
106、式中,表示该聚类中第i个样本数量;
107、对质心进行循环重置,最终得到全部质心,上述过程表示为:
108、
109、式中,δts为评价指标riter的阈值,iter表示迭代次数;
110、选择与上述质心最近邻的样本然后再求均值,得到:
111、
112、式中,k为超参数;
113、构建基于cirwnn的融合子模型,以机理映射模型的输出及真实历史数据驱动模型的输出为输入,其中,机理映射模型的输出需要经过基于knn的样本选择子模型进行选择,最终得到异构集成模型的输出,其中,在离线训练验证阶段中,异构集成模型由基于knn的样本选择子模型及基于cirwnn的融合子模型共同构成;
114、给定训练数据集为
115、输入权值ωin和偏置值b为均匀分布随机生成,设置为[-μ,μ]和μ>0,系统输入为假设隐藏层神经元为l-1,则预测输出表示为:
116、
117、式中,为带有l-1个隐藏层神经元的基本rwnn模型,ψ(·)表示激活函数,ωout为l-1隐藏层神经元的权值;
118、使用最小二乘算法获得输出权值ωout,为:
119、
120、式中,φl-1(·)为隐藏层输出的矩阵;
121、在隐层神经元增量过程中,约束不等式为:
122、
123、式中,<·,·>表示标量积,r和γl为正常数;
124、当0<r<1和时,和φl的计算为:
125、
126、
127、隐藏层的新输出为[φl-1(·),φl(·)],计算输出权值ωout;
128、基于上述约束,cirwnn进行增量学习,直到学习精度达到标准,最终共得到基于cirwnn的融合子模型为:
129、
130、可选的,步骤2中,进行在线测试验证,具体为:
131、在在线测试验证过程中,机理映射模型以lhv、pa和fc为输入,真实历史数据驱动模型以过程变量为输入,分别得到子模型预测值与将其输入基于cirwnn的融合子模型中,得到输出为:
132、
133、根据本发明提供的具体实施例,本发明公开了以下技术效果:本发明提供的mswi过程co排放浓度异构集成预测模型构建方法,该方法包括进行离线训练验证及进行在线测试验证,其中,进行离线训练验证包括通过耦合flic和aspen plus的数值仿真构建多工况机理模型,获取虚拟机理数据,基于虚拟机理数据,通过lrdt算法构建得到机理映射模型,基于lstm算法构建真实历史数据驱动模型,构建基于knn的样本选择子模型及基于cirwnn的融合子模型,将机理映射模型的输出输入基于knn的样本选择子模型,将真实历史数据驱动模型的输出及基于knn的样本选择子模型的输出输入基于cirwnn的融合子模型,在在线测试验证阶段,通过集成基于lrdt的机理映射模型和基于lstm的数据驱动模型实现co排放浓度的在线预测,最终,通过某工厂的实用案例研究,验证本发明的有效性及合理性。
- 还没有人留言评论。精彩留言会获得点赞!