考虑用户人格特质与主题偏好的社区专家推荐方法和系统
本发明涉及任务推荐,特别涉及考虑用户人格特质与主题偏好的社区专家推荐方法和系统。
背景技术:
1、问答社区的发展势不可当,以“提问-解答”的形式,给用户提供了绝佳的知识分享平台。
2、大量用户直接带来大量待解答的问题,给提问者和解答者都造成了一定困扰:一方面,相当大一部分待解答的问题没有被及时解答或有效解答,而是堆积在平台中,并且随着时间流逝,即使得到解答了,提问者也不再关注该问答的内容和质量,这一情况直接导致了提问者的用户体验感降低,打击了提问者再次提问的积极性;另一方面,解答者面对堆积如山的问题,需要花费大量时间和精力挑选感兴趣且有能力回答的问题进行解答,难免容易产生倦怠,从而降低进行知识分享行为的意愿和对该问答社区的评价,以至于该问答社区中的问题得不到解答的可能性增加,更多待解答问题被积压,形成了恶性循环,因此,如何为亟待得到解答的问题推荐回答意愿和作答能力都匹配的专家,使之得到及时的高质量解答,已成为问答社区促进知识分享,提高服务质量,提升用户粘性,应对市场竞争的关键突破口。
3、现有的问答社区专家推荐方法存在以下缺陷和不足:对自然语言处理、深度学习等技术领域的算法的应用使得所用算法的功能如同“黑盒子”,除了用户主题兴趣概率的结果,不能提供更多额外信息,可解释性有待提高;仅关注于显式文本信息进行特征提取,欠缺对专家用户和问题之间存在的更深层次关系和潜在的偏好因素的考虑,专家推荐效果有待提高。已有研究表明,性格特质对于问答社区中用户的知识贡献意愿和行为有直接影响,但这一层次关系在现有的问答社区专家推荐方法中并未体现,从用户性格特质出发的用户主题偏好情况尚未被纳入现有的问答社区专家推荐方法的考虑中。
技术实现思路
1、本发明的目的在于提供考虑用户人格特质与主题偏好的社区专家推荐方法和系统,克服了现有技术的不足,解决了上述问题。
2、为解决上述问题,本发明所采取的技术方案如下:
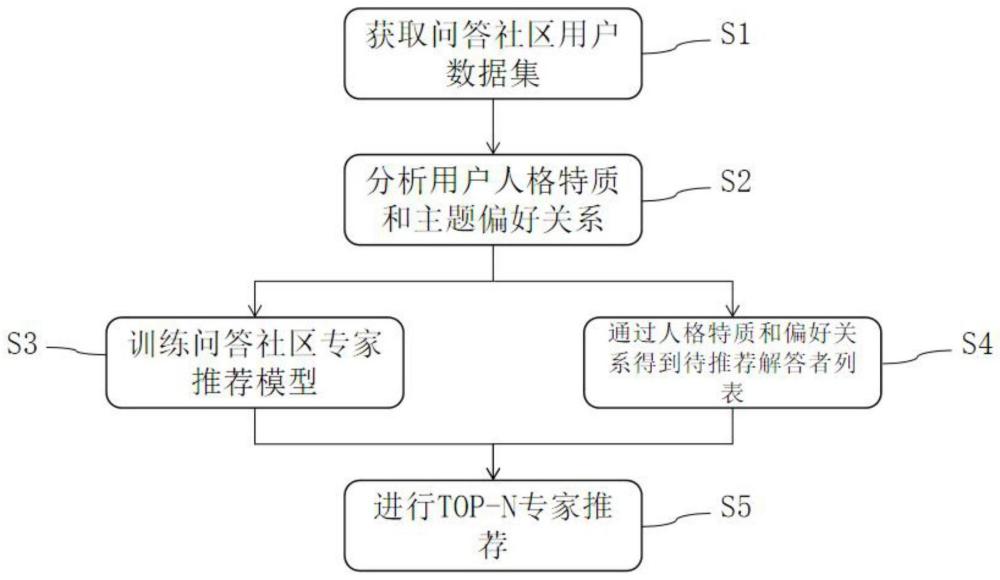
3、考虑用户人格特质与主题偏好的社区专家推荐方法,所述推荐方法包括以下步骤:
4、s1:获取问答社区用户数据集;
5、所述数据集包括用户回答过的问题文本、用户回答文本、用户回答时间和回答所获点赞数,并对这些数据集进行预处理,划分成训练集以及测试集;
6、s2:分析用户人格特质和主题偏好关系;
7、通过问答社区用户数据集中训练集的用户回答文本数据和对应的问题文本,分析得到不同人格特质用户群的主题偏好,从而可知用户人格特质与主题偏好关系;
8、s3:训练问答社区专家推荐模型;
9、根据预处理后的用户历史回答数据训练考虑用户人格特质与主题偏好关系的问答社区专家推荐模型;
10、s4:通过人格特质和偏好关系得到待推荐解答者列表;
11、由不同人格特质用户群对问题的主题偏好情况与待推荐问题主题分布的匹配情况,得到待推荐解答者列表;
12、s5:进行top-n专家推荐;
13、基于训练好的专家推荐模型,对测试集中待推荐问题在待推荐解答者范围内进行top-n专家推荐。
14、优选的,所述s1中获取问答社区用户数据集的方法为:
15、s11:从问答社区上爬取所有用户最近一段时间历史回答数据,包括用户id、回答对应的问题内容、回答的内容、回答时间、回答赞同数等;
16、s12:对获取的问答社区用户历史回答数据进行预处理,得到问答社区用户数据集;
17、其中,数据预处理包括数据筛选、数据清洗、数据合并以及去停用词并分词;
18、(1)所述数据筛选为剔除匿名回答指向的回答数据,筛选出回答问题大于等于m1个的用户,剔除回答的内容不可见或回答时间、回答赞同数等关键特征缺失的回答数据,其中m1为预设的阈值,根据实际需要进行设置;
19、(2)所述数据清洗为对列表中重复的回答数据进行去重,剔除回答列表中的异常值;
20、(3)所述数据合并为将回答数据根据用户合并为用户回答文本,对应回答时间保留最近回答时间,对应点赞数保留最高点赞数;
21、(4)所述去停用词并分词为去除问题文本中的标点符号和停用词,并进行jieba分词,将其分割为词并转换成向量,抽取词的元组,再将每个元组转换成向量;
22、s13:将问答社区用户数据集按照时间顺序划分为训练集、测试集。
23、优选的,所述s2中分析用户人格特质和主题偏好关系的方法为:
24、s21:对问答社区用户数据集中训练集的用户回答文本数据和对应的问题文本进行分析,得到用户在大五人格中各项指标的分布,以五维向量(o,c,e,a,n)表示;
25、其中大五人格特质为:开放性、尽责性、外向性、宜人性和神经质性;
26、s22:对所有用户根据人格特质数据进行k-means聚类,得到不同人格特质用户群;
27、s23:将各用户回答过的问题文本合并为用户群对应的问题文本,并以lda模型进行主题提取,以θu,k表示主题分布,u其中代表用户群,k代表主题,得到不同人格特质用户群对问题的主题偏好。
28、优选的,所述s4中通过人格特质和偏好关系得到待推荐解答者列表的方法为:
29、s41:以lda模型对训练集中的待推荐问题进行分析,得到待推荐问题的主题分布θj,k,其中j代表问题,k代表主题;
30、s42:对待推荐问题的主题分布θj,k和用户群问题文本的主题分布θu,k进行相似度比对,将待推荐问题对应到相似度最为相近的问题群,映射到该问题群对应的用户群,将对应用户列表作为待推荐解答者列表;
31、其中计算主题分布的相似度标准为kl距离,具体如下:
32、
33、优选的,所述s5中进行top-n专家推荐的方法为:
34、s51:通过专家推荐模型对待推荐解答者列表中的用户进行匹配度计算,具体如下:
35、m(uij)=αsij+βai+γpi;
36、
37、
38、其中,m(uij)表示用户i对于新问题j的匹配度值,sij表示用户i回答过的问题文本与新问题j的相似度值,ai表示用户i的活跃度值,t0表示当天日期,ti表示用户i最近一次回答问题时间,pi表示用户i的专业度值,pi表示用户i在聚类后所属类中的最高点赞数量,maxp表示待推荐解答者列表中所有用户在聚类后所属类中的最高点赞数量,α表示相似度值可调节的参数,β表示活跃度值可调节的参数,γ表示专业度值可调节的参数,以训练集中待推荐问题的匹配值为真实值,通过构建损失函数lost,运用五折交叉验证训练α,β,γ使lost收敛,取α,β,γ的平均值作为最终结果
39、s52:通过待推荐解答者列表中用户的匹配度,进行待推荐解答者排序;
40、s53:根据排序结果,选出匹配度最高的top-n个结果,进行top-n专家推荐。
41、考虑用户人格特质与主题偏好的社区专家推荐系统,所述推荐系统具体包括:
42、用户数据集获取模块,用于获取问答社区用户数据集;
43、所述数据集包括用户回答过的问题文本、用户回答文本、用户回答时间和回答所获点赞数,并对这些数据集进行预处理,划分成训练集以及测试集;
44、用户人格特质和主题偏好关系分析模块,用于分析用户人格特质和主题偏好关系;
45、通过问答社区用户数据集中训练集的用户回答文本数据和对应的问题文本,分析得到不同人格特质用户群的主题偏好,从而可知用户人格特质与主题偏好关系;
46、问答社区专家推荐模型训练模块,用于训练问答社区专家推荐模型;
47、根据预处理后的用户历史回答数据训练考虑用户人格特质与主题偏好关系的问答社区专家推荐模型;
48、待推荐解答者列表模块,用于通过人格特质和偏好关系得到待推荐解答者列表;
49、由不同人格特质用户群对问题的主题偏好情况与待推荐问题主题分布的匹配情况,得到待推荐解答者列表;
50、top-n专家推荐模块,用于进行top-n专家推荐;
51、基于训练好的专家推荐模型,对测试集中待推荐问题在待推荐解答者范围内进行top-n专家推荐。
52、优选的,所述用户数据集获取模块的获取方法为:
53、s11:从问答社区上爬取所有用户最近一段时间历史回答数据,包括用户id、回答对应的问题内容、回答的内容、回答时间、回答赞同数等;
54、s12:对获取的问答社区用户历史回答数据进行预处理,得到问答社区用户数据集;
55、其中,数据预处理包括数据筛选、数据清洗、数据合并以及去停用词并分词;
56、(1)所述数据筛选为剔除匿名回答指向的回答数据,筛选出回答问题大于等于m1个的用户,剔除回答的内容不可见或回答时间、回答赞同数等关键特征缺失的回答数据,其中m1为预设的阈值,根据实际需要进行设置;
57、(2)所述数据清洗为对列表中重复的回答数据进行去重,剔除回答列表中的异常值;
58、(3)所述数据合并为将回答数据根据用户合并为用户回答文本,对应回答时间保留最近回答时间,对应点赞数保留最高点赞数;
59、(4)所述去停用词并分词为去除问题文本中的标点符号和停用词,并进行jieba分词,将其分割为词并转换成向量,抽取词的元组,再将每个元组转换成向量;
60、s13:将问答社区用户数据集按照时间顺序划分为训练集、测试集。
61、优选的,所述用户人格特质和主题偏好关系分析模块的分析方法为:
62、s21:对问答社区用户数据集中训练集的用户回答文本数据和对应的问题文本进行分析,得到用户在大五人格中各项指标的分布,以五维向量(o,c,e,a,n)表示;
63、其中大五人格特质为:开放性、尽责性、外向性、宜人性和神经质性;
64、s22:对所有用户根据人格特质数据进行k-means聚类,得到不同人格特质用户群;
65、s23:将各用户回答过的问题文本合并为用户群对应的问题文本,并以lda模型进行主题提取,以θu,k表示主题分布,u其中代表用户群,k代表主题,得到不同人格特质用户群对问题的主题偏好。
66、优选的,所述待推荐解答者列表模块的得到方法为:
67、s41:以lda模型对训练集中的待推荐问题进行分析,得到待推荐问题的主题分布θj,k,其中j代表问题,k代表主题;
68、s42:对待推荐问题的主题分布θj,k和用户群问题文本的主题分布θu,k进行相似度比对,将待推荐问题对应到相似度最为相近的问题群,映射到该问题群对应的用户群,将对应用户列表作为待推荐解答者列表;
69、其中计算主题分布的相似度标准为kl距离,具体如下:
70、
71、优选的,所述top-n专家推荐模块的推荐方法为:
72、s51:通过专家推荐模型对待推荐解答者列表中的用户进行匹配度计算,具体如下:
73、m(uij)=αsij+βai+γpi;
74、
75、
76、其中,m(uij)表示用户i对于新问题j的匹配度值,sij表示用户i回答过的问题文本与新问题j的相似度值,ai表示用户i的活跃度值,t0表示当天日期,ti表示用户i最近一次回答问题时间,pi表示用户i的专业度值,pi表示用户i在聚类后所属类中的最高点赞数量,maxp表示待推荐解答者列表中所有用户在聚类后所属类中的最高点赞数量,α表示相似度值可调节的参数,β表示活跃度值可调节的参数,γ表示专业度值可调节的参数,以训练集中待推荐问题的匹配值为真实值,通过构建损失函数lost,运用五折交叉验证训练α,β,γ使lost收敛,取α,β,γ的平均值作为最终结果
77、s52:通过待推荐解答者列表中用户的匹配度,进行待推荐解答者排序;
78、s53:根据排序结果,选出匹配度最高的top-n个结果,进行top-n专家推荐。
79、本发明与现有技术相比较,具有以下有益效果:
80、本发明考虑了性格特征对知识分享意愿和行为的直接影响,以大五人格理论为理论指导,根据问答社区专家推荐的已有研究和问答社区的可用信息,分析解答者人格特质与主题偏好的关系,补充了在问答社区专家推荐中考虑用户性格因素的研究视角。
81、本发明采用隐性方法识别、分析解答者发布的文本,以得到解答者的大五人格特质分布作为性格参数,避免了以调查问卷等获取性格参数的显性方法对性格参数结果所造成的侵入性和耗时长的问题,突破了现有的问答社区专家推荐方法仅关注于显式文本信息进行特征提取的局限,对问答社区中的可用信息进行了内部复杂特征的深度捕捉。
82、本发明基于用户所属的不同人格特质用户群,进行用户人格特质与主题偏好关系的分析,实现了对用户个人主题偏好的预测,能够有效的突破用户的信息茧房,给用户带来更全面的推荐,启发用户扩大知识分享行为的参与范围,提升用户在问答社区的体验感。
83、本发明充分考虑了现实情境,不仅关注了用户的主题偏好情况和待推荐问题主题分布的匹配情况,反映了用户对该问题的感兴趣程度,而且考虑了用户的专业度和活跃度,保证了推荐对象既具备回答该问题的意愿,而且是有作答能力的专家,能够及时处理推荐结果,提供高质量回答,从而提高专家推荐的有效性。
- 还没有人留言评论。精彩留言会获得点赞!