一种电网风险文本分词方法和装置与流程
本发明属于电网,具体涉及一种电网风险文本分词方法和装置。
背景技术:
1、电力领域电网风险停送电信息是及时实施线路运维的重要依据。提取其关键信息是实现输电线路智能化运维的关键环节,提取关键分词信息需要对其进行文本分词,由于电力领域中文文本通常包含大量专有词汇,这使得对其进行分词时往往效果不佳。
2、电力领域中文文本有其专业领域特殊性,因此需对电力领域专有词汇进行大规模训练,使之更适合在该领域进行电网风险文本分词。电网风险文本数据这类非结构数据包含大量运行经验,对其进行分析可为电网运行决策提供基础数据支持,也为后续电力文本挖掘、知识图谱构建词级等词级语料电力领域自然语言处理任务提供基础数据。
3、然而现有电网风险文本分词没有统一标准,对于歧义词等的切分效果不好,无法得到良好的分词结果。
技术实现思路
1、有鉴于此,本发明旨在提供电网风险文本分词方法和装置,用于对电网风险停送电信息进行分词处理,以得到准确的分词结果。
2、为了解决上述技术问题,本发明提供以下技术方案:
3、第一方面,本发明提供了一种电网风险文本分词方法,包括如下步骤:
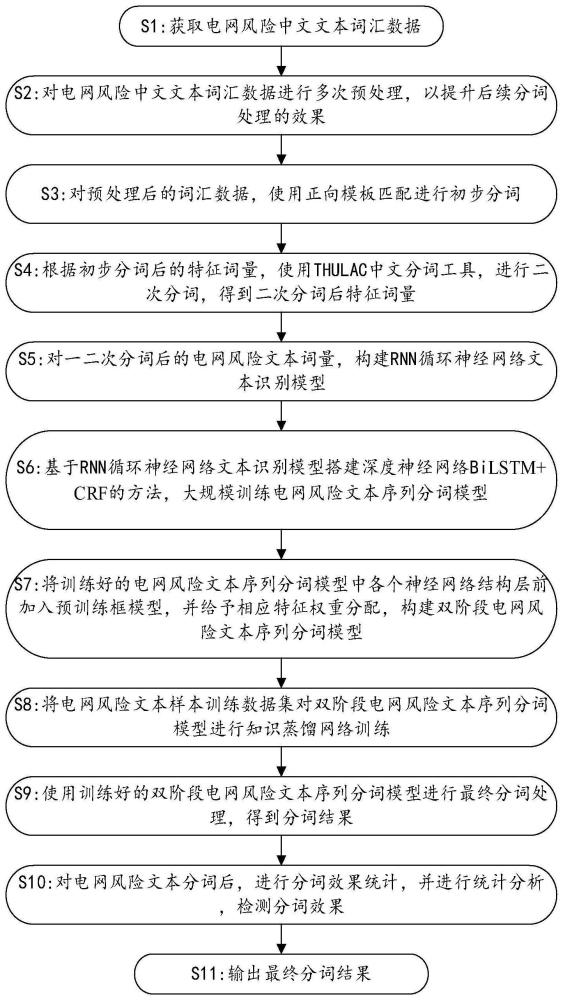
4、获取电网风险中文文本词汇数据;
5、对电网风险中文文本词汇数据进行多次预处理,以提升后续分词处理的效果;
6、对预处理后的词汇数据,使用正向模板匹配进行初步分词;
7、根据初步分词后的特征词量,使用thulac中文分词工具,进行二次分词,得到二次分词后特征词量;
8、对一二次分词后的电网风险文本词量,构建rnn循环神经网络文本识别模型;
9、基于rnn循环神经网络文本识别模型搭建深度神经网络bilstm+crf的方法,大规模训练电网风险文本序列分词模型;
10、将训练好的电网风险文本序列分词模型中各个神经网络结构层前加入预训练框模型,并给予相应特征权重分配,构建双阶段电网风险文本序列分词模型;
11、将电网风险文本样本训练数据集对双阶段电网风险文本序列分词模型进行知识蒸馏网络训练;
12、使用训练好的双阶段电网风险文本序列分词模型进行再次分词处理,得到分词结果;
13、对电网风险文本分词后,进行分词效果统计,并进行统计分析,检测分词效果;
14、输出最终分词结果。
15、进一步的,对电网风险中文文本词汇数据进行多次预处理,具体包括:
16、对获得的电网风险中文文本词汇数据进行第一预处理,增加电网风险信息训练数据的多样性;
17、对经过第一预处理的词汇数据进行第二预处理,去除词汇数据中的无意义词,简化词汇数据,以保留有效的词汇数据;
18、对经过第二预处理的词汇数据进行第三预处理,对词汇数据进行词性标注。
19、进一步的,在词性标注中,将代词标注为r、并列连词标注为c、助词标注为u、语气词标注为y、数词标注为m、量词标注为q。
20、进一步的,在使用深度学习bilstm+crf的方法中,bilstm为两个lstm倒置组件模型,该模型的更新和输出公式如下:
21、lstm从前到后更新公式:
22、
23、lstm从后到前的更新公式为:
24、
25、两层lstm叠加后输出层公式为:
26、
27、其中,yn是n个时间bilstm的输出,w为权重,h为偏置,h为隐藏单位的个数,h1为前向更新输出单元值,h2是后向更新输出单元,b为误差值,xn为输入值。
28、进一步的,进行分词效果统计,并进行统计分析,具体为:
29、对电网风险文本分词后,进行分词效果统计,与设定切分模板进行正向匹配,并进行统计分析,检测分词效果;
30、设定切分模板使用seq2seq模型来生成,设定seq2seq模型利用两个rnn网络,一个作为编码部分,另一个作为解码部分。
31、进一步的,双阶段电网风险文本序列分词模型进行权重分配时,具体按照下式进行:
32、
33、其中,b为常数值,xi为电网风险文本样本数据,wi为对应的双阶段网络模型特征的权重,r(xi)为预测样本数据属于所属分词的类别标签为1的类别概率,yi=1表示文本样本数据xi实际属于类别标签1的概率,yi=0表示文本样本数据xi实际属于类别标签0的概率值,α为调制系数。
34、第二方面,本发明提供了一种电网风险文本分词装置,包括:
35、预处理模块,用于获取电网风险中文文本词汇数据;并对电网风险中文文本词汇数据进行多次预处理,以提升后续分词处理的效果;
36、分词模块,用于对预处理后的词汇数据,使用正向模板匹配进行初步分词;还用于根据初步分词后的特征词量,使用thulac中文分词工具,进行二次分词,得到二次分词后特征词量;
37、模型构建模块,用于对一二次分词后的电网风险文本词量,构建rnn循环神经网络文本识别模型;还用于基于rnn循环神经网络文本识别模型搭建深度神经网络bilstm+crf的方法,大规模训练电网风险文本序列分词模型;还用于将训练好的电网风险文本序列分词模型中各个神经网络结构层前加入预训练框模型,并给予相应特征权重分配,构建双阶段电网风险文本序列分词模型;
38、模型训练模块,用于将电网风险文本样本训练数据集对双阶段电网风险文本序列分词模型进行知识蒸馏网络训练;
39、分词模块,用于使用训练好的双阶段电网风险文本序列分词模型进行最终分词处理,得到分词结果;还用于对电网风险文本分词后,进行分词效果统计,并进行统计分析,检测分词效果;还用于输出最终分词结果。
40、进一步的,在模型构建模块中,双阶段电网风险文本序列分词模型进行权重分配时,具体按照下式进行:
41、
42、其中,b为常数值,xi为电网风险文本样本数据,wi为对应的双阶段网络模型特征的权重,r(xi)为预测样本数据属于所属分词的类别标签为1的类别概率,yi=1表示文本样本数据xi实际属于类别标签1的概率,yi=0表示文本样本数据xi实际属于类别标签0的概率值,α为调制系数。
43、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器及存储在存储器上的计算机程序,当计算机程序在处理器上被执行时,实现如第一方面的电网风险文本分词方法。
44、第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器运行时,实现如第一方面的电网风险文本分词方法。
45、综上,本发明提供了一种电网风险文本分词方法和装置,包括获取电网风险中文文本词汇数据;对电网风险中文文本词汇数据进行多次预处理,以提升后续分词处理的效果;对预处理后的词汇数据,使用正向模板匹配进行初步分词;根据初步分词后的特征词量,使用thulac中文分词工具,进行二次分词,得到二次分词后特征词量;对一二次分词后的电网风险文本词量,使用深度学习bilstm+crf的方法,大规模训练电网风险文本序列分词模型并构建双阶段电网风险文本序列分词模型;使用训练后的模型进行最终分词处理,得到分词结果;对电网风险文本分词后,进行分词效果统计,并进行统计分析,检测分词效果。本发明通过上述方法,可以提高电网风险文本分词效率和准确度,并得到良好的文本分词结果。
46、附图
47、为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
48、图1为本发明实施例提供的一种电网风险文本分词方法的流程图;
49、图2为本发明实施例提供的一种计算机设备的结构示意图。
- 还没有人留言评论。精彩留言会获得点赞!