多类型相机下样本不均衡的松林变色异木识别方法与流程
本发明涉及一种图像识别方法,尤其涉及一种多类型相机下样本不均衡的松林变色异木识别方法。
背景技术:
1、松木线虫病会导致大量松树枯死,所以需要对松木线虫病害进行识别。目前采用的方法为:首先通过无人机采集松林视频影像,再对影像进行分析来识别变色异木,是监测松木线虫病害的重要手段。近年来深度学习等人工智能技术被用于变色异木的识别。
2、然而不同厂家、型号的相机,采集到的无人机影像特征差异大,并且所有识别的变色异木呈现的特征差异也大;另一方面在不同条件下,采集到的影像数据也不平衡,如:相机a采集的变色异木占比85%,相机b采集的变色异木占比10%,相机c采集的变色异木占比5%。这些不同类型相机造成的影像特征差异大、变色异木特征差异大,以及不同相机采集的变色异木数据量不均衡等问题为基于深度学习的变色异木识别模型带来了极大的挑战。
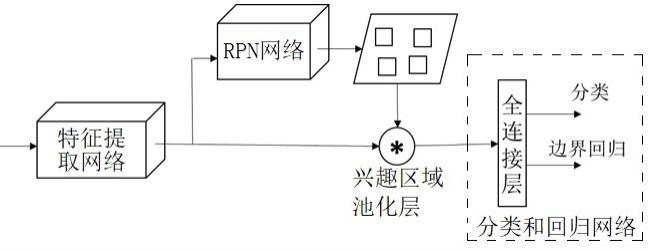
3、目前常用的识别模型为faster r-cnn网络模型。该模型包括四个部分:特征提取网络、rpn网络、兴趣区域池化层、分类和回归网络;图像输入网络之后,(1)先经卷积操作进行特征提取得到特征图,(2)将特征图输入rpn网络,生成目标区域的候选框,(3)由兴趣区域池化单元结合候选框和特征图,从特征图中抠出对应的区域特征,也被称为兴趣区域特征,并转换为某一特定尺寸的特征图,(4)最后由分类和回归网络进行类别计算和候选框微调,输出微调后得到的检测框,和检测框内的目标类别。训练faster r-cnn网络模型时,通常将分类和回归网络的分类损失和边框回归损失之和作为目标函数,以追求分类损失和边框回归损失最小化。
4、由于不同相机差异大、影像数据不平衡,若用不同相机的影像构成单一相机的数据集训练faster r-cnn网络,得到的模型差异大,无法对其他相机的影像进行精确识别。
技术实现思路
1、本发明的目的就在于提供一种解决上述问题,克服不同类型相机采集的影像的特征差异大、导致模型训练不准确等缺陷的,多类型相机下样本不均衡的松林变色异木识别方法。
2、为了实现上述目的,本发明采用的技术方案是这样的:一种多类型相机下样本不均衡的松林变色异木识别方法,包括以下步骤;
3、s1,构建数据集d,包括s11~s14;
4、s11,选取k个不同类型的相机对松林进行拍摄,每个相机每次拍摄得到一松林影像,同一相机的松林影像构成一子数据集;
5、s12,将变色异木作为目标,在松林影像中人工标记目标区域,统计每个子数据集中目标区域面积、所有目标区域面积总和s,并将标记了目标区域的松林影像作为训练样本;
6、s13,计算每个子数据集的占比,对其中一子数据集,其占比=sz÷s×100%,其中,sz为该子数据集的目标区域面积;
7、s14,将子数据集按占比从高到低排序,并依次标记为d1~dk,数据集d={d1,d2 ,…,di,…,dk},di是第i个子数据集,i=1~k;
8、s2,选取faster r-cnn网络,包括特征提取网络、rpn网络、兴趣区域池化层、分类和回归网络;
9、s3,预设迭代次数t、构建训练集x,用训练集训练faster r-cnn网络至收敛,得到目标识别模型;其中第w次训练包括步骤s31~s38,w=1~t;
10、s31,构建训练集x={x1,x2 ,…, xi,…,xk},其中,xi为从di中选取多张训练样本构成的集合,x1~xk中训练样本的占比为d1~dk的占比;
11、s32,将训练集x输入faster r-cnn网络,对训练集x的每个训练样本,由特征提取网络提取特征图,再扁平化处理为d维的向量标记为深度向量;
12、s33,计算训练集x的数据相关性损失lcorr;
13、,
14、式中,j=1~k,且i≠j,xm为xi中的训练样本,xn为xj中的训练样本,ym、yn分别为xm、xn对应的深度向量,d为深度向量的维度,t为转置操作;
15、s34,对每张特征图,经rpn网络对目标区域生成候选框、并由兴趣区域池化层输出兴趣区域特征;
16、s35,把兴趣区域特征扁平化处理为特征向量,将xi对应的所有特征向量构成特征向量集合qi,得到x1~xk对应的特征向量集合q1~qk;
17、计算q2~qk与q1的相似性,其中qi与q1的相似性h(qi|q1)通过下式得到;
18、,
19、,
20、式中,e为自然常数,q为qi中的特征向量,p为q1中的特征向量,v(•|•)为两个特征向量条件协方差计算,k(•,•)为两个特征向量的协方差计算;
21、s36,根据下式计算训练集x的数据相似性损失 l mutual;
22、,
23、s37,将兴趣区域特征送入分类和回归网络,输出候选框及候选框内的目标类别,并计算分类损失 l cls和边框回归损失 l res;
24、s38,设计目标函数 l,并用目标函数 l训练faster r-cnn网络;
25、,
26、其中, a1 、a2 、a3分别为 l cls+ l res、 l corr、l mutual的权重;
27、s4,用目标识别模型进行目标识别;
28、用k类相机中任一相机对松林进行拍摄,得到待识别松林影像,送入目标识别模型,输出其中的变色异木区域。
29、作为优选:每次训练时构建的训练集x都不同,由随机抽取的训练样本构成。
30、作为优选:s38中, a1=1、 a3=0.5,, a为 a2的权函数变量, a=0.5。
31、作为优选:所述分类损失 l cls根据下式得到;
32、,
33、式中, n为候选框总数, f为第 f个候选框, f=1~ n, c f为第 f个候选框的类别标签,取值为0或1,其中0为目标,1为背景, p f为第 f个候选框为目标的预测概率,log(·)为log函数。
34、作为优选:所述边框回归损失 l res通过下式得到;
35、,
36、式中, n为候选框总数, f为第 f个候选框, f=1~ n;
37、 d xf、 d yf、 d wf、 d hf分别表示对第 f个候选框预测的 x坐标、 y坐标、宽度和高度, t xf、 t yf、 t wf、 t hf分别表示第 f个候选框真实的 x坐标、 y坐标、宽度和高度, smooth l1(·)为平滑l1函数,根据下式得到,,uv为 smooth l1(·)中的变量。
38、本发明的思路为:
39、首先,将不同相机对应的子数据集,按变色异木区域面积多少计算占比并排序,变色异木区域面积最大的子数据集为d1,其余按降序依次为d2~ dk,从而得到各子数据集的占比和顺序。
40、第二:每次训练时,随机按占比从d1~dk中抽取训练数据构成x1~ xk,再针对不同类型相机采集的松林影像的特征差异大的特点,提出一种特征相关性的计算方法,通过步骤s33提高不同类型相机采集的松林影像之间的特征相关性,使得后续的变色异木的检测能够在高度相关的特征下进行。
41、第三针对不同相机采集的变色木区域数量不均衡的问题,本发明以占比最多的子数据集d1对应的相机采集的变色异木为中心,使占比小的相机采集到的变色异木的特征尽量与其相似。
42、本发明设计数据相关性损失lcorr的目的是提升最终训练出来的模型检测来自不同类型的相机拍摄的图像的检测性能。
43、本发明设计数据相似性损失lmutual的目的是提升最终训练出来的模型检测不同相机采集的数量不均衡的图像的检测性能。
44、与现有技术相比,本发明的优点在于:
45、(1)在处理不同相机产生的影像特征差异、松林变色异木特征和不同相机采集样本量不同问题上,未增加检测模型中的参数。
46、(2)以大比例变色异木区域特征为中心,使小比例变色异木区域与其相似,在解决不平衡问题和变色异木区域特征差异大的问题时,首先确保了大比例变色异木区域的识别准确性。
47、(3)在学习过程的不同阶段解决问题的侧重不同,早期注重解决特征差异大,后期注重检测问题,使得学习更加有效。
48、(4)对分类损失 l cls进行了改进,分类损失采用交叉熵损失函,它是连续可导的凸函数,这使得训练过程变得更加高效和稳定,提高了松林变色异木识别模型的训练效率。并且交叉熵损失函数可以方便地与其他损失函数进行组合使用,在松林变色异木识别中,需要同时考虑目标的位置和类别信息,因此通过将交叉熵损失函数与回归损失函数结合起来,构建一个综合的损失函数来同时优化目标的位置和类别预测,提高了松林变色异木模型的优化效率。
49、(5)对边框回归损失 l res进行了改进,在边框回归损失 l res中使用了平滑l1损失,这是因为,在松林变色异木识别任务中,由于目标位置可能存在噪声或者不准确的标注,使用常用的均方误差损失会对异常值非常敏感。而平滑l1损失通过引入了一个平滑因子,可以减少异常值的影响,提高了松林变色异木识别模型的鲁棒性。缺省框处理:在目标检测任务中,通常需要预测目标的位置,包括边界框的坐标。平滑l1损失能够有效地应对预定义边界框的处理,使得模型对变色异木位置的预测更加准确。
- 还没有人留言评论。精彩留言会获得点赞!