一种新的基于语句语义相似度的网络新词发现方法
本发明涉及自然语言处理领域,更具体的说是涉及一种新的基于语句语义相似度的网络新词发现方法。
背景技术:
1、新词发现是自然语言处理中亟待解决的关键问题,目前已有许多研究者对这一问题进行了研究。kit等人为法律的领域提出了一个法律的术语识别。他们在语料库比较框架内调查了一些词项统计指标的表现。这些度量是根据领域和上下文语料库中候选术语的频率、信息和排名来定义的。他们在实验中使用了一个背景语料库来识别中国香港地区法律的文本中的法律的术语,并验证了增强的基于秩和信息的度量在识别真实术语方面的出色性能。tan chade-meng et al提出了一种使用信息增益度量,结合各种频率阈值的算法。然后将二元语法沿着一元语法作为特征提供给朴素贝叶斯分类器。该算法在正确分类更多积极文档方面最为成功,但可能导致更多消极文档被错误分类。yang等人提出了一种基于n-gram方法的无监督新词发现方法。他的研究使用词嵌入将词嵌入到向量空间中,并将语料库中的某些元素联合收割机组合起来,形成新词的候选词。通过去除噪声来判断词的相似性,形成新的词向量。
技术实现思路
1、有鉴于此,本发明提供了一种新的基于语句语义相似度的网络新词发现方法,以解决新词发现和对新词理解的问题,便于人们更好地理解社交网络中用户生成的内容,包括新词的使用和其语义关联性。这对于理解网络上的社交趋势、舆情分析、广告定位和用户行为研究等方面具有重要意义。
2、为了实现上述目的,本发明采用如下技术方案:一种新的基于语句语义相似度的网络新词发现方法,具体步骤包括如下:
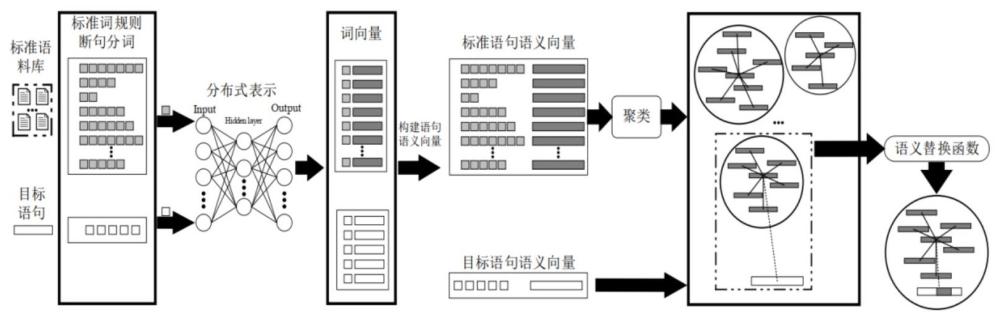
3、通过基于语句语义相似度的网络新词发现过程图和语义替换函数求解过程图;
4、数据收集与预处理: 方法首先收集包含网络新词的语句数据,同时准备标准语料库数据。这些数据经过预处理,包括分词、去除停用词,以便后续分析。
5、分词表示模块: 对标准语料库和目标语句中的文本进行分词。
6、语句语义向量生成模块: 利用tf-idf加权平均法生成语句语义向量,将标准语句和目标语句的文本向量化。
7、标准语句语义向量聚类: 利用k-means聚类算法将标准语句语义向量聚类成不同的语句语义簇,并得到每个簇的中心。
8、备选语句确定: 根据目标语句,找到与其语义最接近的标准语句作为备选语句,以备用于网络新词的发现。
9、基于词序列映射的网络新词发现: 对备选语句和目标语句中的词语序列进行匹配,以发现网络新词。这一步骤包括将备选词汇子序列与目标词汇子序列进行比对,找到语义相似的词语,进一步验证并发现网络新词。
10、语义替换函数集f: 这是一系列语义替换函数,用于将备选词汇子序列与目标词汇子序列进行语义替换,以获得最接近标准语句簇中心的语句。
11、网络新词发现与标准词义解释: 最终,通过计算语句的语义相似度和语义替换,方法能够发现网络新词,同时为这些新词提供标准的词义解释。
12、进一步地,所述语句语义向量的生成方式利用tf-idf加权平均法,对于一个词语来说,其中tf-idf值为:,利用每个词的 tf-idf 值按以下方式构建语句语义向量: 。
13、进一步地,所述标准语句语义向量聚类,利用如下模型求出与 st 最近的语句语义簇中心mp及对应的簇cp,即为:。
14、进一步地所述备选语句确定,即为:。
15、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种新的基于语句语义相似度的网络新词发现方法,本发明的有益效果为:
16、本发明针对新词发现和新词解释问题,提出一种新的基于语句语义相似度的网络新词发现方法。该方法结合词嵌入和聚类方法,并利用句子语义向量的相似度来确定句子之间的语义关系,能够有效地从网络文本中发现网络新词。
17、本发明以语句语义向量为基础,进行新词发现,更有利于纳入考虑词语的语义信息,相较于现有的新词发现方法而言,具有更为准确且更为合乎现实语义的新词确定。
18、本发明所提出的一种新的基于语句语义相似度的网络新词发现方法在发现网络新词的同时,也提供了网络新词在标准词库中最为接近的标准语义解释,对 nlp 的各项任务如进行词性判断、情感判断等提供了更为优异的数据基础。
技术特征:
1.一种新的基于语句语义相似度的网络新词发现方法,其特征在于,具体步骤包括如下:
2. 根据权利要求1所述的语句语义相似度的网络新词发现方法,其特征在于,所述语句语义向量的生成方式利用tf-idf加权平均法,对于一个词语来说,其中tf-idf值为:,利用每个词的 tf-idf 值按以下方式构建语句语义向量:。
3.根据权利要求1所述的语句语义相似度的网络新词发现方法,其特征在于,所述标准语句语义向量聚类,利用如下模型求出与st最近的语句语义簇中心mp及对应的簇cp,即为:。
4.根据权利要求1所述的语句语义相似度的网络新词发现方法,其特征在于,所述备选语句确定,即为:。
技术总结
本发明公开了一种新的基于语句语义相似度的网络新词发现方法,涉及社交媒体分析领域。该方法主要包括分词表示模块、语句语义向量生成模块与新词发现模块三部分组成。包括以下步骤:首先,构建标准语料库,其中包括各种文本文档,用作方法的参考数据。接下来,收集包含网络新词的目标语句,对这些语句进行文本预处理,包括分句、分词、去除停用词等操作。然后,使用文本中的词语构建语句的语义向量。随后,通过聚类算法对语句的语义向量进行聚类操作,将语义相似的语句聚集在一起形成不同的语义簇。从标准语料库中选择与目标语句语义最接近的备选语句,然后,采用备选语句中的词语替换目标语句中相应的词语,形成不同版本的目标语句。通过比较替换后的目标语句与语义簇中心的语义相似度,确定目标语句中是否存在新词。如果替换后的语句更相似于某一语义簇中心,那么这部分替换即为新词。最后,对于发现的网络新词,方法可以提供对应的标准词义解释,即网络新词的标准定义。这个流程允许在语义相似度的基础上识别网络新词,提高自然语言处理和文本分析的效率。
技术研发人员:马跃峰,于淦峰,宋杨,刘智斌,王心水
受保护的技术使用者:曲阜师范大学
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!