基于文件同步运行数据至时序库的方法、存储介质及设备与流程
本发明属于云网数字孪生,具体地,涉及一种基于文件同步运行数据至时序库的方法、存储介质及设备。
背景技术:
1、存储海量数据及其引发的性能压力的应对策略一直受到全球广泛关注。当这一问题刚刚出现时,一种常见的处理方式是忽略某些数据源或舍弃部分采集到数据。然而,这种处理方式仅在短期内有效,对于存储几年甚至几个月前的数据尤为不足。随着数据的价值逐渐被认可,并已经超越了传统企业广泛认同的价值边界,数据作为一种宝贵的无形资产,正在逐步取代传统有形资产的地位。这使得人们意识到,通过丢弃数据来降低存储与i/o压力是一种非常不明智的选择。
2、关系数据库集群是一种针对大规模数据存储和高并发读写问题的解决方案,通过集群化单机的硬件性能限制。利用不同的服务器来处理读请求和写请求,实现读写分离,有效减轻了高并发条件下数据库的读写压力。然而,关系数据库集群并不是一个完全完美的解决方案,用户首先需要面对扩容困难这一问题。在向集群中新增一个数据库节点时,意味着需要进行重新分区与数据迁移,这些操作会耗费大量的i/o资源,并且在操作执行的过程中,整个集群的性能也将受到非常大的影响。另外,一些限制来自关系型数据库设计本身的制约。使用范式来约束数据模型的设计以减少数据冗余,但范式化的处理却导致查询过程中涉及到非常多的连接join操作,引起查询性能的下降,尤其是在分布式环境中,join操作还会产生大量的额外网络开销。
3、在云计算环境中,数据中心的核心组成部分通常包括大量的硬件和软件资源,这些资源之间相互作用,共同形成了一个复杂的服务提供系统。这种系统的动态特性和相互依赖性往往给预测和管理其行为带来了挑战。为确保服务提供的可靠性和质量,必须实施一种有效的监控策略。然而,传统的集中式监控策略往往缺乏扩展性和实时性,无法满足现代数据中心的需求。特别是,这种集中式监控系统在处理巨大的数据流时可能会遇到瓶颈,无法在秒级级别执行实时监控任务。有必要开发一种全新的监控架构体系,这种体系应能实时或准实时地监测这些资源的状态和性能,并能灵活扩展以适应不断变化的数据负载。因此,构建一个能够满足这些需求的监控架构体系,对于确保云计算数据中心的稳定运行和优质服务至关重要。
技术实现思路
1、针对现有技术中存在的问题,本发明提供了一种基于文件同步运行数据至时序库的方法、存储介质及设备,实现历史文件数据查询和监测。
2、为实现上述技术目的,本发明采用如下技术方案:一种基于文件同步运行数据至时序库的方法,具体包括如下步骤:
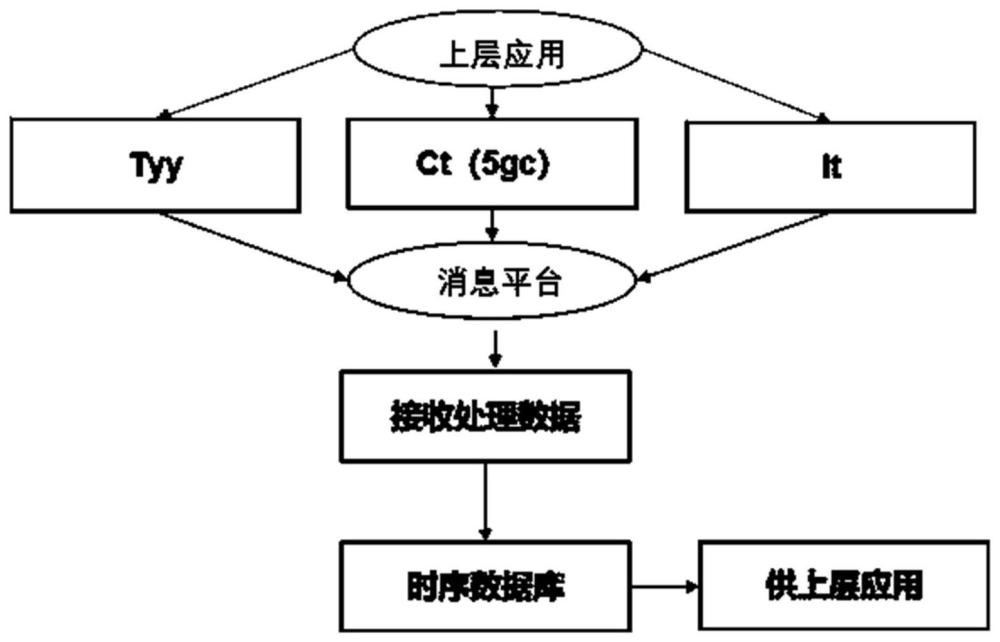
3、步骤1、上层应用将待同步数据的文件放置在指定的文件目录中,并发送kafka消息到资享平台,所述资享平台根据kafka消息获取待同步数据的文件;
4、步骤2、所述资享平台收到待同步数据的文件后,解析待同步数据的文件内容,并根据配置文件获取入时序数据库的参数信息,进行模转入时序数据库;
5、步骤3、根据实际功能需要对时序数据库中的数据进行定时数据汇聚,提供上层应用的数据查询。
6、进一步地,步骤1包括如下子步骤:
7、步骤101、上层应用将待同步数据的文件生成json或者文件数据后,推送至所述上层应用的服务器指定的文件目录下;
8、步骤102、通过kafka消息平台将对应的kafka消息推送至资享平台,所述资享平台通过监听对应消费组,获取待同步数据的文件的文件目录路径及类型。
9、进一步地,所述消费组将消费者提交偏移量修改为自动提交,并且所述资享平台通过多线程池获取待同步的文件的文件目录路径及类型。
10、进一步地,步骤2包括如下子步骤:
11、步骤201、资享平台收到待同步数据的文件后,解析其对应性能文件的内容、文件类型和所属云系统;
12、步骤202、设置服务模板,根据解析的性能文件将要入时序数据库的指标和标签动态化配置到服务模板中;
13、步骤203、将对应的指标和标签作为查询条件配置到时序数据库中,并将待同步数据的文件推送至资享平台的时间作为入时序数据库的时间戳,通过api命令将同步数据的文件写入时序数据库。
14、进一步地,步骤3中数据查询的过程为:构建查询条件,根据查询条件调用时序数据库的查询api,生成数据;所述查询条件包括:指定符合实际功能需要的开始结束时间、tags、metric和聚合查询条件。
15、进一步地,步骤3进行数据查询后,通过前端可视化页面呈现,分析出异常数据,实现实时监控告警。
16、进一步地,本发明还提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序使计算机执行所述的基于文件同步运行数据至时序库的方法。
17、进一步地,本发明还提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时,实现所述的基于文件同步运行数据至时序库的方法。
18、与现有技术相比,本发明具有如下有益效果:本发明基于文件同步运行数据至时序库的方法,上层应用将数据发送至kafka消息平台,kafka具有非常高的吞吐量和低延迟,可以轻松处理每秒数百万条消息,同时本方法采用多线程接收消息,保证收到消息后就能被消费,从而实现数据从文件同步到时序数据库是实时的,可以确保数据同步的及时性和准确性;之前为了存储不同云的资源数据,都需要单独开发针对某一个系统提供的数据,不具有灵活性,而本发明可以轻松地适应不同格式和结构的数据文件,使用灵活的数据解析将其转换为时序数据库所需的格式,以最小的工作量实现不同类别云资源数据的存储,同时根据实际功能需要进行定时数据汇聚,提供上层应用数据查询能力;此外,通过kafka消息实现数据的传输,使得不同系统的资源数据通过配置能够定制化存储,有效地扩大了监控范围和容量;通过时序数据库来存储不同云资源性能指标数据,通过前端展示组件实现指标数据的图表展示,有效解决了性能数据实时监测和历史数据查询的可视化监控需求。
技术特征:
1.一种基于文件同步运行数据至时序库的方法,其特征在于,具体包括如下步骤:
2.根据权利要求1所述的一种基于文件同步运行数据至时序库的方法,其特征在于,步骤1包括如下子步骤:
3.根据权利要求2所述的一种基于文件同步运行数据至时序库的方法,其特征在于,所述消费组将消费者提交偏移量修改为自动提交,并且所述资享平台通过多线程池获取待同步的文件的文件目录路径及类型。
4.根据权利要求1所述的一种基于文件同步运行数据至时序库的方法,其特征在于,步骤2包括如下子步骤:
5.根据权利要求1所述的一种基于文件同步运行数据至时序库的方法,其特征在于,步骤3中数据查询的过程为:构建查询条件,根据查询条件调用时序数据库的查询api,生成数据;所述查询条件包括:指定符合实际功能需要的开始结束时间、tags、metric和聚合查询条件。
6.根据权利要求1所述的一种基于文件同步运行数据至时序库的方法,其特征在于,步骤3进行数据查询后,通过前端可视化页面呈现,分析出异常数据,实现实时监控告警。
7.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序使计算机执行如权利要求1-6任一项所述的基于文件同步运行数据至时序库的方法。
8.一种电子设备,其特征在于,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时,实现如权利要求1-6任一项所述的基于文件同步运行数据至时序库的方法。
技术总结
本发明公开了一种基于文件同步运行数据至时序库的方法、存储介质及设备,包括:上层应用将待同步数据的文件放置在指定的文件目录中,并发送kafka消息到资享平台,所述资享平台根据kafka消息获取待同步数据的文件;所述资享平台收到待同步数据的文件后,解析待同步数据的文件内容,并根据配置文件获取入时序数据库的参数信息,进行模转入时序数据库;根据实际功能需要对时序数据库中的数据进行定时数据汇聚,提供上层应用的数据查询。本发明将数据从文件同步到时序数据库是实时的,可以确保数据同步的及时性和准确性。
技术研发人员:赵聪聪,李志辉,党咏欣,晏进,宋小龙,刘如梦
受保护的技术使用者:中电信数智科技有限公司
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!